
岸谷五朗と寺脇康文による演劇ユニット「地球ゴージャス」。その最新公演『The Love Bugs』の公開ゲネプロが2016年1月8日に行われた。本番の衣装を身につけ登場したキャスト陣。まず演出も務める岸谷が「本当にあっという間です。2か月ちょっと稽古しましたが、稽古はいくらやっても足りないもの。でも総勢34名、素晴らしい俳優が全力で作り上げてくれました。お客様がいらっしゃってくれるのが楽しみ」と挨拶。地球ゴージャスプロデュース公演Vol.14『The Love Bugs』チケット情報続いて、キャスト陣が意気込みを語る。「お客様に絶対に損はさせない!と自信を持ってお伝えします」(マルシア)、「今までにないほど不安を感じている。見応えのある物語なんですけど、ソロや殺陣など緊張する場面がたくさんあるので。頑張ります」(城田優)「大切にみんなで作り上げてきた物語。観終わった後に心に残るものは本当に暖かくて大きいものだと思います」(蘭寿とむ)。舞台中で華麗なダンスを披露する平間壮一は「キャスト全員で作り出す世界観の中で、必死に生きられるように頑張ります」と語った。今回初舞台、初ミュージカルとなる大原櫻子は「初舞台ですが、ここまでの稽古が楽しくて楽しくて。今は逆にお客さんが入ってからの変化を楽しみたい」とコメント。そんな大原に岸谷「毎日毎日すごい吸収力で、音をたてて成長していく。千秋楽後にどれだけすごい女優になってるか楽しみ」と太鼓判を押す。地球ゴージャスのもう1本の「柱」である寺脇も「最新作が代表作であるという風にいつも思って作ってますが、これは本当に誇れる代表作。稽古場での完成度はどんなに頑張っても60%、お客様が劇場いっぱいになって、エネルギーの交換をした時に初めて100%になっていく。ぜひ劇場に来て下さい」と最新作の仕上がりに感無量のようだ。開幕まで多くが謎に包まれていた今回の作品だが、タイトルの通り「昆虫」たちが繰り広げる一夜の宴、そして「愛」の物語だ。歌やダンス、アクロバットなど、エンターテイメントをこれでもかと盛り込むのは地球ゴージャス公演ならでは。また、今回は山本寛斎事務所が総力を挙げて手掛けた個性的な衣装も見どころのひとつだ。その華やかさに酔いしれ、ストーリーに秘められたメッセージを噛み締めよう。2月24日(水)まで東京・赤坂ACTシアターにて上演。その後名古屋、福岡、大阪公演を予定している。取材・文:川口有紀
2016年01月12日
地球で懸命に生きる野生動物たちの姿を、初めて彼らの目線でとらえた新しいネイチャードキュメンタリー『シーズンズ 2万年の地球旅行』。このほど、日本語版ナレーションを笑福亭鶴瓶と木村文乃という“ほっこり”する2人が手がけていることでも話題の本作から、森の中でドングリ争奪戦を繰り広げるキタリスとカササギの愛らしくも白熱した映像が、シネマカフェに到着した。地球の主人公、野生生物の目線でとらえた2万年の物語を、最新の撮影機材と数多くの専門家とともに描いたネイチャードキュメンタリーとなる本作。鶴瓶さんは落語家ならではの語り口で、いままでにないネイチャードキュメンタリーの世界観を表現、また、木村さんは壮大な時間軸の中で移ろいゆく自然の様子と懸命に生きる動物たちを、俯瞰の立場でナビゲートしていく。今回到着したのは、木の実がたわわに実る秋、森の中でキタリスとカササギがキュートな白熱のドングリ争奪戦を繰り広げる映像。キタリスには、食べきれない数のドングリを地面に埋める習性がある。貯蔵したドングリは、リスにとっては冬の保存食として欠かせないのだが、せっかく埋めたドングリのことをときどき忘れてしまうことも!?とはいえ、これは森にとっては重要な行動で、土の下に埋められたドングリがやがて芽を出し、成長して木になり、森となっていくのだという。また、せっかく埋めたドングリを、まんまと盗まれてしまうこともあるようで、それを狙うのは、カラスの仲間であるカササギ。映像でも、1匹のカササギがキタリスたちのドングリを狙っている様子が映し出されている。狙われているとはつゆ知らず、美味しそうにドングリを頬張るキタリス。果たして、ドングリ争奪戦の結末はいかに!?さらに本作には、クマやウマといった動物のオスがメスの争奪戦を繰り広げる場面も登場!動物たちの白熱した生きるためのバトルの行方は、スクリーンで確かめてみて。『シーズンズ2万年の地球旅行』は1月15日(金)よりTOHOシネマズ日劇ほか全国にて公開。(text:cinemacafe.net)
2016年01月12日
今回はマルチスレッドについて扱います。マルチスレッドは、簡単に言ってしまえば複数の処理を「並列」に進めることができるものです。マルチスレッドの反対がシングルスレッドであり、これは複数の処理を順番に進めていくものです。逆に言えば、ある処理が終わるまでは次の処理を実施することはできません。マルチスレッドおよびシングルスレッドの“スレッド”は「プログラムの実行単位」のことで、名前からわかるようにマルチスレッドはプログラムをマルチな実行単位で実行します。今回の流れとしては、まず最初にプログラムの実行時間の測定手法について学びます。これを理解していないとマルチスレッドを使った高速化がどれほど効果的なものか理解しづらいためです。次にさまざまな処理にかかる遅延がどれほどのものかについて学びます。それらの基礎ができたうえで、シングルスレッドの問題点について、その次にマルチスレッドがどのようにその問題を克服するかについて扱います。そして実際にPythonでどのようについてマルチスレッドを使うかを学び、最後にマルチスレッド特有の問題点について学びます。なお、今回も内容が多くなっため前後編に分けます。今回は簡単なマルチスレッドの使い方、次回は発展内容となります。○プログラム速度の測定方法マルチスレッドを使うメリットのひとつに遅延(実行速度が遅い)の問題を回避できる可能性があるというものがあります。ただ単にマルチスレッドの使い方の説明をするよりも、実際にプログラムの速度を計測しながらどのようにして処理速度が向上するかを体験してもらいたいと考えています。