
シナジーマーケティングは2月9日、同社が提供するクラウド型インテリジェントコミュニケーションプラットフォーム「Synergy!」が、アクティブコアの提供するクラウド型マーケティングプラットフォーム「activecore marketing cloud」と連携したことを発表した。「activecore marketing cloud」は、企業独自のマーケティングデータの集約基盤である「プライベートDMP」を軸としたクラウド型のマーケティングプラットフォーム。顧客データや購買履歴、Webへのアクセス履歴などさまざまな行動履歴データを統合・分析し、その結果をもとにユーザーをセグメント/ターゲティングすることで、効果的なマーケティングアクションにつなげる機能が備えられているという。今回の連携は、同サービスと「Synergy!」のメール配信機能との連携となり、プライベートDMPの分析結果に基づいてセグメントされたユーザーに対し、スムーズなOne to Oneメールマーケティングを可能にするものとなっている。両サービスの連携により、オムニチャネルに対応したデータドリブンなメールマーケティングや顧客ごとに最適化されたメール配信のオートメーション化などが実現されるという。
2016年02月09日
ヒッポリト星人&タイラントTシャツハードコアチョコレートは、円谷プロダクションとともに、ウルトラ兄弟を苦しめた「ヒッポリト星人」と、ウルトラ怪獣最強の呼び声も高い「タイラント」のコラボTシャツを発売した。■ヒッポリト星人(地獄星人チェリーレッド)目指せ地球侵略。打倒ウルトラ5兄弟。少年たちの憧れウルトラ兄弟を何とブロンズ像にしてしまった凶悪星人、それがヒッポリト星人。頭脳と戦闘能力を駆使し、あと一歩のところまでウルトラ族を苦しめた。ウルトラの父まで登場させたその実力は、未だにベストワンだという声も多い。ハードコアチョコレートとのコラボは、ヒッポリトのカラーリングにブロンズ像まで再現。あのシーンを今胸に。■タイラント(凶悪暴君シルバー)怨念ここに極まる。ウルトラ兄弟を苦しめた怪獣で真っ先に思い浮かぶのはこのタイラント。海王星で長男ゾフィーを、天王星で初代ウルトラマン、さらに土星でウルトラセブン、木星では帰ってきたウルトラマン(ウルトラマンジャック)をも倒し、遂に火星でウルトラマンエースまでも倒すという実力の持ち主。そしてウルトラ兄弟戦全勝に向けて、タロウのいる地球へ。まさにウルトラ怪獣最強の呼び声も高い「大宇宙の凶悪暴君」。それもそのはず、このタイラントは強力な怪獣(超獣)達の集合体なのだから。顔はシーゴラス、耳はイカルス星人、胴体はベムスター、背中はハンザギラン、両腕はバラバ、尻尾はキングクラブ、その強力な足はどくろ怪獣レッドキング。首を洗って待ってろよタロウ。ウルトラ兄弟最後の日は近い。「ヒッポリト星人(地獄星人チェリーレッド)」および「タイラント(凶悪暴君シルバー)」のTシャツは、いずれも3,800円(税込)。「ハードコアチョコレート 東中野ヘッドショップ」「ハードコアチョコレート オンラインストア」などで販売中となっている。(C)TSUBURAYA PROD.
2016年02月08日
Rustコアチームは1月21日(現地時間)、「Announcing Rust 1.6 - The Rust Programming Language Blog」において、プログラミング言語Rustの最新版となる「Rust 1.6」の公開を伝えた。Rustは安全性や実行速度、並列処理などに注力して開発が進められている新しいプログラミング言語。「Rust 1.6」ではlibcoreが安定化した点が特に注目される。Rustの標準ライブラリは「libcore」と「libstd」という2つの層で構成されている。libcoreは必要最小限のコア機能を実装した層で、この層やプラットフォームに依存することなく動作する。libstdはlibcoreの上に実装されるライブラリで、libcoreでは実装していないメモリアロケーションや入出力、並列処理などを実装している。Rustを使って組み込み向けのオペレーティングシステムを開発する場合などはlibstdを使わずにlibcoreのみを使うこともある。libcoreが安定版として認識されたことはRustを複雑ではないシステムのプログラミング言語として使用するにあたって大きな進展を見せたことを意味している。Rustコアチームではまだ実装すべき機能が残っているものの、今回libcoreが安定版になったことでlibcoreに関するエコシステムにとって大きな意味があると説明している。
2016年01月23日
米AMDは20日、"Fiji"コアを採用したハイエンドGPU「Radeon R9 Nano」の価格改定を発表した。これまでの希望小売価格649ドルから150ドル値下げし、改定後の価格は449ドルとなる。これに合わせて日本国内でも「適切な価格帯」で提供するという。「Radeon R9 Nano」は、2015年9月に発売したハイエンドGPU。グラフィックスメモリに広帯域メモリ「HBM」(High Bandwidth Memory)を搭載した"Fiji"コアを採用する。水冷クーラーを搭載したハイエンドモデル「Radeon R9 Fury X」と同じ4,096基のStream Processorを備えつつも、Mini-ITXサイズのゲーミングPCにも取り付け可能なコンパクトなカードサイズが特徴となっている。
2016年01月20日
ユニバーサル・スタジオ・ジャパン(大阪府大阪市)は1月19日、ギフト向けチケットの新たな券種「ギフト年間パス」「ギフト VIP 年間パス」の販売を開始する。ユニバーサル・スタジオ・ジャパンのギフト向けチケットは、2015年6月より販売を開始している。これまでは日程を1日選んで入場できる券種を展開していたが、今回は、有効期間内に何度でも入場できる年間パス2種を販売する。ギフト用年間パスの特典として、キャラクター「ミニオン」のパスケースとパーク内で使えるドリンク券も一緒にプレゼントできる。入学や就職など、新たな1年の始まりに最適なプレゼント、と同社。1日券と同じく、メッセージカードも付けられる。販売価格は、入場除外日のある「ギフト年間パス」が2万800円(子ども1万8,800円)、入場除外日のない「ギフトVIP年間パス」が2万9,800円(子ども1万8,800円)となる。なお、配送手数料は別途。オフィシャルWEBサイトにて販売を開始する※価格は全て税込
2016年01月19日
ユニリーバ・ジャパンは1月22日、「クッキーコアサンデー」(税込680円)を「BEN&JERRY’S(ベン&ジェリーズ)」の全店舗で発売する。同商品は、2種類のアイスクリームをカップに詰め、コア(芯)にソースを入れている「コアサンデー」をパワーアップさせたメニュー。ソースはチョコレートファッジとキャラメルから選ぶことができ、コアの中には2種類のクッキーチャンクを投入している。甘いソースとチャンクのゴロゴロ感が同時に楽しめるとのこと。
2016年01月18日
米AMDは14日(現地時間)、サーバ向けプロセッサ「Opteron」の新製品として、64bit対応のARM Cortex-A57コアを最大8基搭載した「Opteron A1100」を正式に発表した。Opteron A1100シリーズは、これまで"Seattle"という開発コード名で知られていたプロセッサ。ストレージやWebおよびネットワークのワークロード向けに開発され、バランスのとれたTCO(Total Cost of Ownership:総所有コスト)を提供するという。2014年1月に存在が明かされ、2014年7月にはOpteron A1100を搭載した開発用ボードを提供していたが、今回正式発表となった。CPUコアに64bitアーキテクチャを最大8基搭載するほか、4MBのL2、8MBのL3キャッシュを備える。メモリはECC対応のDDR3またはDDR4にサポートし、転送速度はDDR3が1600MT/秒、DDR4が1866MT/秒。このほか、インタフェースとして10Gigabit対応Ethernetを2基、8レーンのPCI Express 3.0、14基のSATA 6Gbpsポートを搭載する。セキュリティ面では、ARM TrustZoneテクノロジやセキュアブート用のコプロセッサを統合する。
2016年01月15日
