
KDDI、沖縄セルラーは22日、同社の4G LTEスマートフォン・タブレットにデータ容量をチャージできる「データチャージカード」の販売を開始した。全国のauショップから購入可能で価格は1,620円から。「データチャージカード」は1.5GB(1,620円)/3GB(3,240円)/5GB(,5400円)の3種類が用意されている。カード背面のQRコードもしくはPINコードを専用アプリ「デジラアプリ」で読み取りもしくは入力するか、「データチャージサイト」でPINコードを入力することでチャージできる。auショップでの販売を記念して、「データチャージカード」でチャージすると、データ容量が50%増量されるキャンペーンも実施する。期間は3月22日から4月30日まで。また、auショップでは、全国のスーパーやコンビニなどで利用できる「au WALLET プリペイドカード」へ入金できる「au WALLET チャージカード」の販売も開始する。こちらは1,000円/3,000円/5,000円の3種類。
2016年03月28日
IDCフロンティア(IDCF)とヤフーは3月25日、大規模データセンターである福岡県北九州市の「北九州データセンター」と、福島県白河市の「白河データセンター」にそれぞれ新棟を建設することを発表した。建設規模は「北九州データセンター」が1棟約610ラック規模、「白河データセンター」が1棟70ラック・全6棟で構成される計420ラック規模となり、工期は「北九州データセンター」が2016年2月から12月中旬の約11カ月、「白河データセンター」は同年4月末から10月末の約6カ月を予定している。「北九州データセンター」の新棟となる6号棟は、ヤフーとIDCFのクラウドサービスおよび外販での利用を予定しているという。同センターは西日本地域におけるクラウドサービスの提供拠点であり、外販のハウジングサービスなどにおいては東京・大阪に集中するシステムの地理的分散や電力供給会社の分散により事業の継続や災害対策に機能を発揮している。将来は最大11棟までの増設が可能であり、拡張余力をシステム選定の条件とした企業の大規模需要にも応えるとしている。空調方式は、1~5号棟では直接外気空調が取り入れられていたが、6号棟に関しては、水冷空調システムが導入される予定となっている。「白河データセンター」の新棟となる4号棟は、2016年3月に第1期分が竣工した3号棟に引き続きヤフー向けに増設され、増加を続けるデータの格納や、ヤフーが保有するマルチビッグデータを活用するための処理基盤強化が目的だとしている。
2016年03月25日
AOSデータは23日、マイナンバー対策製品の販売において明光商会と業務提携を行うことを発表した。AOSデータは、マイナンバーに対策に対応するソフトとして電子データシュレッダーを販売している。同ソフトは、グループ会社でありフォレンジック分野などにも強いAOSリーガルテックが開発しているソフトウェアで、PC上のデータを復元できない状態に廃棄・削除を行う。マイナンバーが記載されたメールを消去するメール抹消機能やあらかじめ設定した日時に自動で行えるスケジュール抹消機能なども搭載されているほか、いつ、誰が、何のファイルを抹消したのかを記録に残すレポート機能も備える。明光商会は、1960年という古くからMSシュレッダーを世に送り出してきた実績を持ち、オフィスユースを中心に個人認証型のシュレッダーから大量の機密文書の細断を行う破砕機まで、ニーズに応じたシュレッダーのラインナップを揃える。今回、明光商会が「電子データシュレッダー」の販売で提携、紙/デジタルともに徹底したデータ抹消が可能になる。なお、明光商会配布のカタログからの申し込み限定で同ソフトの60日間無料の体験版が利用できる。
2016年03月23日
ビッグローブは17日、「BIGLOBE SIM」ユーザーを対象に、NTTドコモが提供する「dマーケット」の一部サービスの販売を開始した。ビッグローブが取り扱うのは、映画やドラマが見放題の「dTV」(月額500円)、音楽が聴き放題の「dヒッツ」(月額500円)、雑誌が読み放題の「dマガジン」(月額400円)。BIGLOBEのWebサイトからdアカウントを取得することでスマートフォン、タブレット、PCから利用できる。なお、利用料の支払いはクレジットカードのみとなっている。
2016年03月17日
アイ・オー・データ機器は16日、データ復旧サービスが付属する外付けHDD「HDJA-UTWHQシリーズ」を発表した。容量2TBの「HDJA-UT2.0WHQ」と3TBの「HDJA-UT3.0WHQ」をそろえ、いずれも3月末に出荷する。価格は2TBモデル「HDJA-UT2.0WHQ」が税別29,900円、3TBモデル「HDJA-UT3.0WHQ」が税別34,400円。熱や振動に強いとされるウエスタンデジタル製のNAS用HDD「WD Red」を搭載するほか、独自のヒートシンク構造と冷却用ファンで冷却性能を高め、HDDの温度上昇などによる故障のリスクを低減する。付属のデータ復旧サービスは、ミスやウイルス感染によってデータが消失してしまったり、故障などによってデータ障害を起こした時に復旧をサポート。3年の保障期間保証期間内に1回のみ無料で利用で、申し込む際に購入日を証明するレシートなどが必要となる。このほか、同社のWebサイトから、ファイルの同期やアクセスの高速化などを行うことができるツール群「IO.APPs」も無料ダウンロード可能。インタフェースは、USB 3.0。電源はAC100Vで、電源ユニットを本体に内蔵するため、ACアダプタを必要としない。また、PCとの電源連動機能を備える。本体サイズは約W45×D216×H155mm、重量は約1.2kg。対応OSは、Windows Vista / 7 / RT / RT 8.1 / 8 / 8.1 / 10。Windows Server 2008 / 2008 R2 / 2012 / 2012 R2。Mac OS X 10.7~10.11。
2016年03月17日
EaseUS Softwareは3月11日、Windows 10へのアップデート時にデータを損失してしまっても、安全にデータを復元、バックアップできるソフト「Data Recovery Wizard」と「Todo Backup」の最新バージョンを提供すると発表した。Windows 10へのアップデート時、ユーザーによる設定や各ソフトやアプリ、データはそのまま残るが、アップデート時にエラーが起こるとシステム上の全データが損失・消失してしまうリスクがあり、こうしたケースを防ぐためには、事前にバックアップをとっておく必要があるという。最新バージョン「Data Recovery Wizard 9.9」を利用することで、アップデート前のバックアップを容易に実行でき、Windows 10へのアップデート時に万一、データの損失や消失してしまっても、バックアップがあれば短時間かつ簡単にすべてのデータを復元、アップデート時のエラーでシステムからの起動ができなくてもすべてのデータ復元ができるとしている。アップデート時のデータ損失・消失からの復元だけでなく、システムをはじめHDD、パーティションも含めたバックアップに適しているのが「Todo Backup 9.1」。PCやHDD、外付けHDD上の全データのバックアップが可能なほか、増分や差分、自動バックアップ機能を備え、さらにクラウドバックアップ機能を使うことにより、Google Drive、OneDrive、Dropboxなどクラウド上に保存してあるすべてのデータも安全かつ便利にバックアップすることができるという。
2016年03月14日
エンタープライズデータストレージ・ソリューションのプロバイダであるイスラエルのINFINIDATは3月8日、日本法人としてインフィニダット ジャパン合同会社(インフィニダット)を設立した。INFINIDATはモシェ・ヤナイ氏が2011年に設立し、2013年末にInfiniBoxの出荷を開始。これまでグローバルで主要企業のデータセンターに導入されており、投資機関のTPG GrowthとMIIVenturesから資金提供を受けている。ユーザーには金融や銀行、政府機関、ヘルスケア、エネルギー、クラウドサービスなど多様な分野のFortune 500企業が含まれているという。インフィニダットは、実証済みのエンタープライズデータストレージ・ソリューション「InfiniBox」を日本および周辺地域の企業に提供する。カントリーマネージャには岡田卓也氏が就任した。InfiniBoxは、19インチ/42Uのシングルラックで最大2PBまでの容量を使用可能であり、99.99999%の可用性、100万IOPS以上、最大12.5GB/sというスループットを実現しているという。エンドツーエンドのデータ保護、三重化冗長電源/データパス、スナップショットとレプリケーション、ホットスワップアップグレードなどを有する。こうしたストレージ性能/効率化機能により、InfiniBoxはユーザーのTCO削減を実現するとしている。