そのため、まず最初にプログラムの実行速度の計測方法について扱います。なお、速度の測定をきちんと実施したい場合は、今回扱うような簡易的な方法ではなく、専用のきちんとしたパッケージを使ったほうがいいかもしれません。今回利用する測定方法は簡単に言うと、現在の時刻を取得処理先の時刻と現在の時刻の差分を取得という方法で行います。このようにすることで、上記の「処理」にかかった時間が測定できます。現在の時刻の取得方法はtimeモジュールのtime()関数を使います。簡単にですが、サンプルを試してみましょう。import timetime_before = time.time()time.sleep(5)time_after = time.time()time_elapsed = time_after - time_beforeprint(time_elapsed)最初なので少し冗長に書いていますが、それほど難しくないですね。上記だとtime.sleep()関数で5秒間わざとスリープさせて、その実行速度を求めています。これを実行すると私の環境では以下のようになりました。# python test.py5.00498509407スリープした5秒だけでなく、「時間の取得処理やその他」にかかる時間も含まれますので、ジャスト5秒にはなっていません。まぁ、だいたい5秒なのでOKでしょう。今後はこの方法で時間の測定をしていきます。○さまざまな処理の速度と遅延先程はsleep関数の実行速度を計測しました。ほかの処理はこれほど簡単に実行時間を推測することはできませんが、プログラムの処理速度はその処理内容に応じてかかる時間にある程度の傾向があります。マルチスレッドを使う場合は、この推測される処理時間に意識を配る必要があるので、簡単にではありますが、さまざまな処理の実行速度を計測してみたいと思います。まず、今回の遅延測定のコードのベースとなる「何も遅い原因のないプログラム」の測定をしてみます。import timesum_value = 0current_time = time.time()for i in range(0, 10000):Noneprint(time.time() - current_time)ループ分の中がNone(処理をしない)となっているので、ただ単にループを回しているだけです。この実効速度は以下のようになりました。# python test.py0.0005049705505370.5ミリ秒ですね。次にループ処理の中で合計値sum_valueを求める処理を書いてみます。要するに足し算にかかる処理時間が追加されます。import timesum_value = 0current_time = time.time()for i in range(0, 10000):sum_value += iprint(time.time() - current_time)Noneだったところが変わっていますが、それ以外はまったく同じです。この実行速度は0.000903129577637となっているので、約1ミリ秒と処理にかかる時間はオリジナルの2倍程度になっています。次にprint文で合計値を出力するようにしてみます。これは「画面への出力処理」にかかる時間が追加されるということです。import timesum_value = 0current_time = time.time()for i in range(0, 10000):sum_value += iprint(sum_value)print(time.time() - current_time)この実行速度は私の環境では0.027067899704となりました。オリジナルのループするだけのコードに比べると処理時間が約54倍となっています。足し算に比べて処理時間が一気に跳ね上がりましたね。ここまでをまとめると、以下のようなことがわかります。足し算は速度が早いprint文による画面出力は遅いこの処理速度の違いはなんだと思いますか? 答えは簡単で、足し算は「CPUとメモリ」の処理であり、print文は「画面出力というIO処理」というところです。Pythonで処理を書く場合、その実効速度は以下の図のような傾向があります。Pythonで書いても直接Cで実行される場合とインタプリタで解釈されて実行される場合があります。前者のほうが当然速いのですが、どういう場合にCが走るかを知っていないと使いこなせないので、初心者はそこまで両者を区別する必要がないです。ただ、図の青色の処理は主にCPUとメモリだけで実行されるのに対して、オレンジの処理は「より低速であるほかの装置」が関わってくるので実行時間がガクンと落ちるということは知っておく必要があります。print文も画面出力が関わってくるので、実行速度が落ちたのですね。さて、次はディスクアクセスをさせてみます。なお、私の環境はSSDなのですが、HDDだと実行速度がこれよりも大幅に落ちる可能性があります。また、ディスクアクセスは最適化が走りやすい処理内容なので、同じコードでもPythonのバージョンやOSによっても処理速度が大きく変わる可能性があります。プログラムは以下のようになります。まず、ファイルをオープンして、そこにループで連続で追記を行い、最後にクローズをするというコードです。import timesum_value = 0current_time = time.time()f = open(’/Users/yuichi/Desktop/a.txt’, ’a’)for i in range(0, 10000):sum_value += if.write(str(sum_value) + ’\n’)f.close()print(time.time() - current_time)この実行速度は先程のprint文よりも早く、0.00518202781677となりました。