フランスのアリアンスペースは12月3日(現地時間)、重力波望遠鏡の技術実証衛星「LISAパスファインダー」を搭載した、「ヴェガ」ロケットの打ち上げに成功した。LISAパスファインダーは2030年代に計画されている、重力波望遠鏡衛星「eLISA」の実現にとって必要となる、新しい技術の試験を目的としている。ロケットは日本時間12月3日13時4分(ギアナ時間同日1時4分)、南米仏領ギアナにある、ギアナ宇宙センターのヴェガ発射台から離昇した。ロケットは順調に飛行し、打ち上げから1時間45分33秒後にLISAパスファインダーを分離し、軌道に投入した。ヴェガはアリアンスペースが運用する、小型の固体ロケットである。また液体推進剤を使う第4段も搭載でき、衛星を正確な軌道に投入することが可能。2012年2月13日に1号機が打ち上げられ、以来今回を含めて6機が打ち上げられており、すべて成功している。○LISAパスファインダー欧州宇宙機関(ESA)と米航空宇宙局(NASA)では、2030年代を目標に、低周波重力波を観測する宇宙望遠鏡「eLISA」(Evolved Laser Interferometer Space Antenna)を打ち上げることを計画している。LISAパスファインダーはその開発に必要な、新しい技術や装置の実証試験をするために開発された。重力波とは、時空が振動し、光の速度で伝播する現象のこと。1916年にアインシュタインが発表した一般相対性理論の中で予言されたが、これまで間接的にしか存在が示唆されておらず、直接観測に成功した例は無い。もし重力波の直接観測に成功すれば、一般相対性理論の正しさが再び証明されると同時に、重力波によって宇宙を観測する「重力波天文学」という分野が生まれることが期待されている。重力波望遠鏡は地上でも造ることができ、日本でも11月に「KAGRA」という重力波望遠鏡が完成した。しかし、重力波の中でも低周波のものは、地球上では地面が振動があるため観測が難しいことから、eLISAのように望遠鏡を宇宙に打ち上げる必要がある。ただし、宇宙で動く重力波望遠鏡を造って動かすためには、きわめて高い技術が必要となる。eLISAにも数多くの先進的な技術が使われることになっており、実現にはLISAパスファインダーによる実証が必要不可欠となっている。なお、LISAパスファインダーはあくまで技術実証機であるため、重力波を検出することはできない。検出や観測を行うには、eLISAの完成と打ち上げを待つしかない。LISAパスファインダーの打ち上げ時の質量は約1900kgで、そのうち衛星本体は約480kg、ロケットから分離後、目的地の軌道まで行くための推進モジュールは約1420kgを占めている。製造はエアバス・ディフェンス&スペース社が担当した。設計寿命は約1年が予定されている。LISAパスファインダーは現在、地球に最も近い高度が213km、最も高い高度が1482km、赤道からの傾きが6度の軌道に入っている。このあと推進モジュールを使って軌道を上げ、地球から約150万km離れた太陽・地球系のラグランジュ第1点(L1)に入り、運用が始まることになっている。
2015年12月05日
●Cortex-A35はどういった立ち位置のコアなのか?基調講演では簡単に性能面が(Cortex-A7と比較する形で)示された「Cortex-A35」だが、もう少し細かい話をご紹介したいと思う。まず製品セグメントから。Photo01が各々の製品分け、という形になる。実を言えばこの図は厳密にはCortex-A9とCortex-A53の間にARMv7-A(*)としてCortex-A12が入った形になる"はずだった"。ところがCortex-A12は発表こそされたものの、あまりニーズが無いということで、2014年10月にCortex-A17に統合される形になってしまい、この結果ARMv7-A(*)と書いた、32bitを超えるLPA(Large Physical Addressing)を利用できるHigh Efficency向けのARM v7-aベースのコアがなくなってしまった。実際に製品動向を見ると、Cortex-A15の動作周波数を落として使う、なんてケースがしばしば見られたのは、Cortex-A7とCortex-A15/17の間にかなりの性能ギャップがあったためである。これもあってか、ARMv8-Aでは当初からCortex-A57とCortex-A53が比較的近い性能で登場しており、特にこのCortex-A53はかなり広く利用されたのだが、64bitの裾野が広がってきた(つまりOSやアプリケーションの64bitへの移行が進んだ)結果、性能はもう少し低くても良いから省電力で、かつ64bitにも対応できるプロセッサが望まれるようになった、というのは自然な成り行きであり、これに向けて投入されたのがCortex-A35という訳だ。そのCortex-A35、絶対性能という意味ではかならずしも高くない。むしろ性能/消費電力比や性能/エリアサイズを高める事を優先したコアであり、このため基本はまるでCortex-A7を64bit化したような構成になっている(Photo02)。もっともこれに関しては「設計を見るとかなりCortex-A7に近いが、別にCortex-A7のパイプラインを持ってきたわけではなく、ScratchからCPUのパイプラインを設計するにあたり、ターゲットとした性能/回路規模/消費電力に見合う形で設計をした結果、似たような構成になった」(ARMのNandan Nayampally氏)という話であった。実際にはパイプラインの構造などはCortex-A7のものを参考にしつつ、ここにCortex-A53などでインプリメントされたARMv8-Aのエッセンスを統合した、というニュアンスの発言であった。では具体的にどの改善されたかということでまずは電力比で言うと、当初のCortex-A7に比べて同一周波数で20%程度、28nmで最適化を行ったCortex-A7と比較しても10%程度の省電力化が実現したとする(Photo03)。またエリアサイズを25%縮小し、効率を25%改善したとする(Photo04)。さて、ここからもう少し内部の話を。Photo05が発表されたパイプライン構成である。パイプライン段数としてはALUの場合に8段とされている。ちょっとこれだと判りにくいので、比較対象のためにPhoto06にCortex-A7のパイプラインを示すが、おおむね各ステージは同程度の段数と思われる。ちなみにCortex-A7も一見するとDual Issuに見えるが、同時に実行できる命令は非常に限られており、実際にDual Issueで実行可能なのはALU/moveとbranch/call程度になっている。これは例えばGitHubに置かれたGCCのCortex-A7用のconfig-a7.mdを眺めると明白で、Dual issueで実行可能なのはALU instruction with an immediate operandALU instruction with register operandsの場合のみで、Callについてはolder instructionsや他の分岐命令との組み合わせはDual issueでは実行できないとしている。残念ながらCortex-A35用のConfigはまだ公開されていないが、インタビューで聞いた範囲ではほぼこの制約がそのままCortex-A35にも適用される感じであった。●Cortex-A7と比べてると大きく性能が改善されたFPUとNEONさて、以下個別に。まずFetch→Decodeの範囲であるが、これはCortec-A7にかなり近い構成に思える。ちなみにCortex-A7の場合、Decodeは完全2命令の同時Decodeが可能となっていたが、Cortex-A35ではこれがもう少し低くなっている可能性がある。実行段は極めて限定的なDual-Issueなので、実際には1.5命令/cycleまで行かないだろう。それを考えると、Decodeはもう少し動作速度を落として動かしても十分に思えるからだ。もっとも2命令/cycleのままにして、Queueが一杯になったら停止する、というインプリメントとどちらが消費電力が少ないのかは微妙なところで、案外相変わらず2命令/cycleでDecodeが行われているのかもしれない。またIssueが無いのは、Decode段に統合されているように思える。実際の所Queue→Decodeで2 Stageというよりは、Queue+Early Decodeで1 Stage、Late Decode(Issue含む)で1 Stageという感じだ。