2016年03月08日
米Lookoutは2月29日、プライバシー・データ保護調査を行う「Ponemon Institute」と共同で行った調査「モバイル端末からの機密データ漏えいにおける経済的リスク」の結果を公開した。同調査は、Forbesが発表する世界の公開企業上位2000のランキングリスト「Global2000」におけるIT・ITセキュリティ分野の従業員588名を対象に行っており、モバイル端末で企業情報にアクセスする際のリスクを検証して、実際にモバイルマルウェアが偉業に与える損失を測定している。これによると、モバイルマルウェアに感染した場合、感染端末すべての調査・復旧の直接費用や、コンプライアンス違反、信用喪失などの間接費用をあわせた総コストが、感染端末一台あたり「106万2320円(9485ドル)」にのぼることがわかった。なお、調査対象となった企業で利用されているモバイル端末のうち、3%(1700台)以上がマルウェアに感染している可能性があるという。こうした状況ではデータのアクセス権限管理が重要となるが、セキュリティ担当者の過半数が「社員のデータアクセスについて適切に把握している」と回答する一方で実態は大きく異なるとLookoutは指摘。例えば、顧客データへのアクセスは19%の担当者だけが「アクセスできる」と考えているのに対し、実際にアクセスしている従業員は43%にのぼった。ほかにも「個人の特定が可能な社員情報」や「連絡先リスト・名簿」「機密・極秘文書」など、従業員がセキュリティ担当者の監視の目をかいくぐり、データを利用している実態がわかった。こうした状況から、調査対象となった企業のITセキュリティ年間予算は現状が2730万ドルであるのに対し、12カ月後は3276万ドルと予算が増加傾向にある。また、モバイルセキュリティ分野においても436万8000ドルから598万4160ドルへと、各企業が予算増の見通しを立てていることが明らかとなっている。
2016年03月01日
ウイングアーク1stは2月17日、NECと大規模データにおけるデータ分析基盤の協業を強化し、製造業におけるセンサーデータ収集による故障の未然防止や、金融業における取引の異常監視をはじめ、大容量のデータを蓄積できるデータ分析環境の構築を支援すると発表した。両社は、2014年2月からNECのIAサーバ「Express5800」、ストレージ「iStorage Mシリーズ」とウイングアーク1stのBI・情報活用基盤「Dr.Sum EA」を組み合わせ販売。あわせて共同で性能検証を行い、従業員数20,000名以上の大規模ユーザーや100億件以上の大容量データを保持したユーザーに最適なパフォーマンスを実現できることを検証してきた。今回新たに数億~数百億件のデータ分析を想定した性能検証を実施し、従来比で数倍~数10倍の集計スピードにおける性能向上を確認できたことから、製造業におけるセンサーデータ収集による故障の未然防止、金融業における取引の異常監視などの大規模データにおける展開を本格化。各種センサー等で収集されるライフログ分析の実証実験に着手し、ビッグデータ分析の実用化に向けた取り組みをスタートする。また両社は、今回の発表に伴い大規模データ分析のトライアルユーザーを限定募集。ハードやソフトの費用を無償で提供する(別途構築費用が発生する場合もある)。
2016年02月17日
富士通は2月17日、ビッグデータの分析サービス「FUJITSU Intelligent Data Service データキュレーションサービス」(以下、データキュレーションサービス)を拡充し、教育サービス「ビッグデータ活用実践講座」「ビッグデータ分析体験ワークショップ」の2つの講座を同日より提供すると発表した。「ビッグデータ活用実践講座」は、企業内でビッグデータ活用を推進・運用できる人材を育成したい企業向けに、業務データの規模や目指すデータサイエンティスト像に合わせてカスタマイズした標準8週間の教育サービス。事業所内の環境で、実際の業務データを教材として使用し、目標設定・データ可視化・加工・モデリングなどの一連のプロセスを学習する。これにより、企業の業務に基づいた、より実践的な分析スキルを持つデータサイエンティストを育成できるという。一方、「ビッグデータ分析体験ワークショップ」は、ビッグデータの活用を検討中の企業向けに、ビッグデータ分析を1日体験できる教育サービス。ワークショップ後には、キュレーターとの個別相談会を開催し、データ活用に関する具体的な取り組みについて提案する。いずれのサービスも価格は個別見積もり。
2016年02月17日
富士通は2月4日、同社のビッグデータの分析サービス「FUJITSU Intelligent Data Service データサービス「FUJITSU Intelligent Data Service データキュレーションサービス」(以下、データキュレーションサービス)において、新たな分析手法としてDeep Learningを適用し、同日より提供すると発表した。このサービスは、新ビジネスの創出や業務改革に向けて、自社で保有する画像や音声などのデータを有効活用したい顧客向けに、専門スキルを持つキュレーター(データサイエンティスト)がデータを分析し、Deep Learningを導入した場合の効果を検証するサービス。Deep Learningは、膨大なデータを機械(コンピュータ)が学習し人の判断や知識創造を助ける機械学習手法の1つ。顧客がこのサービスを活用することで、自社で分析を行うのに比べ初期投資を抑えながら短期間で検証することが可能になるという。Deep Learningを活用した「データキュレーションサービス」では、同社キュレーターが、顧客の画像・音声などのデータを預かり、目的に合わせた効果検証のフレームワークを適用。Deep Learningを用いて約2カ月でデータ分析モデルの作成と評価を行い、結果をレポートする。さらに、本サービスで作成したデータ分析モデルをビジネスに活用したい顧客には、分析モデルの提供や活用のためのコンサルティング、システム構築なども行っていくという。同社はこれまでの「データキュレーションサービス」で行っていた、機器のログや顧客・商品情報など発生した情報の分析による予測モデルの提供に加え、今回、画像や音声などのデータにDeep Learningを適用した学習・認識モデルを提供することで、ヒトの五感に対応したより精度の高いサービス開発や業務改革を支援していくという。なお同社は、コスメ・美容情報サイト「Hapicana(ハピカナ)」を運営するクーシーと連携し、新サービス開発に向けた共同プロジェクトを開始した。プロジェクトでは、顔画像データ5万点にDeep Learningを適用し顔を構成する各パーツの特徴を検出・学習することで、新たなレコメンドサービスの開発につなげていくという。
2016年02月04日
IDC Japanは2月3日、国内ビッグデータソリューション市場動向の調査結果を発表した。同社は、ビッグデータ関連のテクノロジーは従来のBA(Business Analytics)のような単純なレポーティング/予測にとどまらず、リアルタイム処理を内包したアプリケーション基盤となることで、直接的に企業の収益に貢献することが期待されているが、ユーザー層の拡大という面で課題を抱えていると指摘している。その一方で、同社は業務/業種特化型のビッグデータソリューションが今後の国内ビッグデータテクノロジー/サービス市場の成長に重要な役割を果たすと見ている。国内は北米などのビッグデータ活用の先進地域に比べてビッグデータ活用やアプリケーション開発に対応した組織や人的資源を十分に持たない企業が多いため、ベンダーやSIerの提供するビッグデータソリューションの役割はきわめて重要であるという。同調査では、ユーザー企業にベンダー/SIerを挙げて、ビッグデータソリューションの提供者として強いイメージを持つ企業を聞いた。その結果、最も印象に残るベンダーとして、国内企業では富士通がトップの10.6%、NTTデータが2位で8.5%の回答を得。海外企業ではグーグルが9.3%、IBMが7.1%で続いている。同社は、富士通がトップとなった要因について、ミドルウェアやクラウドサービスも含めて独自の製品を持ち、ビッグデータイニシアティブとして包括的なソリューション体系をアピールしているためと分析している。
2016年02月04日