ループ内での足し算だけのコードに比べ、6倍ほどの実行時間がかかっているものの、print文よりかはだいぶ速いですね。ただ、先に言ったようにSSDではなくHDDだともっと速度が遅くなる可能性が高いです。これはSSDがランダムアクセスに強いのに対して、HDDは回転するディスクと移動するヘッダという構成なので、飛び飛びのデータを読んだり書いたりする動作が遅いためです(おそらく書き込み処理は最適化でバッファリングされると思うので、今回のような使い方ならHDDでもそれほど遅くない気がします)。なお、ファイルのオープン・クローズをfor文の中で行うと実行時間は0.567183971405となりました。ここから「ファイルに書き込む処理」よりも「ファイルのオープン・クローズ処理」のほうがずいぶん時間がかかることがわかりますね。こういうように速度を検証すると書き込むたびにオープン・クローズするよりも、オープンしたファイルに連続で書き込むほうがよいということがわかってくると思います。検証は大事です。次に機器外へのネットワークを経由したアクセスを試してみます。具体的には外にデータを送ったり、取ってきたりといった処理です。Pythonだと普通はTCP/IPネットワークの利用だけがこれに該当すると思います。サンプルコードはさまざまな有名なWebサイトのトップページのHTMLを取得するというものです。import time, urllib2current_time = time.time()urls = [’’, ’’, ’’]for url in urls:response = urllib2.urlopen(url)html = response.read()print(time.time() - current_time)urllib2というライブラリを使って、指定されたページを開いてHTMLを取得しています。この実行速度は私の環境(携帯の回線)では0.623227119446となりました。たった3ループするだけで0.6 秒かかっていますね。1万ループさせるまでもなく低速なことがわかります。ある程度察しはつくかと思いますが、なぜこれほど処理に時間がかかるかは次に述べます。○マルチスレッドの基本今までの話を通して、処理によってかかる時間に違いがあることがわかりました。問題なのはネットワークアクセスのような「時間がかかる処理」を順に実施すると、合計の処理時間が長くなってしまうことでした。先ほどのHTML取得の例は以下の図のようなイメージです。ただ、よく考えてみてください。あるサイトからHTMLを取得する際に、そのリクエストをするホスト(Pythonを動かしているPC)は何をするかというと以下のとおりです。リクエストをするレスポンスを待つレスポンスを受ける2番目の処理は上記図の「HTTP Request (1) + サーバー処理(2) + HTTP Response (3) 」となります。この間はただ待っているだけですので、要するにPythonのプログラムを動かしているホストは「時間だけ使っているが何もしていない」状態です。3つのサイトからHTMLを取得するということは、その何もしない待ち状態の処理を3回繰り返します。この時間の無駄遣いは、ある程度は解消できます。どうせ待つのであれば、以下の図のように連続で並列にリクエストをしてしまえばよいのです。そうすると処理時間は「各処理(HTML取得)の合計値」ではなく、「最長となった処理の時間」となります。これを実現するのがマルチスレッドと呼ばれる機能です。マルチスレッドを使うことで、本来はプログラムが待ちになってしまう箇所で別の処理を実行することが可能なため、CPU の計算資源をより有効に活用することができます。これはなにも計算資源の節約のためではなく、アプリケーションやサービスのユーザビリティの向上やレスポンス時間の短縮にも利用することができます。少し説明をします。たとえばあるGUIのプログラムがあるとしましょう。もしこれがマルチスレッドを使わずに動いていたとすれば、ある重たい処理をGUIで実行すると、その間はほかの処理が停止してしまいます。GUIの操作を受け付けられなくなり、見た目のアップデートもされなくなるのでアプリケーションがフリーズしてしまったように見えるはずです。一方、マルチスレッドでその重たい処理を実行すれば、重たい処理を実行しているもののアプリケーションは実行可能(GUIの見た目もアップデート可能)です。ほかの例としては複数のホストから依頼を受けるサーバプログラムがあげられます。そのサーバープログラムがシングルスレッドだと、あるホストから処理のリクエストを受けてからそのレスポンスを返すまでは、別のホストからのリクエストが来たとしても処理できず待たせることになります。一方、マルチスレッドにすればあるリクエストの実行中であっても、別のリクエストを受けることが可能になります。そのため複数のリクエストを同時にこなすことが可能になります。○マルチスレッドの限界マルチスレッドが万能かというと必ずしもそうではありません。なぜならマルチスレッドは計算資源を「分けあって使う」だけであり、計算資源そのものを多く使えるわけではないためです。たとえば、使用しているPCでCPUを100%状態でフル活用すればタスクAを10秒、タスクBも10秒で終わらせられるとします。そのとき、マルチスレッドを使うとタスクAとタスクBを同時に実行できるものの、それぞれにかかる時間が20秒に増えてしまいます。たとえばプログラムの処理がCPUを100%使い切る場合、複数の処理を並列に実行することはできても、その合計処理時間はシングルスレッドと理論上は変わりません。これは処理Aと処理Bを同時に実行する場合、AとBは計算資源を分けあってしまうのでそれぞの処理が終わるのに必要な時間が伸びてしまうからです。このイメージ図を以下に記載します。そのため、何に起因して処理に遅延が発生しているのか把握したうえでマルチスレッドを使うことが望ましいです。