
コンピュータアーキテクチャの話 (322) GPUが用いるメモリのアクセス時間の短縮方法
GDDR5 DRAMやHBMを使うGPUのメインメモリ(以下ではCPUのメインメモリと区別するためデバイスメモリと呼ぶ)は高いメモリバンド幅を持っているが、アクセスに掛かる時間は、DDR3/4 DRAMと大差ない。GPUのクロックはCPUよりも遅いと言っても、直接、デバイスメモリをアクセスしたのでは、GPUの処理はメモリネックになってしまう。
このため、CPUの場合と同様に、GPUコアの近くに高速の小容量のメモリを置き、多くの処理ではこのメモリを使用することにより、平均的なアクセス時間を短縮して性能を上げるという方法が取られる。
CPUの場合は、ハードウェアが管理して自動的に使用頻度の高いデータを入れてくれるキャッシュが使われるのが一般的であるが、GPUではシェアードメモリなどと呼ばれるローカルなメモリや、ソフトウェアによる管理が必要なキャッシュが用いられることが多い。
マルチコアで複数のキャッシュがあるCPUでは、複数のキャッシュの間で、同じアドレスに異なるデータが書かれてしまうという矛盾が生じないようにするコヒーレンシ制御が必要になる。しかし、そのためには、書き込みに際して、他のすべてのキャッシュに同じアドレスのデータが入っていないことを確認することが必要になる。
例えば「K40 GPU」の場合、15個のSM(Streaming Multiprocessor。CPUのプロセサコアに相当。
なお、NVIDIAはKepler GPUのSMは規模が大きいのでSMXと呼んでいる)があり、それぞれのSMがL1キャッシュを持ち、32×15スレッドが並列にメモリアクセスを行うので、コヒーレンシを維持するためのトラフィックが7200個と膨大になり、CPUのようなハードウェア制御のキャッシュを実現しようとするとオーバヘッドが非常に大きくなってしまう。
このため、NVIDIAのKepler GPU(Tesla Kxxという名前が付けられている)のメモリ階層は図3.8のようになっている。32スレッドを並列に実行するSMXのロードストアユニットからは、Shared Memory、L1キャッシュとRead Only Data Cacheがアクセスできる。物理的にはShared MemoryとL1キャッシュは1つのメモリアレイで、両者の合計で64kBの容量となっており、Shared Memory/L1キャッシュの容量を16KB/48KB、32KB/32KB、48KB/16KBと3通りに分割して使うことができるようになっている。48KBのRead Only Data Cacheはグラフィック処理の場合にはテクスチャを格納したりするメモリで、読み出しオンリーで通常のストア命令ではデータを書き込むことはできない。
L1キャッシュは読み書き可能なキャッシュであるが、K40 GPUの場合は15個あるSMのL1キャッシュ間のコヒーレンシはハードウェア的には維持されておらず、L1キャッシュに書き込まれたデータは、それをL2キャッシュに吐き出す命令を実行しないとL2キャッシュには書き込まれない。そして、L2キャッシュに書かれたデータは自動的には他のSMのL1キャッシュには反映されず、同じアドレスのデータがL1キャッシュに残っていると、古いデータを読んでしまう。
AMDのGCN(Graphics Core Next)アーキテクチャのGPUでは、L1キャッシュに書き込まれたデータはWavefront(NVIDIAのWarp相当)の64スレッド全部でそのストア命令が終了した時点で、自動的にL2キャッシュにも書き込まれる。
しかし、自動的には他のCompute Unit(NVIDIAのSM相当)のL1キャッシュには反映されず、そのアドレスのデータがL1キャッシュに残っていると、古いデータを読んでしまうという点はNVIDIAのFermi/KeplerアーキテクチャのGPUと同じである。
Kepler GPUでは、1次データキャッシュは、レジスタがあふれた時にレジスタの内容を追い出してレジスタを空け、必要になった時に読み込むというコンパイラが挿入するSpill/Fill処理に限定して使うという方法に変更された。Spill/Fill処理であれば、溢れたレジスタのデータを他のSMXが使うことは有り得ないので、SM間のL1キャッシュのコヒーレンシを維持する必要がない。
また、Read Only Data Cacheはリードオンリーであるので、SM間で同じアドレスのデータが異なることは有り得ないので、これもキャッシュコヒーレンシを維持するメカニズムは必要ない。
L2キャッシュとRead Only Data Cacheは、同じアドレス空間の同じアドレスを指定すれば、異なるSMで動いているスレッドでも、同じデータを読むことができる。L1キャッシュはコヒーレンシが維持されていれば、他のSMで動いているスレッドも同じアドレスで同じデータをアクセスすることができるのであるが、コヒーレンシが維持されていない状態では、これは保証されていない。一方、Shared MemoryはSMにローカルなメモリであり、デバイスメモリのアドレス空間とは独立なアドレスでアクセスされる。そして、同じSMで動いているスレッド間では同じアドレスは同じ32bitデータをアクセスするが、異なるSMの間では、アドレスが同じであったとしても、まったく異なるデータをアクセスすることになる。
Shared MemoryはSMローカルなメモリであり、他のSMのローカルメモリとのコヒーレンシは、本質的に不要である。
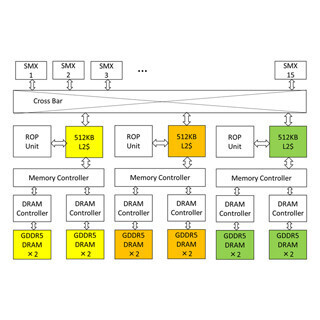
そして、L1キャッシュとRead Only Data Cacheをミスすると、L2キャッシュがアクセスされる。CPUのL2キャッシュ(あるいは、IntelのいうLast Level Cache)はどのメモリアドレスのデータでもキャッシュの格納位置に制限はないが、GPUのL2キャッシュはCPUのL2キャッシュと異なり、図3.9に示すように、黄色のGDDR5メモリの内容は黄色のL2キャッシュスライスにしか入らないというように、対応が決まっている。
それぞれの512KBのL2キャッシュスライスは同色のGDDR5メモリのアドレス範囲のデータしかキャッシュしないので、原理的に、同じアドレスのデータが2つのL2キャッシュスライスに存在することは起こらない。従って、この構造のL2キャッシュでは自動的にコヒーレンシは保たれる。
通常のCPUのように、DRAMチップとキャッシュの格納位置に制約のないキャッシュの方が、格納の自由度が高く、ヒット率を高くすることができると思うのであるが、実測データを見たことが無く、どの程度の差があるのかは分からない。

提供:
関連リンク
-

new
板東英二さん死去 『マジカル頭脳パワー!!』共演の間寛平が追悼コメント発表…「最後に会いたかった、残念です」【全文】
-

new
WEB小説投稿サイト「ネオページ」、「第1回 逆転ヒロイン大賞」大賞受賞者・オデットオディール氏のインタビュー記事を本日7月28日より公開!
-

《瑶子さまもご信頼》元政治難民の少年が皇族、首相夫妻、Snow Manの衣装を担当するデザイナーに…仏・オルセー美術館で作品発表も
-

山本圭壱&西野未姫、長男のお宮参りへ「お顔が変わりましたね!」「シンシンにそっくり」 長女交えたほほ笑ましい家族4ショットを披露
-

シン・ミナ、芯の強さを感じさせる真っ赤なドレス姿で圧巻 韓国ドラマ『再婚承認を要求します』プレティザービジュアル解禁