NTTデータは2月1日、同社のデータセンターとアマゾンウェブサービス(AWS)やMicrosoft Azure(Azure)を専用線で直接接続する「マルチクラウド接続サービス」を同日より提供開始すると発表した。同社では、同社のデータセンターとAWSやAzureの間を専用線で接続し「マルチクラウド接続サービス」として同サービスを提供することで、安全性や信頼性を担保しつつ、複数のクラウドサービスや自社システムを連携させるハイブリッドクラウドやマルチクラウドを利用したいという企業のニーズに応えるとしている。同サービスでは、複数の異なるキャリア回線、ネットワーク機器を物理的に冗長化することにより、可用性の高いネットワーク環境を利用できるようになった。また、システムごとにAWSやAzureのアクセスポイントにおいて、ユーザー自身で回線の手配や追加ラック契約など追加設備の用意が不要なため、低価格でサービスを利用することが可能だ(最高速度1Gbpsまで対応)。同社は今後、顧客企業の事業パートナーとして、複数のクラウド基盤の最適化や運用管理を支援する新サービスの提供を計画中であり、順次発表していく計画。
2016年02月02日
●複雑化するデータをデジタルマーケティングにどう活用するか2015年のデジタルマーケティングをめぐる動きを振り返ると、ユーザーの行動履歴をはじめとするデータの利活用は当たり前になり、スマートデバイスの普及により時間や位置情報といったデータを活用したO2Oの展開も活発になってきた。一方、テクノロジーの分野ではIoT(Internet of Things:モノのインターネット)への注目が高まり、今年は一層技術の進化が期待できるところだ。こうした動きを踏まえ、2016年のデジタルマーケティングはどうなっていくのか。その展望について、デジタル・アドバタイジング・コンソーシアム株式会社(DAC)プロダクト開発本部広告技術研究室長の永松範之氏にお話を伺った。――2015年は、アドテクノロジーにおいて一層「データドリブン」の必要性が高まったのではないでしょうか。この動きは今後どうなっていくと感じていますか?永松氏:私たち広告技術研究室では「テクノロジー」、「メディア/コンテンツ」、課金や効果指標、取引手法といった「メソッド」、そして「データ活用」という4つの領域で研究を行っていますが、近年はそれぞれの領域が複雑に絡み合い、融合してきていると感じています。データの領域について、私たちが注目しているのはロケーションデータの活用です。これまでもロケーションデータはターゲティングの手段として使われてきましたが、それに加えてスマートフォンのGPS機能によってデータが収集しやすい環境が整い、またPOI(Point Of Interest)のデータが整備されてきたことによって、「どの位置にどのような関心を持ったユーザーがいるのか」ということが見えてくるようになりました。つまり、ユーザーのロケーションデータとPOIデータを組み合わせることで、より精度の高いプロファイリングができるようになったのです。さらに、オンラインの行動履歴とリアルな位置情報を組み合わせることで、より深いターゲティングもできるようになります。――アドテクノロジーの最大の関心は「どこに潜在顧客がいるのか」ということであり、それを探すための技術ということが求められています。ロケーションデータとPOIデータの組み合わせはその答えのひとつということでしょうか?永松氏:そうですね。今のアドテクノロジーではあくまでもオンラインにおける行動をベースとしたデータの活用が盛んに行われていますが、今後はこれにリアルなロケーションデータを加えることで、よりユーザーの興味関心に応えるアプローチが可能になるのではないでしょうか。PCとモバイルといったクロスデバイスの利用シーンで、複数のデバイスを横断するユーザーに対して広告配信を最適化させる仕組みも、今年は活用していきたいと考えています。――「潜在顧客を探す」という点では、CRM=既存顧客データの活用も昨年から注目されてきています。永松氏:アドテクノロジーとマーケティングテクノロジーの融合、つまり顧客データをはじめとする企業が保有するアセットとの融合もひとつの大きなテーマですね。私たちでも、いくつかの案件でデータの連携を開始したり、LINEビジネスコネクトを活用して間接的に企業のデータをマーケティングに活用したりといった動きが出てきました。いかにして企業の保有するデータをマーケティングに活用するかという点は、重要視されてきていると感じています。まずは企業が持っている顧客のデータを解析し、それを私たちのようなサードパーティが持つデータと融合させることで、企業の顧客と近い見込み顧客がどこにいるのかを発見することができるようになる。私たちもそういった価値を提供する仕組みを用意しているので、実際に企業に活用していただき、そのメリットを実感してもらいたいと思っています。●アドブロックは“話題先行”、しかし対応を考える必要はある―― 一方で、広告を配信する技術では新しいトピックスはありますか? 広告配信では前述のターゲティング技術はもちろん、効率やコストの最適化などが求められると思いますが。永松氏:取引の仕組みについては、プライベートマーケットプレイスのようなものが拡大するのではないかと思います。私たちでも、完全オープンな広告オークションでの取引に抵抗のある企業に対して、招待制で厳選された広告主、媒体社だけが参加することができる価値の高い広告在庫のマーケットプレイスを用意しています。加えて、配信技術については、昨年から注目されてきているアドブロックに対して技術的にどう対処していくかは、少しずつ出てきているところです。例えば、「アドステッチング」という従来のコンテンツ=コンテンツサーバー、広告=アドサーバーという区別を見直して、コンテンツと広告を一体化して同じサーバーから配信するといった考え方や、「ファーストパーティー・アドサーヴィング」といって媒体社もしくは広告主のドメインで広告を配信するといった考え方が生まれています。アドブロックについては日本では話題が先行しているものの、実際のところはまだまだこれからなので早急に対応する必要はありませんが、市場の動向次第では2016年の大きなテーマになる可能性はあるので、今後対応を考えていかなければならないと感じています。○テレビとネットの融合、技術的には連携させるロジックが確立へ――民放各局が参加する「TVer」に代表される見逃し配信の拡大や、オンライン動画を活用したコンテンツマーケティングの発展などを背景に、動画に対する注目も高まってきています。このような動きはデジタルマーケティング、中でもターゲティングや効果測定にどのような影響を与えるでしょうか?永松氏:ここ最近では、テレビ広告とオンライン広告を一緒に売るという動きは浸透してきていると感じています。ただ、データという点ではテレビとオンラインはまだ繋がりが弱い状態にあって、例えばテレビを観ていない視聴者にオンライン広告を見せたいといったニーズに対しては、まだ明確なロジックが生み出されているわけではありません。テレビ広告とオンライン広告の組み合わせで“リーチを拡げる”という効果を求めようとしても、まだその方法は確立していないのです。ただ、例えば一部のスマートテレビ(ネット接続が可能なテレビ)で可能となってきた視聴ログの収集が拡大すれば、ネットの視聴ログと組み合わせて広告に活用できるのではないかと考えています。まだ研究段階の技術も多いですが、これまでありそうでなかったテレビ視聴データのデジタル化は技術的にかなり現実的になってきました。これが実用化されれば、テレビとオンラインを連動させたターゲティングのロジックとそれによるリーチの拡大も現実味を帯びてくるのではないでしょうか。○データの利活用とプライバシーの課題は“表裏一体”――ネットに繋がるシーンが増え、ユーザーとの距離も近づくと、取得できるデータも豊富になる。そうなると、やはりデータとプライバシーの問題は避けて通れないと思います。「広告はユーザーデータをどこまで収集・活用するか」という論点はまだまだ議論の余地があるのではないでしょうか?永松氏:そうですね。ユーザーにどのような配慮をしてデータを収集・活用するかという点は、改正個人情報保護法の動きなどを踏まえながら当社でも厳しくチェックをしているところです。データを取得するという場面においても、オプトアウトの選択権をユーザーに提供しています。また、当社がデータを取り扱う際も、いくら匿名データであっても細分化された様々なデータを積み上げていくと個人の特定性が高まってしまうので、常にユーザーがある複数のセグメントで固められた母集団で構成されるよう分析ロジックを工夫しているところです。この問題は、ユーザーの近いところに迫れるようになったからこそ、真剣に考えなければなりません。私たちにとって「データ」は大きな研究テーマですが、それと同じくらい「プライバシー」も重要なテーマだと位置づけており、社内では専門チームをつくり、社外では各業界団体と連携して考えているところです。