また分岐予測に関しては、さらに効率化を図ったとされている。具体的にはCortex-A35の改善点として、4KBのConditional Predictorと、256 entryのIndirect Predictorを搭載するとしている。Conditional PredictorはいわゆるBHT(Branch History Table)の事で、Indirect PredictorはBTAC(Branch Target Address Cache)ではないかと思うが、例えばBTACはCortex-A7だと8 entryだから、大幅にこれを強化した模様だ。もっとも、それでどの程度Efficiencyが向上したのかは今の所公開されていない。Load/Storeに関しては、遂に自動Prefetchが搭載されるようになった。ただこれはあくまでもアドレスベースの、それも簡単なものに留まっており、あまり複雑な事はやってないとの事。このあたりは性能とダイエリア&消費電力のバランスなので、あれこれ搭載すればいいというものでもないのだろう。ちなみに説明の中にはInteger ALUに関するものは割愛されているが、これはおおむねCortex-A7と変わらないと思われる。もちろん64bit命令をサポートするから、Cortex-A7そのままでは済まないと思うが。恐らくExecuteが2 stageで、それにWritebackが入ってトータル3 stageと思われる。あとこのスライドには入っていないが、512 entryのMain TLBとは別に、10 entryのμTLBが別に用意されており、こちらを利用できる場合にはLatencyがかなり減るとされている。L2回り(Photo09)に関しては、基本効率を改善したということしか明らかにされていない。ただL2のサイズは128KB~1MBとされており、Cortex-A53が最大2MBを搭載できるあたりと比べると、より低い性能レンジに合わせた構成になっていることは間違い無い。Cortex-A7がやはり最大1MBというあたりからもこれは明白である。Cortex-A7と比べると大きく性能が改善されたのが、FPU/NEONである(Photo10)。ここにもあるように、単精度で2倍、倍精度で5倍のスループットが実現されているとする。バスI/FはAXI4/AMBA4 ACE/AMBA5 CHIが搭載されており、必要ならACPがさらに利用できる(Photo11)。最後がGovernor(ガバナー)である(Photo12)。これだけ見ると何をやっているのか良く判らないかもしれないが、これは省電力のところで説明したい。次がいくつか性能に関するもの。まずPhoto13は見ての通りで、同じプロセス/動作周波数で32bitのアプリケーションを稼動させた場合でも16%ほど高速であり、また同じ28nmでも速度よりに振ると2GHzまで性能が上げられ、その場合84%高速になるとする。とりあえず動作周波数が違うと比較が難しいので、同一周波数上で性能比較を行ったのがこちら(Photo14)。基調講演で出てきた6~40%の性能改善はこれを基にしたと思われる。またL1/L2の性能改善により、メモリアクセスの性能を大幅に改善したとしており(Photo15)、これも全体としての性能改善に寄与している。また暗号化アクセラレータを搭載したことで、セキュリティ関連が大幅に高速化された(Photo16)。●省電力化を実現できた大きな理由とは?さて次が省電力関連である。Cortex-A35がCortex-A7と比べて省電力化を実現できた理由の大きな部分は、新しい省電力機構を搭載したことにある(Photo17)。まずQ-Channelであるが、これはAMBA/AHBのSideband(Ian Smythe氏)という形で実装される(Photo18)。なにをやっているか、というとCPUの動作状態がQ-Channelを経由して外部のパワーコントローラに通知されており、ある程度以上アイドル状態が続いたと外部のパワーコントローラが判断すると、Q-Channelを経由してCPUに対して(この後説明する)リテンション状態に入るように指示する仕組みだ。これはパワードメインごとに用意されており、Cortex-A35の場合はNEONで1つ、NEON以外のCPUコアで1つという形になる。ちなみにPhoto05を見るとL2やSCU/ACPもコアの一部に見えるが、こちらは実装としてはコア外になるので、実際にはPhoto19の様になる。さてこの2つのパワードメインに対して新しく用意されたのがRetention Modeである。これは何かというと、復帰のために必要な最低限のプロセッサステートを保持しつつ、回路の電圧を落とすというもので、サスペンドとアイドルの中間に位置するものになる(Photo20)。この結果として、電源完全カットに近い程度までリーク電流を減らしつつも、完全電源Offよりも迅速に復帰が可能になるという仕組みだ(Photo21)。このRetention Modeの制御を行うのが、先に説明したGovernorである(Photo22)。Governor(とRetentionで利用される保持領域)は原則常に電源ONで、Q-Channelからの指令を受けてコアに対しての電圧制御を行う事になる。次がスケーラビリティの話。Cortex-A35は最大4コアまでの構成が可能である(Photo23)。ではbig.Littleは? というと、「任意の64bitのCortex-Aシリーズでbig.LITTLEを構成できる」(James Bruce氏)という話で、(意味があるかどうかは別にして)例えばCortex-A35とCortex-A53でも、Cortex-A35とCortex-A72でもbig.LITTLEを構成できるとの話だった。またCortex-A35自身がバリュー向けのスマートフォンのみならずウェアラブルまでターゲットにしていることもあり、最小構成だと28nmで0.4平方mmまでエリアサイズを縮小できるとしている(Photo24)。実はこの2つは、同じ28nmといっても利用するプロセスも最適化方法も異なっており、左は性能優先で恐らく28nm HPMあたり、右はエリアサイズ優先で28nmのLPないしULPを使ったものの様だ。このあたりは当然ターゲットとする周波数にも関係してくる。それがPhoto25で、LPなりULPを使うと動作周波数は100MHz程度まで落ちる代わりに6mW未満で動作し、逆にHPMあたりを利用すると90mWで1GHzを実現できることになる。この6mW未満、というのはちょっと高速なMCUと同レベルであり、またエリアサイズが0.4平方mmというのもやや古めのプロセスを利用したMCU並である。要するにCortex-A35は(2014年に発表したCortex-M7とあわせて)MCUとMPUの性能面での境目を無くすという同社の遠大なストラテジーを担う、結構重要な製品と考える事もできる。搭載製品が投入されるのは早ければ2016年末であり、当初はスマートフォンのエントリーモデル向けであろう。ただし2016年中には既存のCortex-A5/A7ベースの組み込み向けコントローラの代替としてこれを採用したSoCがラインアップされはじめるだろう。いよいよ組み込みそのものが64bitに本格シフトの準備が整いはじめた訳だ。
2015年11月25日
ハードコアチョコレートと小学館集英社プロダクションは、白土三平氏が壮大なスケールで描く戦後日本マンガ史の金字塔『カムイ伝』のコラボレーションパーカー2種を同時発売した。1964年、日本に誕生した名作漫画『カムイ伝』。先行して発売されたハードコアチョコレート×「カムイ伝」Tシャツシリーズの人気デザインが、新たにパーカーとなって登場した。日本が産んださまざまなカルチャーにおいて重要な位置づけとされる名作を、ハードコアチョコレート流にカルト・クラッシックスと位置づけ、現代風にリデザイン。語り継がれるべき伝説が新たなウェアーとなって再現されている。■カムイ伝 ZIPパーカー - KAMUI THE NINJA STORY EDITION (憑移しバーガンディ)『カムイ伝』で描かれるもう一つのドラマ「動物たち」の生きる有様をバックプリントに集約。背中で「生」を感じられる仕様となっている。■カムイ伝 ZIPパーカー - CHAOS EDO EDITION (黒鍬ヘザーグレー)混乱する江戸をテーマとして民衆と家老が描かれ、一触即発の世界を描くバックプリントが圧巻の一枚。価格はいずれも8,200円(税込)。「ハードコアチョコレート 東中野ヘッドショップ」や「ハードコアチョコレート オンラインストア」ほかにて販売されている。(C)白土三平