昨今はCPUはマルチコアになっているので、CPU依存のプログラムであってもシングルスレッドだとコアをひとつしか使えなかったが、マルチスレッドならコアを2つ以上使えて高速化するというシナリオはあるでしょうが。プログラムが複雑化するという以外にマルチスレッドを使うデメリットはそれほど多くないので、時間がかかる処理が存在するとわかっていれば、最初からマルチスレッドを念頭に入れて設計してみてもいいかもしれませんね。○Pythonでのマルチスレッドの利用Pythonでマルチスレッドを使う方法は主に2つあるのですが、まず「ある関数の処理をマルチスレッドとして呼び出す」という方法について扱います。さっそくなのですが、サンプルコードを書いてみます。インポートしているthredingモジュールのThreadクラスに着目してください。import threading, timedef prints(name, sleep_time):for i in range(10):print(name + ’: ’ + str(i))time.sleep(sleep_time)thread1 = threading.Thread(target=prints, args=(’A’, 1,)) # Initializethread2 = threading.Thread(target=prints, args=(’B’, 1,))thread1.start() # Startthread2.start()これを実行すると以下のようになります。python test.pyA: 0B: 0A: 1B: 1A: 2B: 2まず、上記のプログラムではdef printsにて指定された秒ごとにループを回してメッセージを出力する「関数」が定義されています。この関数がマルチスレッド化する処理の対象です。Initializeとコメントされている箇所で、そのprintsをthredingモジュールのThreadクラスのコンストラクタに関数printsの引数とともに与えています。なお、与える引数についてはタプルとしてまとめています(タプルの最後に , をいれているのはタプルの要素がひとつのときでも必ずタプル型になるようにするため)。ここはタプルではなく、リストでもかまいません。prints関数をprints(’A’, 1)としてマルチスレッドとして呼び出すようなイメージです。そして最後に作成されたインスタンスのstartメソッドでマルチスレッドとして並列に実行させています。これを呼び出すと新しいスレッドを開始して、すぐに次の行の実行に移ります。prints関数を見てもらうとわかるように、通常どおりシングルスレッドで呼び出していれば、まず引数A,1で呼び出し、そのprints関数の呼び出しが「終了」したら再度B,1で呼び出すという動きをします。出力としては、A: 0A: 1…A: 8A: 9B: 0B: 1…B: 8B: 9となりますね。ただ、マルチスレッドの出力を見てもらうとわかるように、1回目の関数呼び出しによる出力と2回目の関数呼び出しによる出力が混じって出力されていることがわかります。これはつまり、1回目の関数呼び出しを実行している最中に2つめの関数呼び出しも実行されているということです。両者の違いを絵にまとめます。○スレッドが終了するまで待機する方法複数のスレッドが連携して動作する場合は「スレッドAはスレッドBの結果を利用する」などといった使い方をすることがあります。この場合、スレッドAはスレッドBが終わるまで「待つ」必要があります。あるスレッドが終わるまで待機するには、そのスレッドのインスタンスのjoinメソッドを呼び出す必要があります。別の言い方をすると、joinメソッドの「呼び出し元」は「joinメソッドのインスタンス」のstartメソッドで呼び出されたスレッド処理が終了するまではjoinメソッドを呼び出した箇所で待ち状態になります。たとえば先程のコードを少し変えて、thread1.start()thread1.join() # WAIT HEREthread2.start()とすると、thread1が終了するまでthread1.join()の箇所で待機するため、thread2.start()はすぐには実行されません。結果としてprint出力はシングルスレッドのときと同じものになります。この「スレッドの待ち」を使って、以下のように「基本はシングルスレッドだが、特定のタイミングのみで複数の処理を走らせる」という方法はよく使われる手法です。複数の時間がかかる処理を実行する必要がある場合はそれらを順に実施するよりも、このように並列に実行したほうが実行時間が短くてすみます。この手法を使って、先ほどの複数のWebページからトップページのHTMLを取得するプログラムを高速化してみます。コメントでStart Threadsとなっている箇所で図の処理2を開始し、Wait Threadsとコメントしている箇所で処理2を待機しています。Threadのインスタンスを作ったタイミングでリストに格納し、待つ場所でそれらすべてに対してjoinを呼び出すという方法ですべてのスレッドが終了するまで待機させています。import threading, time, urllib2def get_html(url):current_time = time.time()response = urllib2.urlopen(url)html = response.read()print(url + ’: ’ + str(time.time() - current_time))urls = [’’, ’’, ’’]threads = []# Start Threadscurrent_time = time.time()for url in urls:thread = threading.Thread(target=get_html, args=(url,))thread.start()threads.append(thread)# Wait Threadsfor thread in threads:thread.join()print(’Time: ’ + str(time.time() - current_time))これを実行すると以下のようになりました。 