●実態を伴う効果指標によってメディアと広告の新たなエコシステムを――広告手法の高度化、タッチポイントの多様化によって、広告の指標やビジネスモデルも大きく変化していくと思います。広告のビジネスモデルで今後どのような動きがあるでしょうか?永松氏:パフォーマンスを目的とした広告については、最適化のロジックや運用方法の進化はあるものの、あまり大きな動きはないと思います。一方で、ブランディング広告については大きな変化があるのではないかと思います。例えば、最近増えている動画広告については従来のような“1インプレッション”では効果を評価できない場合が出てくる。オンラインの動画広告はテレビのように15秒や30秒といった固定値とも限らない。そこで、視聴時間に応じた課金モデルである「CPH(Cost per Hour)」など新しい効果測定の手法について検討が進んでいくのではないでしょうか。――確かに、ログデータとして記録されるインプレッション数や再生回数が実態(ネット視聴者の広告接触・視聴)を伴っているかどうかについては、疑問の声が挙がっていましたね。永松氏:よりネット視聴者の利用実態に合わせた効果測定・課金のモデルの最適化が考えられていくのではないかと思います。例えば昨年は海外で、ブラウザ下部のユーザーが見えない場所に表示された広告を1インプレッションとカウントしていることへの課題意識から、バナーが視認できる場所に表示され、実際にネット視聴者がバナーを見た回数を1インプレッションとみなす「ビューアビリティ」という言葉が出てきていて、この考え方で課金する「vCPM(v=viewability)」というモデルも生まれています。これは日本でも現在検討が進んでいて、より現実に即した課金モデルが普及していくのではないでしょうか。――vCPMはとても良い発想だと思いますが、広告収益に依存しているパブリッシャーにとっては少し辛いところですね。永松氏:そこが大きな課題だと思います。アメリカではvCPMでなければ広告を買わないという広告主も多くなってきていて、GoogleやFacebookといった大手メディアも対応を始めています。他のメディアも追随せざるを得ない状況が生まれつつあります。日本ではまだそこまでではありませんが、もし同じような状況が生まれた際には、広告単価をしっかり向上させなければ広告メディアにとってのメリットがなくなってしまいます。その点には十分に注意を払っていく必要があると思います。――CPCにしても、CPMにしても、単価は右肩下がりの傾向が続いている。それはブランドの認知やトランザクションといった広告主のKGIに対して十分な費用対効果を提供できていなかったからだとも言える。それに対して、vCPMによって費用対効果を向上することができれば、広告単価は向上するのが自然だと言えますよね。永松氏:そのようなスキームに落とし込んでインターネット広告のエコシステムを活性化していくことが広告会社に課せられた使命なのではないかと思います。○新しい技術、アドテクノロジーにどう取り込むか―― 昨年はウェアラブルデバイスに対する注目が高まった年でした。デジタルマーケティングはこの動きに追随していくのでしょうか。永松氏:いくつかアドテクノロジーとして検討する方向性があるのではないかと思います。ひとつは、広告を表示するメディアとしての可能性。ただこれは、表示面の大きさが多種多様などの点から、ハードルはかなり高いのではないかと思います。一方で、広告配信のベースとなるユーザーの状態や興味関心といったデータを取得する手段として活用するという考えもあり、まずはここからウェアラブルデバイスやIoTの活用が進むのではないかと思います。――また、テクノロジーの世界ではIoTやAI(人工知能)の動きが加速しています。デジタルマーケティングはこうした技術をどのように取り込んでいくのでしょうか?永松氏:人工知能(特に機械学習やディープラーニング、認識技術等)をどうマーケティングのテクノロジーに取り込んでいくかという点は、既にターゲティングといった広告配信で活用しているものもありますが、さらに研究を進めていくところです。考えられる活動領域としては、レコメンドやターゲティング、予算配分、クリエイティブの最適化、効果検証といった分野ですが、それぞれでどのような活用が可能かを試行錯誤しています。○ネット広告とユーザーが、良い関係を築くために――AIなどは、収集したデータを基に広告をアウトプットする場面で活用できるのではないかとも思います。例えば、ユーザーはネット広告を“邪魔な存在”だと思っている場合が多い。こうした課題に対して、機械学習や人工知能の活用はネット広告とユーザーとの間に良い関係を築くためのヒントを生み出すのではないでしょうか?永松氏:それは大いにあると思います。今までは、広告会社はあまりユーザー目線でネット広告を考える立場ではなかったとも言えます。しかし、データとプライバシーの問題を例にとっても、今後はそのような立場では難しい時代になってくるのではないかと思います。広告会社・広告主とユーザーの距離がどんどん近くなってきている中で、広告とユーザーが発展的に良い関係を築くことができるような方法論を考えていくことは、非常に重要だと思います。広告会社はユーザーに対してもオープンでいなければ、立場が難しくなっていく時代になるのではないでしょうか。――ネット広告そのものに対してユーザーからの支持・信頼を得られなければ、業界全体が高まっていかないですよね。永松氏:そうですね。スマートフォンが普及したことによって、ユーザーとネットの距離がさらに縮まり、その課題はより顕在化したのではないかと思います。これまでと違って、ネットでは本当に様々な広告手法が生み出されています。様々なネット上のサービスをみても、ユーザーの支持・信頼を得ているものが継続的な成長をしていき勝者となっています。ネット広告とユーザーの間に良い関係を築くためには、考えていかなければならない重要な課題です。
2016年02月01日
データビークルは1月29日、電通、アプレッソ、takram design engineeringと共同開発したデータサイエンス専用変換ツール「Data Ferry」(データフェリー)を5月9日より発売すると発表した。初めに、代表取締役 CEOを務める油野達也氏が新製品を開発した経緯を説明した。油野氏によると、データ分析がうまくいかない原因はデータの切り分け方にあり、データ切り分けにおける課題を解決する製品として、同社が昨年7月に発表したのがデータ分析ソフト「Data Diver」だ。「データ分析は、収集・分析・行動といったステップを踏む。データの切り分けがよくないパターンは2つあり、1つはIT部門が収集と分析を行い、現場が行動を行っているパターン、もう1つはIT部門が収集を行い、分析を外部のデータサイエンティストが行い、現場が行動を行っているパターン。前者の場合、現場がどのように行動するべきかわからなくなっており、後者の場合、データサイエンティストはお金と時間がかかる割には、業務についてわかっていないという問題が生じている」そこで、「Data Diver」はプログラミングの知識がなくても高度な統計技術を利用できるようにすることで、現場が分析まで踏み込めるようにした。ただし、「Data Diver」を展開する中で、「データ連携ソフトが高い」「データをタイミングよく入手できない」といったデータ連携やデータ整備における課題が見えてきたという。こうした課題を解決するため開発されたのが「Data Ferry」だ。油野氏には、データ分析を行うデータサイエンティストには専用機が必要であると考え、「素性のよいエンジン」を探していたところ、アプレッソに行き着いたと語った。「『高度な改善要求に耐えられる製品を持っていること』『共に戦えるエンジニアがいること』『海外で実績を持つファクトリー体制があること』という要素がそろっているエンジンを探していたが、正にアプレッソがそうだった」(油野氏)「Data Ferry」にエンジンを提供するアプレッソの代表取締役社長を務める小野和俊氏も説明会に登壇した。小野氏は代表取締役社長という立場ながら、根っからの"技術者"ということで、今でもアプレッソの製品のエンジニアリングに関わっているという。小野氏は、油野氏が挙げた「素性のよいエンジン」の条件を引き合いに出し、同社の技術力の高さをアピールした。「これまで、各所からコンサルティングも提供してはどうかとの声もいただいてきたが、一貫してプロダクトの開発に注力してきた。また、ビッグデータの分析に対するニーズの高まりなどを踏まえ、大量のデータを高速処理できる機構も独自で開発しているほか、Javaエンジニアも多数そろっており、技術力には自信がある。