GTC 2015 - 東大/筑波大のTightly Coupled Accelerator「TCAの性能編」
次のグラフはTCAの2つのノードのGPUに間を往復するピンポン通信を行った場合のレーテンシを示している。データサイズが小さい場合、CPU間のPIOでは0.8μs、CPU間のDMAでは1.8μs、GPU間では2.0μsとなっている。
これに対して「MVAPITCH2」でGPU Directを使った場合は4.5μsでPEACH2に比べて2倍以上の遅延となっている。しかし、MVAPITCH2の開発者であるオハイオ州立大のD.K.Panda教授は、質疑の時に、「最新版ではもっと速くなっている。最新版で比較すべき」とクレームを付けていた。実は、Panda先生はこの次の発表者で、その発表ではMVAPITCH2-GDR2.1aでは(次の図で使用した)2.0bに比べて遅延が0.4倍に小さくなり、4KBのデータサイズの場合で2.37μsとTCAに負けない性能となっていた。
次の図はDMAで複数のPEACH2を通過する伝送を行った場合の通信遅延を測定したもので、PEACH2を通過するごとに200~300nsの時間が掛かっていることが分かる。
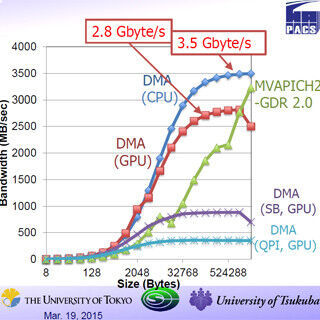
次の図はピンポン通信を行った場合のデータサイズとバンド幅の特性を示すものである。











 上へ戻る
上へ戻る 