2015年11月05日
ハードコアチョコレートと小学館集英社プロダクションは、白土三平氏が壮大なスケールで描く戦後日本マンガ史の金字塔『カムイ伝』のコラボレーションTシャツを4種同時発売する。1964年に誕生した『カムイ伝』は、江戸時代の様々な階級の人間たちを深く描きだす戦後日本マンガ史の金字塔ともいえる作品で、重層的に紡ぎ上げられた物語は、巨匠・白土三平氏のライフワークといっても過言ではない。そんな『カムイ伝』をモチーフにしたTシャツ4種がリリースされる。■「カムイ伝/KAMUI THE NINJA STORY(雀落しバーガンディ)」もう一つのドラマ「動物たち」の生きる有様をバックプリントにあしらった「雀落しバーガンディ」は、背中で「生」を感じられる仕様。■「カムイ伝/THE LEGEND OF KAMUI(飯綱落しラグラン)」シリーズ唯一のラグランボディを採用した「飯綱落しラグラン」。森の中で颯爽と活躍する主人公・カムイの姿がプリントされている。■「カムイ伝/CHAOS EDO(常風ホワイト)」混乱する江戸がテーマの「常風ホワイト」。フロントには江戸で暗躍する主人公・カムイの姿、バックには民衆と家老がプリントされ、一触即発の世界を描いている。■「カムイ伝/KONOMATO THE GENTLEMAN THIEF(空蝉ブラック)」フロントに失意の草加 竜之進(くさか りゅうのしん)をプリントした「空蝉ブラック」。バックプリントには世の矛盾を抱え、木の間党首領となる男の姿が描かれている。Tシャツの価格は各4,100円(税込)。「ハードコアチョコレート 東中野ヘッドショップ」「ハードコアチョコレート オンラインストア」ほかにて販売される。(C)白戸三平
2015年09月25日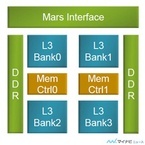
(前編はコチラ)○XiaomiコアのフロントエンドXiaomiコアのフロントエンドは、32KBのL1命令キャッシュを持ち、分岐予測は2048エントリのBTB(Branch Target Buffer)とTAGE(TAgged GEometric history length)分岐予測を用いている。また、512エントリの間接分岐予測器と、48エントリのリターンスタックを持っている。そして、Loop Detectというブロックを持ち、ループの全命令が命令バッファに収まっている場合は命令キャッシュ側から命令を読まなくて済むようになっている。この機構は、少し前のIntelのCoreプロセサでも採用されていたことがある。多種の分岐予測機構を持ち、Loop Detectを行うなど、Xiaomiコアは、かなり高級なメカニズムを実装している。○XiaomiコアのOut-of-Order実行機構Xiaomiコアは1サイクル最大4命令をデコードすることができ、また、最大4命令をリネームしてディスパッチすることができる。リオーダバッファは160命令を保持、物理レジスタは192個とXeonなどのハイエンドコアに劣らない量のOut-of-Order実行資源を積んでいる。Xiaomiコアは4つの整数演算ユニットを持ち、その内の1つはマルチサイクルの整数演算や分岐命令の処理が行える。浮動小数点演算は64bitの演算器を2個持ち、128bitのSIMD演算を行う場合は2個の演算器を繋いで処理するようになっている。ロード/ストアユニットは24エントリのキューを持ち、32KBのL1データキャッシュをアクセスする。ロードからそのデータを使えるようになるまで4サイクルというのはちょっと遅い感じであるが、致命的ではない。○キャッシュコヒーレンシ機構Marsシステムでは、Hawkと呼ぶキャッシュコヒーレンシプロトコルで全キャッシュのコヒーレンシが維持されている。Hawkはパケットを使うディレクトリベースのMOESIライクのコヒーレンシプロトコルであるという。○パネル間を接続するメッシュネットワークMarsチップ内のパネル間の接続はルーティングセルを使った4×2のメッシュ接続になっている。この接続に限ればルーティングセルは3ポートで良いが、実際には次の図のようにルーティングセルは6ポートのスイッチになっている。残りの3ポートはIOUやMIU、あるいはカスケードと書かれており、I/Oやメモリへの接続や他のチップとの接続に使われると思われる。ホップあたりの遅延は3サイクルでルーティングセルあたりのバンド幅は384GBとなっている。但し、これは6ポートのIn/Outの合計と考えると、1リンクでは32GB×2ということになる。○Cache and MemoryチップCMCチップは16MBのL3キャッシュと2チャネルのDDR3 DIMMチャネルを集積している。従って8個のCMCチップの合計では128MBのキャッシュを持つことになる。次の図ではDDR3-800となっているが、これはDDR3-1600の間違いで、CMCあたりのメモリバンド幅は25.6GB/sとなる。CMCとCPUチップの接続は高速シリアル伝送ではなく、独自の並列伝送のインタフェースを使っている。シリアル-パラレル変換の時間ロスが無く高速というのが理由であるが、信号だけでも1024本であり、グランドの接続を含めると1500~2000ピンが必要となる。この接続が、Marsチップ全体で3000ピンを必要とする主因になっていると考えられる。○メモリアクセスのバンド幅とレーテンシローカルのL1キャッシュをヒットした場合は2サイクル、ローカルのL2キャッシュヒットは8サイクル、同一パネルの他方のL2キャッシュのヒットは20サイクル。直結されているCMCのL3キャッシュヒットは36サイクルでメッシュを経由しないでCMCを通してDDR DIMMをアクセルする場合は70サイクル程度のアクセスタイムとなる。メモリの実効読み出しバンド幅は12.8GB/s、実効書き込みバンド幅は6.4GB/sと書かれており、DDR3-1600のピークバンド幅である25.6GB/sと比べると、実効バンド幅は、読み出しは1/2、書き込みは1/4となっている。これはパネルとネットワークは2GHzで動作し、CMCは1.5GHz動作とした場合の値である。(後編はコチラ)
2015年09月02日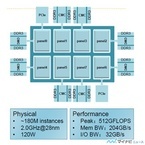
今年のHot Chips 27でもっとも意外感のあった発表は、中国のPhytium Technologyという会社の「Mars」と呼ぶ64コアのARMv8プロセサの発表であった。発表を行ったのは同社の研究部長のCharles Zhang氏であるが、米国のビザが得られなかったため会場には来られず、スライドと電話での発表となった。Phytiumは2012年に創立された会社で、広州と天津にオフィスを持つ。同社のWebサイトでは高性能サーバ向けのマイクロプロセサやアクセラレータ、リファレンスボードなどのテクノロジを供給すると書かれている。しかし、具体的にどのような開発をやっているのかはまったく情報が無く、今回のHot Chipsが初めての発表である。同社はハイエンドのMarsと呼ぶプロセサとクラスタ型サーバ用の「Earth」というプロセサの開発を行っているが、今回の発表はMarsに関するものである。○ARMv8準拠の64コアプロセサMarsのコアはARMからARMv8のアーキテクチャライセンスを受けて開発しており、命令レベルではARMv8準拠である。Marsチップは、8コアをまとめたパネルという単位を8個使って、全体で64コアになっている。そして、各パネルにはCMCと呼ぶ16MBのL3キャッシュとDDR3-1600のDRAMチャネルを2チャネル集積するチップが接続される。つまりフル構成では、CPUを含めて、17チップと最低16枚のDIMMを必要とするという大きなシステムとなる。Marsチップは28nmプロセスで作られ、2.0GHzクロックで動作し、消費電力は120Wである。集積度は約180Mインスタンスと書かれているが、各インスタンスがどの程度のトランジスタ数であるのかは不明で、SRAMマクロも2入力NANDも1インスタンスとするとあまり意味のない数字である。浮動小数点演算性能はピークで512GFlops、メモリバンド幅は204GB/s、I/Oバンド幅は32GB/sとなっている。