また、エンジニアについても、新規の戦略アライアンスなどに対応できる開発体制を構築しており、開発生産性を最大化するための環境への投資も積極的に行っている。製品のグローバルかも着実に進めており、販売に加え、シンガポールに開発拠点を設けたり、英語・中国語でサポートを提供したりするなど、力を入れている」「Data Ferry」の機能については、製品企画担当の藤田大地氏が説明を行った。藤田氏は、「Data Ferry」のコンセプトについて、「分析に特化したツールであり、基本となるEAIは安定した国産エンジンを搭載している。ターゲットはIT部門以外としているため、設定はすべて自然言語で行える思い通りに、ユーザー自身がデータを加工できるような仕組みを用意している」と語った。「Data Ferry」の技術面におけるキモは専用ストレージ「Analytical Source Lake」だ。各種データソースを統一されたデータセットに変換し、分析可能な形で醸成・蓄積することができる。Analytical Source Lakeに蓄積されたデータについて集計、テーブル統合、サンプリング、クレンジングが行われる。加えて、藤田氏は「Data Ferry」の特徴として「完全なプログラムレス」「データベース内蔵」「分析に関する処理をすべて自動化」「オンプレミスとクラウドを双方向で接続」「データのマスキングによるセキュリティ対策」を挙げた。「Data Ferry」はクラウドサービスとして提供され、利用料は月額40万円から(1ユーザーID、初期データ容量は1TBまで)。オンプレミスの販売については、国内のSIベンダーと協業を進めているところだという。
2016年01月29日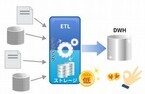
アシストは1月28日、データウェアハウス最適化のための中核ソリューションとして、データクレンジングに必要なソフトウェアとハードウェアをパッケージとして提供する「ビッグデータ・クレンジングパッケージ」を提供開始した。「ビッグデータ・クレンジングパッケージ」は、分析用データを蓄積する基盤として活用が広がっている「MapR Enterprise Edition(M5)」、IAサーバ「HP ProLiant DLシリーズ」、ETLツール「SyncsortDMX-h」、各種技術支援サービスを組み合わせて提供するもの。同パッケージは、データベースのライセンスコストおよびストレージコスト、データ収集や加工といったデータクレンジングに要するコストを低減する。同社は、同パッケージの提供開始に合わせ、1月21日より「MapR版Syncsort DMX-h Sandbox(トライアルキット)」のダウンロード提供を開始している。これは、「Syncsort DMX-h」と「MapR」を同梱したVMWarePlayer用仮想マシン。自社にHadoop環境がなくても、Hadoop上でビッグデータをクレンジングするためのETL処理の開発と実行が体験できる、トライアルキットに含まれるサンプルのデータとアプリケーションで、売上集計、差分抽出、Webログ集計、文字列カウントの4つのジョブをチュートリアルに沿って実行することも可能。
2016年01月29日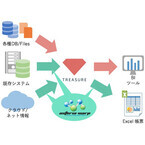
インフォテリアは1月28日、トレジャーデータが提供するクラウド型のデータマネジメントサービス「トレジャーデータサービス」とのデータ連携に、インフォテリアのEAI/ESB製品であるASTERIAシリーズの「ASTERIAWARP(アステリアワープ)」が対応し、双方で検証が完了したことを発表した。トレジャーデータサービスは、各種データベースやファイルシステムからデータを抽出する機能とクラウド上に保存する機能を備える。最近ではIoT(Internet of Things)の利活用を検討している企業が増加し、大量のデータをクラウドで集計・管理を行うトレジャーデータサービスへの注目も高まっている。しかし、多くの国内企業では既存システムや、さまざまなクラウドサービス、インターネット上のデータを分析の対象とする要望が数多く存在しているという。一方、ASTERIAWARPは異なるコンピューターシステムのデータをノンプログラミングで連携できるミドルウェア。メインフレームやクラウド上のサーバーから表計算ソフトまで、さまざまなシステム間の接続とデータの変換を行うロジックを複雑なプログラミングなしで行い、既存システムから最新のサービスまで連携することができる。今回の連携によるメリットは、トレジャーデータサービスで各種データベースやファイルシステムから抽出したデータに対して、ASTERIAWARPが既存システム、クラウドサービスなどのデータを統合し、送付することでデータの見える化を推進するものだという。また、データの集計結果を帳票とする際にもASTERIA WARPを利用してExcelの帳票とすることが可能なためきめ細やかな帳票出力に対応し、互いのメリットを活かせる協力関係を築くことができるという。インフォテリアでは今後もASTERIAWARPの多様なデータソースとの連携機能を駆使し、最新のクラウド環境に対応するなど社内業務のクラウド化による利便性を引き出せるITソリューションを構築していく方針だ。
2016年01月29日
矢野経済研究所が1月27日に発表した「小売業のビッグデータ活用に関する調査結果2015」によると、国内の大手小売業者が今後データ利用したいと考えている業務領域では、既存客の来店頻度向上が最多であり、以下、マーチャンダイジング(商品政策)、客単価の向上の順だったという。同調査は同社が2015年11月~12月にかけて、日本国内の売上高上位の小売業者(百貨店・スーパーマーケット・専門店・生協など)を対象として電話によるヒアリングにより実施したものであり、有効回答数は173社。それによると、今後データ利用をしたい業務領域は、上位から、既存客の来店頻度向上が61.8%、マーチャンダイジング(商品政策)が53.2%、客単価の向上が50.3%の順だったという。一方、O2O(Online to Offline)は11.0%、オムニチャネルの実現は15.6%と、将来的なデータ活用の課題についての回答率は低かった。小売業がデータ利用したい業務領域としては、将来よりも日々の課題、中でも集客に対する強いニーズがあるという結果になったと同社は分析する。今後のビッグデータ活用への取り組みを尋ねると、「積極的に取り組んでいる」と回答した企業は6.9%であり、取り組みは遅れているのが実情だ。また、「未だ取り組んではいないが、今後の重要な課題である」と捉えている企業も20.2%に留まっている。逆に、「課題ではあるが優先度は低い」という企業が42.8%であり、「取り組む予定は無し」の28.9%と合わせると、全体の7割以上が現状ではビッグデータの活用にさほど積極的ではないと同社は見ている。業態別に見ると、ビッグデータの活用に最も積極的に取り組んでいるのは生協であり、2 割弱の企業が「積極的に取り組んでいる」と回答しており、「今後の重要課題である」という認識も3割近くに達した。一方で「取り組む予定は無し」が1割を下回っており、他の業態と比較すると、相対的に関心が高いと同社は見る。生協は組合員の情報を正確にストックしていると考えられ、他の業態と比較して、顧客の顔が見えていることが分析のニーズを高めている可能性があると同社は考えている。百貨店については、「今後の重要課題である」という回答比率が29.2%と全業態の中で最も高いものの、「課題ではあるが優先度は低い」という企業の比率も50.0%と最も割合が高い。最もネガティブな意見が多いのはスーパーマーケットであり、取扱品目が近い生協と比較すると、その差が極めて大きいと同社は指摘する。小売業者におけるビッグデータへの取り組みは遅れている状況であり、「積極的に取り組んでいる」と回答した企業においても、一般的にビッグデータと言われるような非構造化データよりも、従来から社内に多数ストックしているPOSデータや顧客関連データなどを積極的に利用しようとする取り組みが、現状においてはビッグデータ分析の中心になっていると同社は見る。小売業でのITによるデータ利用については、まだまだこれからの発展の余地が大きいと、同社は推測している。
2016年01月28日