0.322998046875 0.402767896652 0.848864078522Time: 0.849572896957今までは約1.6秒かかっていたものが、約半分の時間になりましたね。マルチスレッドを使うことでプログラムの実行速度が大幅に向上しました。すべてのスレッドの処理が終わるまでjoinのループで待ちますので、プログラムの実行時間は一番取得に時間がかかったサイトに依存しています。表示結果を見る限り、今回はgoogleのページの取得に一番時間がかかり、プログラムの実行時間はgoogleのページの取得時間とほぼ同じになっていますね。今回は3つのサイトだけでしたが、これが10、20などになってくるとより効果的になります。ただ、ネットワークの帯域幅などがボトルネックになりだすとスレッドを使っても解決できなくなる可能性があります。そのときはthreadpoolなどのテクニックを使って特定個数のスレッドを使いまわしたりするのですが、入門レベルを超えるので割愛します。次回もマルチスレッド処理について解説していきます。クラスの継承によるマルチスレッドの実現や、マルチスレッド特有の難しさ、またマルチスレッド以外の並列処理について扱います。
2016年01月05日
宇宙航空研究開発機構(JAXA)は12月24日、小惑星探査機「はやぶさ2」が同月3日に実施した地球スイングバイについて、結果の詳細を報告した。すでに、地球スイングバイが成功だったことは14日のプレスリリースで公表されていたが、今回、誤差300mという高い精度で軌道誘導できていたことなどが明らかになった。地球スイングバイは、地球の重力と公転を利用して、探査機を加速/減速させる技術である。燃料を使わずに加速/減速できるというメリットがあるが、目的の軌道に乗せるためには、極めて正確に探査機を誘導して、正しいルートを飛ばす必要がある。進入時の誤差が大きいと、軌道の誤差が大きくなり、修正のための燃料消費量が増えてしまう。はやぶさ2は、化学エンジン(RCS)を使った軌道修正を2回実施した。1回目(TCM1)は11月3日で、噴射時間は合計3.95秒。これで軌道の誤差を400kmから11kmへと縮小させた。さらに、11月26日の2回目(TCM2)で0.80秒の噴射を行い、この結果、誤差は11kmから3kmまで小さくなった。TCM1に先立ち、9月1日~2日には、イオンエンジンを使った軌道修正(IES-TCM)も実施していた。ここでイオンエンジンを使ったのは、RCSの燃料消費を少しでも抑えるためだ。RCSは小惑星に到着後、タッチダウンなどで使用する。未踏の小惑星では、何が起こるか分からない。燃料さえあれば自由度は増すので、少しでも節約しておきたいのだ。JAXAは当初、12月1日に3回目(TCM3)を実施する予定であったが、11月30日に軌道を推定したところ、TCM2までで十分な精度を達成できたことが分かり、TCM3はキャンセル。津田雄一・はやぶさ2プロジェクトマネージャによれば、「30km以内なら成功と見ていた」とのことで、3kmの誤差であれば、イオンエンジンの燃料消費もほとんど増えない。TCM3をキャンセルしたことで、JAXAは誘導目標点を変更、当初の的の中心から、3km離れたTCM2後の予測点を新ターゲットに設定した。スイングバイ後に軌道を正確に解析したところ、実際にはやぶさ2が通過したのは、そこから300mほど離れた地点だった。これにより、JAXAは「最終的な軌道誘導精度は300mだった」と結論付けた。「当初の目標地点から3km離れているんだから、軌道誘導の精度は3kmでは?」と思うかもしれないが、もし12月1日にTCM3を実施していたら、ほぼ同程度の精度で、的の中心近くを通過することが可能だったと見られている。上記の「精度は300m」には、そういう意味があるのだ。本来は30kmの精度でも良かったので、地球スイングバイだけを考えれば、そこまで高い精度を狙う必要は無かった。しかし地球帰還時、大切な小惑星のサンプルが入ったカプセルを分離するときには、やはり高い精度の軌道誘導が必要になる。今回は、そのリハーサルとしても考えられており、十分な能力があることを実証できた形だ。また、地球スイングバイの前後には、はやぶさ2に搭載された観測機器による試験撮影なども行われた。宇宙空間を航行中は、何を撮影しても点にしかならないのだが、地球や月を近くから撮影すれば、機器の健全性を確認できる。地球スイングバイは、小惑星到着前にそれができる、唯一の貴重な機会でもある。はやぶさ2は基本的に、太陽電池パドルを太陽に向けた「巡航姿勢」で飛行している。一方、観測機器の多くは底面側に配置されているため、地球を観測するためには底面側を地球に向けた「観測姿勢」にする必要がある。スイングバイ前は、両者の差が大きく、かなり姿勢を振らないといけなかったが、日々姿勢を切り替えることで対応した。この姿勢制御には、リアクションホイールとRCSを併用した。RCSでは偶力噴射を行うことで、軌道は変えずに姿勢だけを変えるようにするが、スラスタにバラツキがあるため、どうしても横方向の微小な推力が発生してしまう。これが軌道の誤差の原因になるため、軌道への影響を評価しながら慎重に運用を行ったという。スイングバイ後は、巡航姿勢との差が小さくなるため、観測姿勢を維持しながら、観測に注力。そして12月22日に巡航姿勢に戻し、一連のスイングバイ運用を完了した。この結果、4つ全ての観測機器に対し、問題無いことが確認できた。今後は、いよいよ小惑星リュウグウへ向け、イオンエンジンの本格的な運転が開始されることになる。今までの稼働時間は累計600時間程度だが、これからは約7,000時間(約292日分)も動かさないと、リュウグウに到着することができない。津田プロマネは「緊張を強いられる運用になる」と、今から気を引き締めた。初号機では、イオンエンジンやリアクションホイールに不具合が出てしまったが、今のところ、はやぶさ2の機器は全て順調だ。イオンエンジンの運転は2016年3月~4月から開始する予定で、津田プロマネは「我々には初号機の経験があるものの、はやぶさ2もまだ挑戦。日々起きることをハラハラドキドキしながら見守って欲しい」と呼びかけた。