DDR3を16チャネル持っているのでメモリバンド幅は大きく、メモリバンド幅と演算性能の比であるB/F比は約0.4Byte/Flopであり、最近のプロセサとしては比較的高い値になっている。なお、現在は設計が終わった状態で、まだ、テープアウトされていないとのことで、クロック周波数や消費電力は、同社の見積もりである。○Xiaomiコアは独自設計次の図はパネルの内部構成を示すもので、8個の「Xiaomi」と呼ぶコアを集積している。ARMv8のアーキテクチャライセンスを受けており、Xiaomiコアは64bit ARMアーキテクチャのコアとなっている。アーキテクチャライセンスの場合は、ARMの論理設計には縛られず、独自に論理設計を行うことが認められており、高性能コアを作ることができる。Xiaomiコアは、4命令フェッチ、デコード、ディスパッチのOut-of-Orderと書かれており、本家のARM Cortex-A72が3命令デコードであるのに比べて、より並列度の高い設計になっていることが注目される。パネルは4個のXiaomiコアが2MBのL2キャッシュを共用し、キャッシュのコヒーレンスを維持するDirectory Control Unit(DCU)に接続されている。これが2組あり、パネル全体では8コア、4MB L2キャッシュという構成になっている。そして、ルーティングセルを経由して他のパネルやメモリと繋がっている。パネルの大きさは6mm×10.6mmとなっており、1個のコアあたり約8mm2の面積を占めている。これは、TSMCの16FF+プロセスで作ったCortex-A72が1.15mm2と言われるのと比べると、微細化の程度の違いを補正しても3倍程度の面積と思われる。Xiaomiコアは、32KBのL1命令キャッシュと32KBのL1データキャッシュを持ち、整数/分岐、整数×3、浮動小数点×2、ロード/ストアの計7本の実行パイプラインを備えている。そして、4つの命令デコーダを持ち、最大4命令を並列に処理できる構成になっている。(中編はコチラ)
2015年09月01日
Freescale Semiconductorは、ARM Cortex-A7およびCortex-M4コアを搭載したアプリケーションプロセッサ「i.MX 7シリーズ」を発表した。同シリーズは、i.MX 7Soloファミリとi.MX 7Dualファミリの2ファミリが第一弾製品としてラインアップされており、いずれも最大1GHz動作のCortex-A7と、最大266MHz動作のCortex-M4コアを搭載。コア電力効率は最大15.7DMIPS/mWとするほか、LPSR(低消費電力状態保持)モード時の消費電力250μWを提供するとしている。また2種類のコアは、必要に応じて個別に電源投入が可能。第4世代EPDコントローラも統合しており、これまで継続して行ってきた電子書籍端末市場向けサポートも継続されている。さらに同社では、コンパニオン・チップであるパワーマネジメントIC(PMIC)「PF3000」を組み合わせることで、ウェアラブル・コンピューティングやIoTに向けたセキュアかつ高い電力効率の製品を実現できるようになるとしている。すでにi.MX 7はサンプル出荷を、PF3000は量産出荷をそれぞれ開始しており、評価ボードなども利用可能となっている。
2015年07月10日
米ジュニパーネットワークスは6月25日(現地時間)、「コンバージド・スーパーコア」アーキテクチャを拡張し3Tbpsのシステム容量をサポートするコア・ルーター「PTX1000」を発表した。提供開始時期は2015年第3四半期。新製品は2ラック・ユニット(RU)サイズであり、同社が2015年3月に発表したカスタム・シリコン「ExpressPlus」チップセットを利用してパフォーマンスと効率を高めているとのこと。さらに、クラウド・サービスへのアクセス・スピード向上を目的とした分散型ピアリングへのニーズをサポートする、適切なサイズのプラットフォームを、サービス・プロバイダに提供するとしている。同製品は、同社の既存製品である「PTX3000」や「PTX5000」と同様、IPおよびMPLS(Multi-Protocol Label Switching)パフォーマンス・アプリケーションに「ExpressPlus」を採用。28nmによる新型チップは、5x100Gインタフェースに対応し、3Dメモリ・アーキテクチャを活用して消費電力と設置スペースの要件を抑えているという。さらに、同製品は柔軟性に優れるというポート・インタフェース・オプションを備え、投資保護を最大化してスムーズなアップグレード・サイクルを実現するとのことだ。
2015年06月29日
Synologyは12日、2ベイNASサーバとして、クアッドコアCPU搭載モデル「DiskStation DS715」とデュアルコアCPU搭載モデル「DiskStation DS215+」を発表した。6月中旬から出荷を開始し、価格はオープン、店頭予想価格(税込)は全社が64,000円前後、後者が55,000円前後。○DiskStation DS7151.4GHzのクアッドコアCPUと2GBのメモリを搭載する2ベイNASサーバ。HDDは別売となり、最大で8TBドライブ×2台の16TBをサポートする。OSには直観的な操作が可能な「DiskStation Manage」を採用し、リード最大216MB/s、ライト最大142MB/sの高速転送に対応。専用のハードウェア暗号化エンジンを備え、暗号化したデータであってもリード最大205MB/s、ライト最大77.62MB/sで転送できる。インタフェースにはGigabit Ethernet対応有線LAN×2基を搭載し、フェイルオーバーとLink Aggregationに対応。LAN接続が切断した場合でも、ネットワークの機能を続行する。RAID機能は、RAID 0 / 1 / 5 / 6 / 10 / JBOD / Basic / Synology Hybrid RAIDで、最大ユーザーアカウント数は2,048だ。アドオンパッケージによる機能拡張に対応しており、クラウドストレージや同期、DNSサーバ、iTunesサーバ、DLNAサーバといった機能を追加できる。また、最大で30台のIPカメラのホストとしても利用可能。CPUはAnnapurna Labs Alpine AL-314(1.40GHz)、メモリはDDR3 2GB、最大容量は8TB×2台。92mmの冷却ファンを内蔵。USB 3.0×2、eSATA×1を装備し、本体サイズはW103.5×D232×H157mm、重量は1.69kg。○DiskStation DS215+デュアルコアCPUのAnnapurna AL-212(1.4GHz)と1GBメモリを搭載するモデル。転送速度はリード最大209MB/s、ライト最大139MB/s。暗号化エンジンを搭載し、暗号化したデータの転送速度はリード最大145MB/s、ライト最大71MB/sとなる。対応RAID機能は、RAID 0 / 1 / JBOD / Basic / Synology Hybrid RAID。そのほかの機能や仕様はほぼ共通。
2015年06月14日