NTTデータグローバルソリューションズ(NTTデータGSL)と日本マイクロソフトは1月26日、Microsoft Azureをクラウド基盤として利用したSAPソリューション・マイグレーション・サービスで協業すると発表した。NTTデータGSLは、Microsoft Azureの特性を生かした形で、SAPソリューションの移行・運用ベストプラクティスの検証・開発・展開を行う。SAPソリューションがどのデータベースを利用していてもAzure上に展開でき、ライセンス移管および保守サービスの継続提供も可能だという。東日本・西日本の2つのデータセンターリージョンおよびグローバル・ネットワークを持つAzureの特性を生かし、ディザスタ・リカバリをクラウドサービスとして提供することができる。また、Azure Site Recovery(ASR)を利用して、オンプレミスからクラウドへのディザスタ・リカバリ設計を、SAPソリューションのシステム構成に最適化してベストプラクティス化する。システム監視にはNTTデータのオープンソース監視ソフトウェアである「Hinemos」を採用するほか、インシデント管理には「SAP Solution Manager」を利用し、新たなソフトウェアを構築することなく運用プロセスの効率化を実現する。両社は今後、Azure上でのSAPソリューションの拡販に向けてバーチャル・チームを組織し、共同でターゲット顧客の選定と共同提案を行うとしている。日本マイクロソフトは、同バーチャル・チームを通じ、米マイクロソフトの開発部門が実施するSAP認証取得の中で得た技術情報を共有し、ユーザー企業への展開に際してトラブルを最小化した展開が可能となるよう技術情報の拡充も図っていくとしている。両社はすでに連携しており、不動産市場向けのクラウドサービスを提供するいい生活の基幹業務システムであるSAP ERPをMicrosoft Azureに移行した事例を公開している。
2016年01月27日
暗号化はデータの損失や窃盗から保護するための最善策であり、サイバー攻撃や偶発的なデータ漏えいの最後の砦となるものだ。今回ソフォスは、6カ国、1700人のIT意思決定者を対象に調査を行い、その結果を「The State of Encryption Today(暗号化の現状)」としてまとめた。この調査によると、多くの企業が顧客のデータ保護は真剣に考えているものの、従業員のデータは同レベルで保護していないことがわかった。例えば、企業の31%が従業員の銀行口座情報を常時暗号化しておらず、43%が人事記録についても常時暗号化していなかった。また、ヘルスケア関連では比率が47%に上った。○暗号化の範囲が不明瞭な企業も従業員だけでなく、企業のデータもリスクにさらされている。30%の企業が自社の財務情報を暗号化しておらず、41%は重要な知財を含むファイルをきちんと暗号化していなかった。これは産業スパイのリスクを増加させることになる。また、暗号化の種類にはハードディスクをまるごと暗号化する「フルディスク暗号化」とファイル単位の暗号化があるが、これらの違いを正確に理解していない企業もあり、両方を利用している企業は36%だった。近年採用が進むクラウド・ソリューションだが、84%の企業がクラウドに保存しているデータの安全性に懸念を抱いていることがわかった。それでも80%がストレージ目的でクラウドを利用しており、そのうちクラウドにあるファイルをすべて暗号化していると回答した企業は39%にとどまった。では、なぜ企業の多くが全種類のデータを、格納場所に関係なく、暗号化を常時行えないのだろうか?企業に暗号化ソリューションを導入する際の障害を尋ねたところ、「予算」や「(実利用上の利便性といった)性能劣化の心配」「実装知識の欠如」が多く挙がった。ソフォスは「暗号化の実装はとても複雑で高価だという認識が多いものの、最新の暗号化ソリューションは簡単に実装できてコスト効果も高い」としている。
2016年01月26日
NTTデータとスペインの子会社であるeveris(エヴェリス)グループは1月15日、Andalusian Health Service(アンダルシアンヘルスサービス)、Virgen del Rocio University Hospital in Seville(ヴァーゲン・デル・ロシオ大学セビリア病院)と集中治療室(ICU)向けの医療データ分析ソリューションの実証実験を開始すると発表した。実証実験はICU向け医療データ分析ソリューションの開発に向けた共同研究の一環として、1月27日~3月31日の期間で医師などの協力によりICUにおける有用性を評価する。同ソリューションは、均一かつ迅速な医療を目的に治療手順にのっとり、電子カルテやモニタリングデータなどの情報を一元化して提示することで医師のリアルタイムな意思決定をサポート。将来的には患者の症状推移の予測情報を提供することを目指しており、2017年にエヴェリスを軸にスペイン、ラテンアメリカにおいて同ソリューションを「ehCOS Smart ICU」として提供開始。その後、グローバルに展開しているNTTデータグループ会社を通じて、欧米諸国などへのサービスの提供を予定している。これまでNTTデータとエヴェリスは医師の意思決定の効率化や精度の改善を目的にICUで用いられている各種医療機器から得られる情報を1つのプラットフォームに集約し、患者の状態を示すデータとして一元化したうえで提示していたほか、これらのデータを分析することで症状推移の予測情報を提供するソリューションの開発を目指し、共同研究を行ってきた。今回、プロトタイプのシステムが完成したことから、実証実験を行い、実際の医療現場における声を反映させることで、2017年をめどに同ソリューションの完成を目指す。同ソリューションはICUの医師に対し、治療に関する注意喚起情報や症状推移の予測情報など患者の状態、治療状況に関する情報を一元的に提供することを目指しており、エヴェリスの電子カルテを中心とした病院向けソリューション「ehCOS」に、NTTデータ技術開発本部で開発を進めているビッグデータ分析ソリューションを組み合わせて開発。ビッグデータ分析ソリューションは、オープンソースを活用したものであり、大量のストリーミングデータに対するリアルタイムなデータ分析を可能とする。なお、実証実験はVirgen del Rocio University Hospital in Sevilleで実施し、プロトタイプシステムを用いて医師への治療手順伝達手法の検証やデータ収集プラットフォームの性能検証、患者の症状推移の予測技術開発などを進める。
2016年01月15日
オプトは1月14日、Googleアナリティクスで取得できるデータと、オプトのアプリプロモーション支援プラットフォーム「Spin App」にて取得できるデータを活用し、iPhone・Androidアプリ解析サービスの提供を開始した。同サービスでは、ユーザー属性やアプリ内でのユーザー行動、ユーザー通知の開封数などアプリ独自の解析が可能。これにより、アプリを運営する企業は、ユーザーの傾向を把握・分析することができる。また、オプトでは、解析に必要な情報を的確に取得できるよう導入支援も行うため、導入企業はアプリ解析に関する一連のサービスを総合的に受けることが可能だ。
2016年01月15日
情報通信研究機構(NICT)は1月14日、大量のデータを暗号化したまま複数のグループに分類できるビッグデータ向け解析技術を開発したと発表した。今回、データを暗号化した状態でロジスティック回帰分析を高速に行う手法を世界で初めて開発した。新技術はNICTが開発していた準同型暗号技術である「SPHERE(スフィア)」と機械学習の1つであるロジスティック回帰分析技術を組み合わせることで実現。新技術は暗号化した状態でデータを分類できるため、個人情報などの機微な情報を安全に効率よく分類することが可能になる。応用例の1つとして、新技術を用いて健康診断などのデータから病気の判定を行う際にデータ処理を行う第三者にデータの内容を開示することなく、プライバシーを保護できるようになると期待されている。また、大量のデータを暗号化したまま複数のグループに分類することを可能とし、高速化の要となる技術は関数の近似とデータ処理の分割の2点となる。最初にNICTはロジスティック回帰分析中に含まれる複雑な関数を単純な多項式で近似し、準同型暗号と組み合わせることで現実的な時間で動作する方式を考案。次にロジスティック回帰分析に含まれる計算をデータ加工処理と集計処理の2つの部分に分割し、データ加工をあらかじめデータ提供者側で行うことで高速化を進めた。これら2点の改良と同機構が開発したSPHEREを組み合わせることで、大量のデータを暗号化したままでロジスティック回帰分析を行うことが可能となり、シミュレーションではサーバ上で1億件のデータを30分以内で分析可能であることが確認できた。さらに、米UCI機械学習リポジトリ(カルフォルニア大学アーバイン校のWebサイトで公開されているデータベース)で公開されている実験用データを用い、新技術によりデータを暗号化したままロジスティック回帰分析を行った結果と、暗号化せずに分析した結果がほぼ一致することを確認した。新技術を用いることで、クラウドサーバなどを用いてデータの分類を行う際、データに含まれるプライバシー情報がサーバ管理者に漏えいすることを防ぐことができるという。