2015年12月25日
IPA(独立行政法人情報処理推進機構)情報処理技術者試験センターは12月22日、「情報処理の促進に関する法律施行令の一部を改正する政令(平成27年12月22日閣議決定)」に基づき、経済産業省が所管する国家試験「情報処理技術者試験」の受験手数料が改定されたことを発表した。情報処理技術者試験は、情報処理技術者としての知識・技能が一定以上の水準であることを認定している国家試験。情報システムを構築・運用する技術者から、情報システムの利用者まで、ITに関わるすべての人を対象としている。昭和44年から平成27年度までの累計の応募者数は約1840万人、合格者数は約232万人。情報処理技術者試験の受験手数料は、平成9年度秋期試験から「5100円(税込)」とされていたが、経済産業省において、受験者数の動向などを踏まえ、今後も安定的に試験制度を運営する観点から受験手数料の額が見直され、「情報処理の促進に関する法律施行令の一部を改正する政令(平成27年12月22日閣議決定)」により、「5700円(税込)」に改定された。改定された受験手数料の適用時期は、iパス(ITパスポート試験)が平成28年(2016年)4月1日から、iパス以外の試験区分が平成28年度春期試験からとなっている。
2015年12月22日
岸谷五朗と寺脇康文による演劇ユニット・地球ゴージャス。そのVol.14『The Love Bugs』が、2016年1月9日(土)より東京・赤坂ACTシアターを皮切りにスタートする。初日に向けますます佳境へと突入する、その稽古場に伺った。地球ゴージャスプロデュース公演Vol.14 『The Love Bugs』 チケット情報正式な顔合わせからは10日ほどだというが、稽古場によそよそしそうな空気感は皆無。まるで、ずっと前から稽古を共にしている劇団のようだ。13時、アップがスタートすると空気がピリッと一変する。さまざまなパターンのストレッチを次々と行い、入念に身体を準備してゆくが……真剣なものの、なぜか笑いが絶えない。おそらくそれは、地球ゴージャスのふたりが誰よりも周りを見て、和ませようとしているからだろう。例えば寺脇は稽古場の片隅にあった送風機で岸谷に風を当ててみたり、身体が固く前屈で倒れ込めない人同士手をふってみたり。また、岸谷は発声練習をしながら時折寺脇に「あれ練習しとこうか」と相談している様子も。長年にわたる鉄壁のコンビネーションは、少し稽古を見るだけの人間にもわかる。しかしながらこの現場、アップだけでも相当ハードだ。走ったり、飛んだり、そして入念な発声練習……その様子はさながら「部活」。地球ゴージャスの醍醐味は、歌、ダンス、アクロバット……公演ごとに様々な要素が加わった「エンターテインメント」であるということ。キャストに求められるものは、その分高くなるというわけだ。入念に時間をかけてアップを行った後、岸谷が厳しい演出家の顔を見せる……と思いきや、キャストのひとりがまだ靴を履いている途中。「菜央が靴はいてまーす」の言葉にまた笑いが起こる。この日はまず、1幕を冒頭から通してゆく。今回の公演は「虫」の世界を描いたもので、場面は虫達の「特別な夜」から始まる。平間壮一と大原櫻子の初々しい出会いのシーン、そこに現れる、城田優演じる“伝説の男”。個性的なキャラクターと早いストーリー展開に引きこまれ、群舞の迫力に圧倒される。ある程度進んだ所で切り、細かく演出をつけていく岸谷。特に今回初舞台となる大原には、何度も丁寧に説明していた様子が印象的だった。さまざまな「謎」を秘めた今回の公演、はたして「虫」たちの運命は……?その答えはぜひ本番で確かめて欲しい。初日まで1か月、ますます熱気を帯びていくであろうこのカンパニーの姿を、ぜひ楽しみにしていよう。公演は1月9日(土)から2月24日(水)まで東京・赤坂ACTシアター、3月1日(火)から3日(木)まで名古屋・愛知県芸術劇場、3月11日(金)から13日(日)まで福岡・福岡サンパレス、3月19日(土)から29日(火)まで大阪・フェスティバルホールにて。取材・文:川口有紀
2015年12月14日
「地球最後の秘境・深海はどんな世界? - しんかい6500パイロットに聞いてみた」はコチラ「地球最後の秘境・深海はどんな世界? - 日本人映像監督初! 山本氏の深海体験」はコチラJAMSTECが約10年後の実現を目指す有人深海調査船「しんかい12000」構想。気になるのが「しんかい12000」とはいったいどのような船なのか、という点。現在の「しんかい6500」から何がどう進化し、何ができるのか。磯崎芳男JAMSTEC海洋工学センター長に詳しく聞いた。○全面ガラス窓で「フルビジョン」を―しんかい12000の特徴を聞かせてください磯崎:コンセプトは「フルデプス」、そして「フルビジョン」です。研究者が超深海に触れるような感覚をできるだけもたせることをキーにしています。現在の「しんかい6500(6K)」にある直径約12cmの小さい窓ではなくて、全面をガラス窓にしたい。―全面ガラスですか?磯崎:そうです。究極の「フルビジョン」です。―それは楽しみですね!磯崎:実は一度、6Kに乗せてもらったことがあるのです。「センター長を一度乗せろ」と(笑)。震災の後に乗りたかったのですが「センター長を乗せる暇はありません」と言われてね(笑)。実現したのは翌年の2012年4月です。そのときに何を感じたか。自分が想像していたより深海が豊かな世界であることです。