長年付き合っているカップルだと、意外と困るのがデート先。いろんなところに行きつくしていて、彼に「行きたいところある?」と聞かれても、「うーん、どこかあったっけな~?」なんてこともしばしば。そこで、「東京・ミュージアム ぐるっとパス2015」(一人2,000円)を買ってみました。これは、都内78カ所の美術館・博物館・動物園などの入場券または割引券がつづられたもの。対象施設は、上野周辺エリア/東京・皇居周辺エリア/目黒・港・世田谷エリア/新宿・練馬・池袋・王子エリア/両国・深川・臨海エリア/多摩エリアの6エリア。ということで実際に、「ぐるっとパス」を使って上野エリアでおトクにデートしてみることに!まず向かったのは、不忍池すぐにある「下町風俗博物館」。その名の通り、下町の歴史や文化がわかる博物館です。こちらは通常、一般300円の入場料ですが、ぐるっとパスを使えば無料で入場できます。館内には、当時を再現した銭湯の番台や駄菓子屋などのセットがたくさん。しかも写真撮影OKなのがうれしい。ちなみに毎月第1・第3日曜日には、現存する昭和の紙芝居の実演もやっています。おそらく小学生ぶりに紙芝居を見ましたが、意外と大人向けの内容で大笑い。ほっこりまったりするデートとなりました。これから夏本番、暑くなったらちょっとひと休憩がてら見学というのにもおすすめ。つづいて向かったのは、「恩賜上野動物園」。個人一般だと600円かかる入場料が、こちらもぐるっとパスで無料に。やはり、大人になっても動物園に来たらはしゃいでしまいますね!それだけではなく、小さい子どもが「帰りたくない!」と大泣きしてお母さんに抱きついている姿をみて、「かわいいね~」とほのぼのする場面も。こういうことがきっかけで、結婚をイメージすることもありそう。最後に訪れたのは、「東京都美術館」。こちらでは企画展の入場料1,000円が無料になりました。特別展は一般料金の100円引となります。さまざまな画家の書いた絵を見て、感性を豊かにするのもいいかも。また美術館は室内なので、梅雨などの雨の季節でも快適にデートすることができますね。本来この3ヵ所を巡ると、1,900円分の入場料がかかることになりますが、この日だけでもほぼ元をとったようなもの! ちなみに彼は「来週は、東京・皇居エリアに行こうか」と、次回のデート先を提案してくれました。都内のあらゆるエリアを散策するきっかけにもなりますし、出先でカフェや良い雰囲気の居酒屋などを探すのもまた楽しいですよね。「ぐるっとパス」使用期限は、使い始めた日から2カ月間。なので、しばらくは美術館巡りデートになりそうです(笑)。
2015年06月11日
アクティブコアは5月11日、クラウド上でビッグデータ分析を活かした事業支援を行うコアエンジン「activecore marketing cloud(アクティブコア マーケティングクラウド)」に、見込み顧客の絞込みに必要なデータ分析機能を強化し、的確なスコアリングによりBtoB向け営業支援を行える機能を搭載した製品を発表した。提供開始は6月10日、価格は初期費用が50万円から、月額費用が25万円から(いずれも税別)。新製品は、統合したデータを顧客単位で紐付けながらデータ分析を行えるよう、見込み顧客の絞り込みに必要なデータ分析機能(スコアリング)を強化。データ分析に関する専門知識が無くても、同一画面でスムーズに分析とアクションを行える機能の実装(特許番号 5669330号)により、マーケティング担当者だけで個々の顧客に対する相関分析を行いながら、的確なスコアリングにより抽出したデータを基に、レコメンドやターゲティングといった一連の作業が可能という。Web行動履歴及び企業内データでスコアリングし、データを別々のプラットフォームから集める必要が無いため分析時間を短縮としている。また、特別な統計解析やマイニング・ツールが必要無く、コストと手間を削減可能だという。これらにより、BtoB向けの営業支援を強力に推進できるようになったとしている。同製品と既存製品とを比較すると、既存製品では顧客軸で統合していない個々のデータで分析し、別々のツールまたはシステムを連動させてアクションする必要があったが、同製品では統合したデータから顧客スコアリングをしてアクションできるという。見込み顧客のスコアリングとアクションでは、成約につながったWeb行動データと営業データによるスコアリング対象項目の決定、見込み顧客をスコア化してマイニング(データ分析)した結果からスコアリング、アンケート/ダウンロード/デモ視聴から見込み顧客を識別してモニタリング・アクションにつなげるといった行動が可能になるとしている。
2015年05月11日
米AMDは6日(現地時間)、投資家向け説明会を開催し、2015年から2016年における同社製品のロードマップを公開した。新x86コア「Zen」(開発コード名)を搭載したデスクトップ向けハイエンドCPU「AMD FX」を2016年に投入するとしている。AMDが公開したロードマップによると、2015年のデスクトップ向けプロセッサは、2014年に引き続き"Vishera"(開発コード名)ベースの「AMD FX」と、"Kaveri"(開発コード名)ベースの「AMD Aシリーズ」を提供するが、2016年はハイエンド向けに新コア"Zen"を採用した「AMD FX」、メインストリーム向けに第7世代の「AMD Aシリーズ」を投入するという。一方、モバイル向けプロセッサは既報通り、2015年に"Carrizo"と"Carrizo-L"(開発コード名)を投入する。さらに2016年にはモバイルでも第7世代「AMD Aシリーズ」を提供するとしている。Zenは新設計のCPUコアで、これまでよりもパフォーマンス向上に焦点が当てられた製品とみられる。AMDによると、"Carrizo"のCPUコアである"Excavator"(開発コード名)コアと比較して、IPC(Instruction per Clock)が40%向上するという。さらに、次世代「AMD FX」では、同時マルチスレッディング(SMT:Simultaneous Multithreading)やDDR4メモリがサポートされる。Zenはサーバ向けCPU「Opteron」でも採用が予定されている。また、第7世代「AMD Aシリーズ」は電力当たりの性能を高めた製品で、HSA 1.0とOpenCL 2.0に対応するほか、DDR3メモリとDDR4メモリの両方をサポートするという。プラットフォームも現在の「AM3」や「FM2+」から刷新し、次世代「AMD FX」や第7世代「AMD Aシリーズ」では「AM4」に統一する。このほか、サーバ向けやハイパフォーマンスが要求される組み込み向けの64bit ARMベースの「K12」に関しては2017年の投入となるという。
2015年05月07日
一本松海運はこのほど、道頓堀川開削400年を記念した企画パス「道頓堀クルージングパス」(4,000円・税込)を発売した。同社は、大阪ミナミ・道頓堀を中心に大阪府大阪市内でクルーズ船などを運航している。今回発売する「道頓堀クルージングパス」は、道頓堀川で運航する人気のクルーズを割引料金で楽しめる企画パスとなる。同パスで乗船できるクルーズは、「落語家と行く なにわ探検クルーズ」「アクアmini 大阪城・道頓堀コース」(湊町・太左衛門橋船着場からの乗船のみ)、「とんぼりリバークルーズ」「とんぼり River JAZZ Boat」の4つ。通常料金は計6,900円となる。同パスで期間中に各クルーズに1回乗船できるだけでなく、同パスに付属する「道頓堀あきんどパス」により道頓堀・ミナミエリアの人気店舗の特典も利用できるとのこと。同パスの販売期間は8月31日までで、利用期間は5月11日~11月30日。販売場所は、大阪水上バス大阪城港・湊町船着場・太左衛門橋船着場・一本松海運となる。なお、取り扱いは大人のみ。
2015年04月30日
コトブキヤが展開するプラモデル「アーマード・コアV ヴァリアブル.インフィニティ.」(ACV V.I.)シリーズより、『MATSUKAZE mdl.2 拠点防衛仕様』が2015年8月に発売されることが決定した。現在「コトブキヤオンラインショップ」にて予約受付中で、価格は20,304円(税込)。「ACV V.I.」シリーズ初のタンク型機体となる『MATSUKAZE mdl.2 拠点防衛仕様』は、機体全長22cmに及ぶ圧倒的なボリュームとハイディテールな造形を堪能できるプラモデル。新規造形となる頭部と脚部は、ゲーム中同様の高密度感を忠実に再現しており、履帯パーツに軟質性のプラ素材の採用など、リアルな質感と組み立てやすさを両立している。付属品には、オートキャノン「AM/ACA-127」×2とオーバード・ウェポンの接続に対応した専用アタッチメント、V.I.シリーズ以外のコアパーツが接続可能になるアタッチメントパーツを用意。砲身部は折り畳みギミックがあり、パーツ差し替えでSHOULDER UNIT使用時の形態も再現できるという。また、頭部、コア、腕部、脚部の各部位はゲーム中と同様に組み換えが可能なため、他の「ACV V.I.」シリーズの機体と組み合わせて、さまざまなカスタマイズも可能となる。商品価格は20,304円(税込)で、現在「コトブキヤオンラインショップ」にて予約受付中。商品の発売および発送は、2015年8月を予定している。なお、「コトブキヤショップ」(秋葉原館、大阪日本橋、オンラインショップ)限定特典として、サンドカラーのハングドマン頭部と脚部が再現できるアペンドパーツが用意されている。(C)2015 BANDAI NAMCO Entertainment Inc. / (C)1997-2013 FromSoftware, Inc. All rights rserved.