2016年01月14日
Microsoftは1月12日(米国時間)、「Making R the Enterprise Standard for Cross-Platform Analytics, Both On-Premises and in the Cloud - Machine Learning - Site Home - TechNet Blogs」において、統計計算や予測分析などに利用できるビッグデータ解析プラットフォーム「Microsoft R Server」を公開したと伝えた。ほかのエンタープライズ向けプロダクトと同様のサポートサービスも提供されることになる。「Microsoft R Server」はこれまでは「Revolution R Enterprise」という製品としてRevolution Analyticsによって販売されていたプロダクト。Microsoftは1年ほど前にRevolution Analyticsの買収を発表。以後、プログラミング言語RおよびRevolution Analyticsの技術をMicrosoftの製品ラインにマージする開発に取り組み、今回の公開となった。提供されるエディションは以下のとおり。R Server for Red Hat Linux→64ビット版Red Hat Enterprise Linux (or CentOS) 5.x or 6.xで動作R Server for SUSE Linux→64ビットSUSE Linux Enterprise Server 11 SP2 or SP3で動作R Server for Hadoop on Red Hat→Cloudera CDH 5.0-5.4 on RHEL 6.x、Hortonworks HDP 2.0-2.3 on RHEL 6.x、MapR M3/5/7 3.x, 4.0-4.1 on RHEL 6.xで動作R Server for Teradata DB→Teradata Database 14.10, 15.00, 15.10 on SLES 10.x or 11.xで動作MicrosoftはMicrosoft R Serverを提供することでWindowsプラットフォームを統計データの計算や予測分析などのプラットフォームとして推進したい狙いがある。今回公開されたMicrosoft R ServerではRのバージョン3.2.2がサポートされているほか、Microsoftが他のエンタープライズ向けプロダクトに提供しているのと同じレベルのサポートサービスが提供されている。プログラミング言語Rはデータ分析や解析の分野で広く使われており、近年その注目度を増やしている。これまでRevolution Analyticsによって「Revolution R Open」と呼ばれてきたプロダクトは「Microsoft R Open」として提供されるほか、今後も継続してオープンソースのRプロジェクトをサポートするとの説明がある。
2016年01月14日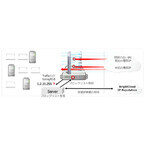
伊藤忠テクノソリューションズ(CTC)は1月8日、ビッグデータを活用したセキュリティ対策ソリューションの提供を開始すると発表した。提供するソリューションはウェブルートのクラウドサービス「BrightCloud IP Reputation」を採用したもので、ビッグデータを活用した脅威分析エンジンで、未知の脅威に対応する。具体的には、ウェブルートが独自技術で世界約43億個のグローバルIPアドレスを追跡・監視し、機械学習アルゴリズムを使用して危険性のあるIPアドレスをリスト化する。リストは1日8万件が更新されており、企業は常に最新の情報に基づいて脅威対策ができるという。CTCが取り扱うBrightCloud IP Reputationは、パルアルトネットワークスの次世代ファイアウォール用「BrightCloud IP Reputation for Palo Alto Networks」と、Splunkのビッグデータを活用したログ管理ソフトウェアに対応した「BrightCloud IP Reputation for Splunk」となる。同社によると、このパロアルトネットワークス製品の提供は国内で初めて。同社は、独自のSOCを開設しており、今後は遠隔監視のモニタリングサービスとの連携や、他のセキュリティ製品向けBrightCloud IP Reputationの取り扱いも含めてセキュリティサービスを拡充するとしている。
2016年01月08日
インテージリサーチは12月24日、「モバイル空間統計」と「レコーディングリサーチ」を活用し、埼玉県川越市を対象に観光資源への来訪実態把握と観光資源の芽を見つけるための自主企画調査を実施し、その結果を公表した。同調査は2014年11月、川越市内の500mメッシュ×7エリアにて、川越市外の居住者かつ調査対象期間に調査地域に滞在した人を対象に行われたもの。自主企画による調査方法の有効性の検証を目的に実施された。なお、モバイル空間統計とは、NTTドコモの携帯電話ネットワークのしくみを使用し、6,600万台の運用データを基に作成される新たな人口統計情報。性別・年齢層別・居住地域別人口構成を、国内人口に加え、訪日外国人についても知ることができる。一方、レコーディングリサーチとは、従来の記憶型のアンケート調査とは異なり、スマートフォンを用いて継続記録形式で回答を得る手法。常に持ち歩いているスマートフォンから、知りたい瞬間のリアルな声を集めることで、生活者に近いデータから新たな発見を得ることが可能だ。○居住地により、川越市への滞在時間に差が同調査によると、モバイル空間統計からは、アンケート調査を実施せずとも年代別の滞在場所の差や居住地による流出入時間の差異を可視化できたという。川越市の中心部を観光エリア5つと駅前エリア2つに分け、調査対象期間に川越市外からの来訪者が川越市のどこに多く滞在しているかを年代別にみていくと、60・70代は各エリアで滞在人口が多く、さまざまな場所を周遊していることがうかがえる。一方、10・20代は、駅前エリアでの滞在人口が他年代より多く、周遊エリアが狭いことがわかる。また、川越市に比較的近い東京都からの来訪者は、9時から10時、11時となだらかに増加し、17時になってもピーク時と比較して約60%の人が滞在していることから、隣県である東京からの来訪者は、さまざまな時間帯で川越市を楽しんでいると推測できる。一方で、神奈川県からの来訪者は、10時に滞在者が増えたあと12時と14時にピークがあり、17時には滞在者が大きく減少。このことから、神奈川県からの来訪者は比較的短時間の滞在で集中して来訪している様子が見て取れる。このようにモバイル空間統計を活用することにより、ターゲットごとの動きの違いを可視化し、ターゲットに応じた来訪や周遊の増加施策のための戦略立案に役立てることができるのだという。さらに、レコーディングリサーチでは、観光名所以外のおすすめポイントを抽出できた。川越来訪時にリアルタイムでおすすめポイントを記録した数の集計結果から、20代では、他の年代と比較して、観光エリア以外でのおすすめポイントが挙がる傾向が見られた。このように、具体的なリアルタイム記録を活用することにより、観光資源の芽の発見に役立てることが可能。記録から、実際のおすすめポイントがさまざまな場所にまたがっていることが判明したほか、有名な観光名所以外のおすすめポイントの情報も得ることができた。
2015年12月25日
東京コピーライターズクラブ(以下、TCC)は12月21日、一年間の広告に使用されたキャッチフレーズとなる「広告コピー」を集約し、高頻度で登場した単語に関する統計を分析、その内容を「広告コピービッグデータ解析」として発表した。同分析では、2015年TCC賞の選考対象となった広告コピー8,119件を自然言語解析。これによると、「最も多く見られる広告コピーは8単語によるもの」との結果に。さらに、語順・品詞別頻出単語トップ10から、文章が成立する単語を選出し浮き上がったコピーが「あなたのことは、すきだ。」となり、2015年広告コピーの「平均値」といえるという。なお、語順・品詞別頻出単語トップ10一覧は次のとおり。同分析によると、品詞別の頻出単語の特徴としては、名詞の場合「人」「私」「あなた」が上位を占める。TVやラジオのCMといった映像・音声では「あなた」より「私」、グラフィック系のコピーは「私」より「あなた」の方が、それぞれ出現回数が高い。一方、動詞の場合は、「する」「なる」「ある」が不動のトップ3で、その下に「言う」「思う」「見る」「行く」が並ぶ。「~する」の特徴的な組み合わせは「応援する」「結婚する」「想像する」など。形容詞の場合「いい」「ない」「おいしい」が登場し、「悪い」や「のろい」といったネガティブなワードも多く見られた。○「あなたのことは、好きだ。」こうした解析結果をふまえ、あらためて2015年の広告集約コピー「あなたのことは、好きだ。」を見ると、広告表現は不特定多数の「誰か」への発信から、より他の誰でもなく選ばれた「あなた」に向けて語りかけるものになってきているともいえるようだ。同社は、「『あなたのことは、好きだ。(でもあなたのこういうところが~)』と、あとに続く言葉は決して心穏やかな内容ではなさそうだが、そこがかえって今年の世相や大衆の気分とリンクしていそうな結果を示したのは、なんとも皮肉な話。年末年始、身近な人々と一緒に過ごす機会の多いこの時期に『あなた』なら『私』にどんな言葉を続けるのか、話に花を咲かせてみてはいかがだろうか」としている。