相模湾初島南東沖1227mまで潜ったのですが、赤や紫のイソギンチャクなどがいてカラフルなのです。そのときに「外に出たい」と思いました。出たらそこはもっと素晴らしい世界だろうなと。だからできるだけ研究者にもそういう感覚を持ってもらえるようにしたいですね。―だから全面をガラスに?磯崎:はい。もうひとつは効率的に潜りたい。6Kは3人乗りで研究者は一人だけです。研究者が二人乗れるようにしようと現在計画していますが、潜航の約8時間の中で往復に5時間かかるので、研究に使えるのが約3時間。研究者一人の目は二つあるから「6時間アイ(Eye)」だと言っています。準備に膨大な時間と予算を投じて、6時間アイではもったいないねと。複数の研究者ができるだけ長い時間潜れるようにしたい。もし、24時間潜れれば、たとえ片道5時間(現在は2.5時間)かかるとしても往復10時間で残りは14時間あります。さらに研究者を複数潜れるようにするつもりです。たとえば二人とすると、14時間×4つの目で「56時間アイ」。二日間に1回の潜航とすると一日あたりは「28時間アイ」で、6Kの約5倍になります。だから6Kの5倍の予算を投じてもいいだろうと。そこまで費用はかかりませんけどね(笑)。―今の6Kは日帰りですが、超深海底に滞在するのですか?磯崎:海底に1~2日程度は滞在できるようにしたいです。そのために耐圧殻を二つ作り、進行方向の耐圧殻はガラス球で、後方はチタン合金の耐圧殻にしてパイロットが横になれるレストルーム兼用にするつもりです。簡易トイレも作ります。でも上のイラストをよく見てください。後方の耐圧殻に出窓がありますね。研究者は眠らずに深海の様子を観察し続けるでしょう。そこで耐圧殻から頭を半分出して、ぐるっとまわりが全部見られるように、半球型の窓を出しているのです。―国際宇宙ステーションの出窓「キューポラ」みたいですね。最大何人まで乗れますか?磯崎:最大6人乗りで、そのうち4人が研究者です。―イラストでは2人が椅子に座っていますね。6Kでは寝転んだ姿勢ですが磯崎:研究者も椅子に座らせる予定です。だから居住性はよいと思いますよ。内部も6Kは昔風に箱ものが多いです。6Kが開発されたのは1980年代、ブラウン管テレビの時代ですからね。でも今は有機ELの時代でタッチパネルが主流です。耐圧殻のガラス球に文字を映せばいいのです。―6Kはあえてアナログにしているのかと思いました磯崎:アナログにもよい面はあります。たとえば航空機のコックピットはどんなに発達してもアナログのメーターがあります。デジタル画面の数字を読むのではなく、針が上をさしているから正常だとか、ぱっと判断できるように。でもアナログ画面をガラス球に映せばいい。○母船からのクレーン方式も変わる!―フルデプス、フルビジョン、効率性アップ……楽しみです磯崎:母船も新しくするつもりです。今は支援母船「よこすか」の後ろからクレーンで下ろして着水させ、スイマーがケーブルを手ではずしています。そのスイマーたちの安全を確保するために天候の条件があるのです。「ちきゅう」(地球深部探査船)という船の内部を見たことはありますか?―はい、つい先日……磯崎:船の真中にムーンプールという開口部があって、そこから掘削しますよね。「しんかい12000」の母船も真中に開口部が欲しい。そこから「しんかい12000」を出し入れしたいのです。―そうすると、スイマーは必要なくなるんですか?磯崎:はい。揺れずに静かに海におろすことができます。現状はたとえばインド洋まで出かけて行ったのに、天候条件が悪くて「今日は潜れません」と潜航しないことがあります。安全第一とわかっていても研究者にしてみれば、せっかく得た機会だし、はるばるインド洋まで行って潜れなかったりすると、愚痴のひとつも言いたくなります。潜れる機会をいかに増やすかも効率化にとって大事です。―ムーンプールを作れば天候にはほとんど左右されなくなりますか?磯崎:船が留まれる限り大丈夫です。―それはよいですね。着水するまでの揺れも解消されそうです。ところでロボットアームは研究者が操作できるようにするのですか?磯崎:それは遠からずできると思います。日本はロボットアームの技術が発達しています。現在ロボットアームはコパイロットが操作していますが、研究者が自分で操作できるようにしたい。研究者が船内からグローブを装着して動かすと、関節の動きが船外のアームに伝わって動かすことができる。さらに圧力センサーや温度センサーなどをつけることで、アームがふれた対象物の温度や触覚などを研究者が指先に感じられるようにする。そんなに難しくないと思っています。海底から噴き出す熱水は200度や300度もあって火傷してしまうので、それは防いであげないといけないですけどね(笑)。―かなり最先端の技術ですね。今最先端の技術を盛り込もうとしているのですか?磯崎:もし「しんかい12000」ができるとすれば10年ぐらい先です。そのとき世の中はもっと先を行っているでしょう。今は夢かもしれませんが、絶対に世の中の技術は追いついてくる。逆に今ある技術でやったら10年先にはもう古びてしまいます。―さまざまな挑戦があり、開発段階自体もとても興味深いですね。磯崎さん自身の6K乗船経験が元になっているだけに、目指す船のカタチが明確ですね磯崎:深海に潜ったときの発光体が非常に印象深かったのです。深海に潜ったあとに水深500mぐらいまで戻ってくると発光生物が漂っています。上昇してくる6Kに発光生物が当たって光ります。上昇する6Kの中から見ると、相対的に海底に沈んでいくように見えます。まるで海の中に無数の星が降るような、光の世界に包まれるのです。―きれいでしょうね……磯崎:微弱な光なので、人間の目でないと見られない。乗った人しか見られない世界があってもいいのかなと思います。聞けば聞くほど魅力的な「しんかい12000」構想。次回は、実現に向けた現状と課題について伺う。
2015年12月04日