2015年04月22日
アクティブコアは4月13日、クラウド上でビッグデータ分析を活かした事業支援を行うコアエンジン「activecore marketing cloud」に、クラスタ分析とアクションを同一画面で行える機能が搭載された製品を、5月7日より提供開始すると発表した。activecore marketing cloudは、ERPやCRM、DWH、コールセンターやWebサイトにおける企業内データおよびその他の外部データに対し、データの統合・収集・蓄積・抽出とともにデータ分析(データマイニング)を行い、企業の事業活動支援に直結するアクションを導くためのソリューション。データマイニング、レコメンド機能をコアエンジンとして搭載し、Web/CRM/リード管理/レコメンドなどの業務アプリケーションをクラウドで提供する。新たに提供される製品では、統合されたデータから顧客を分類してアクションを行うといった、クラスタ分析とアクションに至る機能強化を行ったことにより、B to CおよびB to Bのそれぞれの担当者が、管理画面を通じてクラスタ単位のデータ分析を行いながら、クラスタ化されたデータをもとにしたレコメンド・ターゲティングを同一管理画面でできるようになった。統計の専門家でないマーケティング担当者やWeb担当者、企画者でも、分析からアクションへと繋げることができるという。
2015年04月13日
パナソニックは4月1日、4Kパススルー対応のシアターバー「SC-HTB885」と「SC-HTB690」を発表した。発売は5月22日。価格はオープンで、推定市場価格はSC-HTB885が80,000円前後、SC-HTB690が50,000円前後(いずれも税別)。SC-HTB885とSC-HTB690は、バースタイルの本体にワイヤレスタイプのサブウーファーを組み合わせたシアターシステムだ。サブウーファーに加えて、SC-HTB885は2Wayのフロントスピーカーにフルレンジのセンタースピーカーとサラウンドスピーカーを使用した5.1chシステムで、SC-HTB690はフルレンジのフロントスピーカーとセンタースピーカーを使用した3.1chシステム。HDMI端子はSC-HTB885が2入力/1出力、SC-HTB690は1入力/1出力を装備。最新の著作権保護技術HDCP 2.2規格に準拠し、4K信号のパススルーに対応したHDMI端子を持つ。ハイビジョン映像やSD映像をアップスケールした4K映像だけでなく、4Kチューナーなどで受信した4K放送の信号も、シアターバー経由でテレビに伝送できる。HDMI以外の入力端子は、光デジタル音声×1(テレビ音声用)を装備。Bluetoothにも対応しており、スマートフォンなどに保存された音楽をワイヤレスで再生することも可能だ。BluetoothのバージョンはSC-HTB885が3.0で、SC-HTB690は2.1+EDR。対応プロファイルはいずれもA2DPのみ。音声コーデックはSC-HTB885がaptXとAAC、SBCで、SC-HTB690がSBCのみとなっている。アンプはジッターを最小に抑制する「LincsD-Amp II」を搭載。総合実用最大出力はSC-HTB885が500Wで、SC-HTB690が350W。本体サイズはSC-HTB885がW1,125×D121×H51mmで、SC-HTB690がW950×D120mm×H55mm。SC-HTB885の横幅は50V型の液晶テレビ「ビエラ」と、SC-HTB690の横幅は42V型とほぼ同じだ。サブウーファーのサイズはSC-HTB885がW180×D306×H408mmで、SC-HTB690はW180×D303×H378mm。
2015年04月01日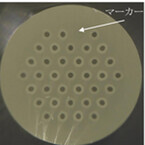
情報通信研究機構(NICT)は、住友電気工業、横浜国立大学、オプトクエストと共同で、1本の光ファイバのコア数36で、かつ、すべてのコアがマルチモード伝搬の新型光ファイバを開発し、光信号の送受信実験に成功したと発表した。光ファイバ1本当たりの伝送容量を拡大する次世代技術として、マルチコアファイバやマルチモードファイバ伝送が世界的に研究されている。しかし、マルチモード伝搬にするためにコア径を広くするとコアから漏れた光信号の干渉が大きくなる問題や、既存の光ファイバとの接続方式が複雑で、難しい技術が必要であるなどの問題があり、12コアで3モードの光ファイバしか実現していなかった。今回、NICTは、36コアすべてがマルチ伝搬モードの新型光ファイバと、既存の光ファイバとを空間結合装置を介して接続し、「36コア×3モード=108」の空間チャネルで通信波長帯の光信号の送受信実験に成功した。同実験では、横浜国大と住友電工が共同で「36コアマルチモードファイバ」を設計し、住友電工が製造。また、「既存の光ファイバと接続する空間結合装置」は、NICTとオプトクエストが設計し、オプトクエストが製造した。これまで、NICT発表のマルチコアファイバのコア数は、シングルモードで19が最大で、限界と考えられていた。今回、19コアを大幅に超える36コアを実現し、さらにマルチモード伝搬も成功した。空間結合装置については、これまでマルチコアシングルモードファイバ用に開発していたものに伝搬モードの異なる光信号を合波する機能を追加し、1台でマルチコアとマルチモードに対応することができた。同実験結果の108空間チャネルすべてに最先端光変復調技術やデジタル信号処理技術を利用すると、1本の光ファイバで毎秒10ペタビット級の超大容量伝送の可能性が拓き、今後、より安価で大容量のネットワークサービスの実現が期待できるという。なお、同実験の結果は、米国ロサンゼルスで3月22日~26日開催された光ファイバ通信関係最大の国際会議の一つである光ファイバ通信国際会議(OFC2015)でポストデッドライン論文として採択され、発表された。
2015年03月30日
コアネットインタナショナルは3月3日、ウォッチガード・テクノロジー・ジャパンと協業し、同社のUTM/NGFWを活用した「入口・出口対策ソリューション」の販売を開始した。標的型攻撃では、入口対策やエンドポイント対策を行っていても、情報漏えいの可能性があるため、トラフィックが外部へ流れる"出口"も抑えることが有効とされている。コアでは、UTM/NGFWで提供のあるウォッチガードの「APTBlocker」を活用してサービスを提供。運用・監視を含めたソリューションとして提供していくという。ウォッチガードのUTM/NGFWは、APTBlocker以外にも、高いスループットやセキュリティデータを可視化する「WatchGuard Dimension」を特徴としており、パフォーマンスだけではなく、可視化による問題の特定やセキュリティポリシーの改善を図れる。
2015年03月06日
MediaTekは、ARM Cortex-A72を搭載したAndroidタブレット向け4コアSoC「MT8173」を発表した。同製品は、Cortex-A72が2コアとCortex-A53が2コアを組み合わせたbig.LITTLEアーキテクチャーで設計された64ビットマルチコア製品。最大2.4GHzで駆動するほか、GPUとしてImagination TechnologiesのPowerVR GX6250を採用。350Mtri/sと2.8Gpix/sの性能により、60fpsでWQXGAディスプレイの表示を可能としている。なお、同製品はすでに提供を開始しており、2015年前半にはAndroidタブレットに実際に搭載される予定だという。
2015年03月04日