2015年12月22日
NTTデータとSassorは、エネルギーマネジメントサービス分野で協業することで合意したと発表した。同協業では、NTTデータが提供する電力事業者向けアプリケーションプラットフォーム「ECONO-CREA」とSassorのIoTアプリケーションおよびサービスを連携させ、エネルギーマネジメントサービスを提供することを目的としている。「ECONO-CREA」は、電力データや分電盤データなどのIoTデータのみならず、仕様の異なるさまざまなデータを一元的に収集・保管・マイニングを行い、サービスプロバイダーにAPIを提供するプラットフォームとなる。今回の協業の第一弾では、2016年1月より、Sassorの「Energy Literacy Platform(ELP)」を、ECONO-CREAのアプリケーションに追加し、提供する予定となっている。今回の協業における各社の役割として、NTTデータでは、ECONO-CREAのアプリケーションプラットフォームを提供し、データの収集・保管・マイニングおよびAPIをサービスプロバイダーとなるSassorに提供し、Sassorは、ECONO-CREAを活用してELPサービスを電力需要家や企業などのユーザーに提供する。なお、協業後は、両社の分析ノウハウを組み合わせて、需要家の使用電力に関するデータ分析サービスを提供する予定だという。
2015年12月21日
国立情報学研究所(NII)は12月18日、記者懇談会を開催し、NII情報学プリンシプル研究系教授の河原林健一氏が「理論研究とビッグデータ&人工知能」をテーマに講演し、日本におけるビッグデータ・AI業界の現状や同氏が研究総括を務める「河原林巨大グラフプロジェクト」について説明した。冒頭に同氏はビッグデータの出現により「データ量の増大でコンピューターの演算処理が求められる速度に追い付かなくなってきたほか、無人センサーが過剰に情報を集めていることやSNSの出現で、最適な答えを長い時間(1週間~1カ月)で求めることよりも短時間で1%の改良に対する欲求があり、かつダイナミックな変化に追従する必要もある。そこでNIIはデータ量の増大に対し、コンピューター以外にビッグデータに関する理論研究と実用研究を行っている」と語った。また「情報爆発時代(ビッグデータ処理)を迎え、理論研究者へのニーズの高まりを受け、理論研究の経験を有した意欲的な研究者が実用研究へ参入することで大きな成果を収められつつある。理論の導入による新しい実用手法としては情報爆発を計算理論で制御するほか、検索エンジン、データマイニング手法などがある。GoogleやマイクロソフトといったIT企業は理論分野で常に基礎研究と先端的な研究を行ってきた研究者を抱える勝ち組だ」と理論研究でも特に基礎研究の重要性を説いた。同氏の説明によると、世界の理論研究の現状はGoogleやAmazon、Facebook、Microsoftなどの巨大IT企業の研究所がスタンフォード大学、マサチューセッツ工科大学といったトップ大学を凌駕しつつあるという。さらに、コンピューターのハード面の進歩のみではなく、理論研究に基づく改善が実際のサービス改善につながっていることや、世界最先端の研究情報を無償で得られ、研究成果のみならずトップ研究者の知見(失敗や成功も含めたノウハウ)も無償で得られることから、巨大IT企業が基礎研究の重要性を認識しており、研究者が実データにアクセスできることはビッグデータ時代に必要不可欠だとしている。加えて、人材についてはNASAやMicrosoft Research、Google Researchの研究員のうち3~5割を抱え、数理化学・理論研究とプログラミング能力を駆使し、産業界との密接なつながりを持つインドや、Facebook、Google、AppleをはじめとしたITトップ企業の雇用者は若手が多いことを例に挙げた。一方、同氏は日本のビッグデータ、AI分野における世界のトップ会議への論文採用数は全体の2~3%程度で特定のワールドクラスの研究者を除くと惨憺たる状況だと指摘。「国内の理論・基礎研究の現状はGoogleやMicrosoft、Amazon、Facebookなどの巨大IT企業の研究所の基礎研究者と差があるほか、基礎研究の重要性が日本企業に認識されているとは言いがたい。今後10年の課題として世界的に評価される基礎研究者で、かつ実社会への問題にも貢献できる人材を多く輩出していくべきだ」と強調。「AI研究の現状として、近年では多くの企業がAIに対する投資を始め、海外の研究機関に多額の資金を投じている一方、日本の研究機関にはあまり投資していないほか、国内市場が大きいため世界的に展開する必要がないため、ますます差がついていく。国内から世界へ研究成果を発信していくことが重要だ」とも述べたそのような状況を鑑み、河原林氏は科学技術振興機構(JST)の「戦略的創造研究推進事業・総括実施型研究(ERATO)」に採択された巨大なネットワークを膨大な点と辺の接続構造を「巨大グラフ」として表現し、理論計算機科学や離散数学などにおける最先端の数学的理論を駆使してそれを解析する、高速アルゴリズムの開発を目指す「河原林巨大グラフプロジェクト」を立ち上げた。同プロジェクトでは世界のトップ会議における日本の論文採用数を全体の5~8%に向上させ、理論ベースの研究が世界のトップへ近づく最短距離だということを示し、離散数学、アルゴリズム、機械学習、データマイニング、統計物理学、データベース、最適化といった広範囲にわたる日本のトップ研究を行っている。研究員数は60人程度で半数以上が28~32才の優秀な若手研究者や大学院生で構成している。同プロジェクトの研究アプローチは難しい研究課題に対し、理論ベースで未来の人材が国際的な研究成果を発揮することを掲げている。そのために必要なこととして河原林氏は「他分野の数学力と日本のスーパーエリートを結集し、1つの課題を追求することや優秀な大学院生を巻き込むことに取り組まなければならない。ビッグデータ・AI時代における5~10年後の達成目標としては日本の論文採用数の向上や5~10人のスーパーエリートを育成し、スーパーエリートの人材育成のエコシステムを軌道に乗せることだ。そして理論分野をほぼ全域カバーする研究組織の構築と総合力の向上が鍵になる」と日本のビッグデータ・AI業界に対して訴えた。
2015年12月21日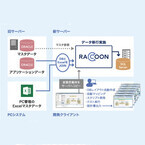
データ・アプリケーション(DAL)は、異なるシステム間のデータ連携・移行を簡単なマッピングだけでノンプログラミングで実現できるデータハンドリングプラットフォーム「RACCOON」の最新版となる「RACCOON V.1.4」を、2015年12月21日より発売すると発表した。最新版では、Excelデータを入出力する際のデータ位置指定方法が増えたほか、データ量に応じた罫線の位置が変更できるようになるなど、さまざまなデータ操作機能が追加・拡張されており、これによりツールの機能に制約されず、ユーザの設計したExcelデータを簡単に生成・変換することが可能となった。また、各種文字コードの代表的な拡張漢字とUnicodeとの対応表を同梱。これにより、拡張漢字の外字定義作成にかかる工数の削減が可能となった。さらに、新たにIBM DB2 for iのデータベースへの接続を可能とし、動作環境の適用範囲も向上させたという。価格は、従来版と同じStandard Editionが300万円(税別)で、タームライセンスは、月額125,000円(同)で、最低利用期間は3カ月となっている。また、Developer Edition(商用利用不可)は200万円(同)となっている。なお、2016年3月末まで、トライアルキャンペーンとして、Standard Editionをキャンペーン価格200万円(同)で提供するという。
2015年12月18日



















