GTC 2015 - MPIを使ったマルチGPUのプログラミング「基礎編」
GTC 2015において、MPIを使うマルチGPUプログラミングというチュートリアルセッションが行われた。これからマルチGPUのシステムのプログラムを作ろうという人には役立ちそうな内容であるので紹介する。
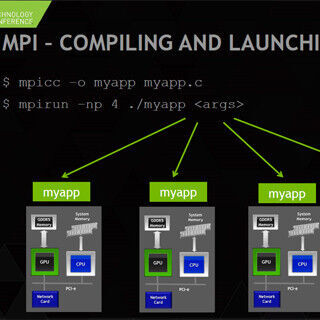
次の図のように、CPUにメモリが付き、さらにPCIe経由でGPUとネットワークカードが付いているというのが計算ノードで、複数の計算ノードがネットワークでつながっているというのが、一般的なマルチGPU環境である。これらのノード間の通信には、MPI(Message Passing Interface)というライブラリが使われることが多い。MPIはSPMD(Single Program Multiple Data)実行モデルであり、すべてのノード(後述のように、正確にはランク)で同じプログラムが走る。
MPIを動かすと、ネットワークに繋がっているすべてのノードを見つけ出し、それぞれのノードに実行すべきプロセスのコピーを作って一連のランク番号を付ける。ここでは各ノードに1ランクとして説明をしているが、MPIの起動時の指定で1つのノードに複数のランクを作ることもできる。1個のCPUに複数台のGPUを接続する場合は、複数のランクが1個のCPUで走り、それぞれのランクが1つのGPUに対応するという造りにするのが一般的である。











 上へ戻る
上へ戻る 