2015年2月20日に大阪で開催されたPCクラスタコンソーシアムの「PCクラスタワークショップin大阪2015」において、AMDの林淳二氏が「AMDコアのイノベーション "Ambidextrous Computing" ロードマップとその後」と題する講演を行った。2014年10月にLisa Su氏がCEO兼社長になり、AMDは生まれ変わりつつあるという。具体的には、従来のPCビジネスの維持、デスクトップなどのグラフィックス分野に加えて、高密度型サーバ、超低消費電力型クライアント、企業向けグラフィックス、組込み型ビジネス(PS4やXboxなどのゲーム機用プロセサ)、セミカスタムといった成長マーケットを攻める。AMDは従来のx86コアに加えて、ARMコアを使う「Seattle」を開発し、"Ambidextrous Computing"と称する戦略を取ってきた。Ambidextrousとは「右利き」とかでなく「両手が使える」という意味で、日本語では、二刀流と訳している。2014年は、x86コアを使う「Kaveri APU」やサーバ用の「Berlin」とARMコアのサーバ用 CPUであるSeattleを提供し、ユーザが選べるというレベルであったが、2015年にはそれを進めて、x86 CPUとARM CPUをソケット互換にする。エンドユーザがx86からARM、あるいはその逆にCPUチップを差し替えることは、あまり無いと思われるが、マザーボードやサーバを作っている会社にとっては、同じマザーボードで、CPUの差し替えとBIOS ROMの変更程度で、x86とARMの2種類の製品が作れることはメリットであろうと思われる。この2015年の世代では、x86は「Puma+コア」、ARMは低電力の「Cortex-A57コア」を搭載するが、AMDのGCNグラフィックスを搭載し完全なHSAサポートなどコア以外の部分は共通設計にして行く。ARMコアに関しては、2014年はARMのCortex-A57をSeattleに組み込んだが、2015年には、x86コアとARMコア以外の部分の共通化を行う設計メソドロジーを確立し、低電力のA57コアを開発する。そして、2016年にはAMDの独自設計のK12というARMアーキテクチャのコアを開発する。このコアはA57と比較すると、何倍もの性能を持つという。このK12コアの時代には、x86コアのチップもK12コアのARMチップもメニーコア、メニースレッドを並列実行するチップになるとのことであった。現在、HP Moonshotサーバのm700カートリッジに採用されているX2150 APUは4コアのKabiniであるが、将来の高密度サーバにはこのチップを使うのであろう。グラフィックス分野では、2012年に「Tahiti」、2014年に「Hawaii」を開発してきたが、今後も2年置きに新しいグラフィックスチップ(dGPU:discrete GPU)を開発して行く。そして、その次の奇数年にそれをAPUに組み込むというサイクルを続けて行く。その結果、2019年のAPUは数TFlopsの演算性能を持つことになるという。例えばHawaiiの最上位GPUは44GCNコア(CU)を搭載しているが、APUであるKaveriは8GCNコアしか搭載できていない。これは消費電力やチップ面積の制約があるからであるが、サーバ用チップのCPUコア部分とハイエンドGPUのグラフィックス部分を容易に合体できるようにして、ハイエンドのHPC向けのAPUを作る計画である。消費電力は200-300Wと大きくなるが、性能は高く、スパコンなどではメリットがあると見ている。AMDのGPUは、NVIDIAのGPUと比較して、単精度の演算で17%、倍精度の演算では77%性能が高い。そして消費電力は同じ235Wであるので、性能/Wも高い。加えて、1ドルあたりの演算性能も2倍以上高く、メモリ量、メモリバンド幅でもK40を凌駕している。AMDは、今後も、この優位を維持して行く計画であるという。Omni Pathをパッケージレベルで集積するというIntelの講演の直後の発表であり、出席者から、Sea MicroのFreedom Fabricインタコネクトを集積するという話が以前にあったが、どうなっているのかという質問が出た。それに対しては、現在ではPCI Expressで汎用のネットワークインタフェースを付けるという方向で、Freedom Fabricを集積するという話は進んでいないという回答であった。
2015年03月04日
アメリカ生まれのプレミアムアイスクリーム「ベン&ジェリーズ(BEN&JERRY’S)」から、アイスクリームのコア(芯)にアツアツのホットなソースが入った新商品「コアサンデー」が国内全4店舗にて発売中だ。「ベン&ジェリーズ」のアイスクリームは、原料生産者にも公正な価格のフェアトレード原料を使うことや、環境にも牛にもやさしい、持続可能な酪農方法でミルクをつくることなど、創業以来の変わらぬポリシーを貫いて製造されている。今回の新商品「コアサンデー」は、好きなフレーバー2種を選び、コアのソースはチョコレートファッジとキャラメルの2種類からコアのソースを選ぶ。最後にフレッシュな生クリームとお好みのトッピングを乗せて完成。自分好みのフレーバーを組み合わせれば、幾通りもの味わいを発見できる。冷たいアイスクリームとあつあつのソースを混ぜて食べればクセになる美味しさ。この冬、ぜひトライしてみて。(text:Miwa Ogata)
2015年03月03日
マウスコンピューターは24日、CPUに4コアのIntel Celeron N2940を搭載した14型ノートPC「LuvBook B」を発表した。即日販売を開始し、エントリーモデルの価格は税別37,800円から。エントリーモデル「LB-B400EN-BG」の主な仕様は、CPUがIntel Celeron N2940(4コア/1.83GHz)、メモリがPC3-10600 2GB、ストレージが500GB HD、グラフィックスがIntel HD Graphics(CPU内蔵)、光学ドライブがオプション、ディスプレイが14型HD(1,366×768ドット)、OSがWindows 8.1 with Bing。本構成で価格は税別37,800円から。上位モデル「LB-B400BN」では上記構成から、メモリをPC3-10600(4GB、OSをWindows 8.1 Update 64bitに変更し、価格は税別45,800円から。さらにストレージを128GB SSDに変更した「LB-B400SN-SSD」は税別47,800円から。最上位モデル「LB-B400XN-SSD」では、CPUがIntel Celeron N2940(4コア/1.83GHz)、メモリがPC3-10600 8GB、ストレージが256GB SSD、グラフィックスがIntel HD Graphics(CPU内蔵)、光学ドライブがオプション、ディスプレイが14型HD(1,366×768ドット)、OSがWindows 8.1 Update 64bitという構成で価格は税別57,800円から。インタフェースは共通で、USB 3.0×1、USB 2.0×2、HDMI×1、D-sub×1、10Base-T/100BASE-TX対応有線LAN、IEEE802.11 b/g/n対応無線LAN、Bluetooth V4.0 + LE、Webカメラ、マルチカードリーダー、オーディオポートなど。バッテリ駆動時間は約7.2時間(JEITA v2.0)。本体サイズはW340×D241×H12×24.7mm、重量は約1.7kg。
2015年02月24日
ローデ・シュワルツ・ジャパンは2月16日、LANポートを搭載した3パスダイオードパワーセンサ「R&S NRPxxSN」シリーズ3機種を発表した。パワーの正確な測定はますます重要になってきており、あらゆる場所で需要が高まっている。同シリーズは、LANポートを備えることで、インターネットに接続できる環境であれば、外出先からでもタブレットやスマートフォンなどを利用してデータをモニタすることが可能。これにより、衛星システムの地上局や遠隔地など、人が立ち入ることが困難な場所でもパワー測定できる。具体的には、10MHz~33GHzに対応した3パスダイオードパワーセンサであり、ノイズを低減することで-67dBmから-70dBmにダイナミックレンジを拡張し、業界最速の5万回/秒の高速測定と1万回/秒のトリガ速度を実現している。さらに、LANポートを備えているため、ケーブルの長さに縛られず柔軟に測定できる。また、より正確なパワーを測定する際、平均化処理が最も一般的となっているが、同シリーズは、従来のパワーセンサ「R&S NRP-Z」シリーズに比べ、より高速・高確度に測定することができるため、例えば-60dBmのような微小信号でも±0.1dBの確度を時間を80%短縮して測定することが可能。1万回/秒のトリガ測定では100μsの時間分解能であらゆる信号を取りこぼさず測定できる。この他、LANポートが搭載されていない「R&S NRPxxS」シリーズ3機種も同時にリリースされる。なお、両シリーズはすでに販売を開始している。本体価格は「R&S NRPxxS」シリーズが41万9000円(税抜き)から、「R&S NRPxxSN」シリーズが58万円(税抜き)から。
2015年02月19日




