宇宙航空研究開発機構(JAXA)の小惑星探査機「はやぶさ2」が12月3日、地球スイングバイを実施した。地球への最接近は同日19時8分ころ。この地球スイングバイにより、計画通りの軌道に入れたかどうかは、今後の詳細な解析を待つ必要があるものの、今のところ機体の状態は健全で、特に問題は確認されていないようだ。はやぶさ2は地球スイングバイの前後20分程度、打ち上げてから初めての日陰に入る。19時18分ころ日陰を出て、それからNASAのキャンベラ局と通信を開始するため、無事に日陰を通過できたかどうかは、それ以降に分かることになる。ただ、この時点で分かるのは機体の状態だけで、軌道の確認には1週間程度かかる見込みだ。はやぶさ2はちょうど1年前の2014年12月3日に打ち上げられた。天体の引力と公転を利用して軌道を変えるスイングバイ航法により、速度を30.3km/sから31.9km/sへと1.6km/s増やし、目的地である小惑星リュウグウに向かう計画。そのため、これまでの1年間は、地球に近い軌道を飛行していた。はやぶさ2関連記事・【レポート】「はやぶさ2」は12月3日19時7分に地球に最接近 - 日本からは観測のチャンスも・【レポート】小惑星探査機「はやぶさ2」の各部をチェック! - 初号機からはこう変わった・小惑星探査機「はやぶさ2」の機体が完成 - JAXAが機体を公開(写真104枚)・【レポート】「はやぶさ2」は浦島太郎? - 目指す小惑星の名前は「リュウグウ」・【レポート】はやぶさ2打ち上げ - 青空の中を飛び立った「はやぶさ2」、打ち上げを写真と動画で振り返る
2015年12月03日
2015年アニメ第1期が放送され、男子高校生たちが地球を守るために魔法少女を彷彿とさせる戦士姿に変身するという斬新な設定で大人気を博したアニメ「美男高校地球防衛部LOVE!」。既に第2期放送が決定している本作の舞台化が決定!赤澤燈、五十嵐麻朝、越智友己、高崎翔太、荒牧慶彦ら舞台で活躍する若手俳優陣が勢揃いした。眉難(びなん)高校に通う箱根有基ら5人は、なんとなく「地球防衛部」に集まりダラダラと過ごしていた。そんな5人の前に、突如として現れた喋る桃色のウォンバット。 「この星を守りたい…どうか力を貸していただけませんか」ひょんなことから愛の王位継承者“バトルラヴァーズ”に任命された5人は、変身アイテム“ラブレスレット”の力で“ラブメイキング”(変身)し、愛で地球を満たす為に戦うことになる。こうしてホントに地球を守ることになった5人は、草津錦史郎率いる征服部が送り込む怪人たちと戦うのであった。2015年1月から3月までテレビ東京ほかで放送され、既に第2期の制作も発表されている女性向けオリジナルアニメ「美男高校地球防衛部LOVE!」がこの度、「美男高校地球防衛部LOVE!活劇!」と題して舞台化されることが決定。アニメでは、山本和臣、梅原裕一郎、西山宏太朗、白井悠介、増田俊樹ら若手声優たちの出世作ともなった本作の舞台化とあって、キャスト陣には、いま、2.5次元舞台(2次元のマンガやアニメを上演する舞台)などで活躍するネクストブレイク必至の俳優たちがずらり!「地球防衛部」のメンバーで、天真爛漫な性格で、防衛部のムードメーカー的存在、箱根有基を演じるのは、残酷歌劇「ライチ☆光クラブ」(カネダ役)ミュージカル「テニスの王子様」シリーズ(芥川慈郎役)ほか数多くの舞台に立つ赤澤燈。何事もマイペースでダラダラの達人、由布院煙を、ミュージカル「薄桜鬼」風間千景篇&藤堂平助篇で原田佐之助役を演じ、ドラマ「私のホストちゃん」にも出演する五十嵐麻朝。真面目で由布院の幼なじみ鬼怒川熱史を、舞台「遙かなる時空の中で5」や『クローズEXPLODE』に出演した越智友己。「世の中金が全て!」が座右の銘の鳴子硫黄を、ミュージカル「テニスの王子様」青学5代目・菊丸英二役を務めた高崎翔太。自称・モテキャラの蔵王を、舞台「K」(夜刀神狗朗役)「曇天に笑う」(青木弥次郎役)で知られる荒牧慶彦がそれぞれ演じる。「地球防衛部」に対する「地球征服部」の3人には、生徒会長・草津錦史郎を、TVドラマ「仮面ライダーウィザード」に出演し、舞台「金色のコルダBlue♪Sky First Stage」を始め多くの舞台作品に出演する前山剛久。生徒会副会長にして草津に執事ように寄り添う有馬燻を「ワンピースライヴアトラクション」ロロノア・ゾロ役の伊万里有。天使のような外見の下呂阿古哉を、サンリオピューロランドのミュージカル「ちっちゃな英雄~ヒーロー」に出演中の柏木湊太が、それぞれ担当。脚本&演出を、「ママと僕たち」、舞台「私のホストちゃん」などを手がける村上大樹が担当し、奇想天外な展開をコミカルに描き出すという。「美男高校地球防衛部LOVE!活劇!」は2016年3月10日(木)~13日(日)、Zeppブルーシアター六本木にて上演。(text:cinemacafe.net)
2015年12月01日
「地球最後の秘境・深海はどんな世界? - しんかい6500パイロットに聞いてみた」はコチラ「地球最後の秘境・深海はどんな世界? - 日本人映像監督初! 山本氏の深海体験」はコチラ宇宙へ頻繁にアクセスできる時代になったが、足元には未開拓の未知の世界が広がっている。水深6000m以下の「超深海」は、光が届かず水圧1000気圧を超える過酷な世界。だが2015年、水深1万mを超える世界最深部のマリアナ海溝に、独自の生命圏が広がっていることをJAMSTECの研究者らが世界で初めて明らかにした。いったいどんな生命が? なぜ? 興味は尽きない。この超深海ゾーンを徹底的に探査しようという日本の有人潜水調査船構想がある。その名は「しんかい12000」。約10年後の実現を目指すこの計画は、生命や惑星地球に関する知見を大きく塗り替えるはずだ。磯崎芳男JAMSTEC海洋工学センター長に、背景から未来までじっくり伺った。○「しんかい12000」の使命とは―改めて今なぜ「しんかい12000」なのか、その背景を教えていただけますか?磯崎:二つの意味があります。ひとつは技術者として。「しんかい6500(以下6K)」建造から25年以上経ち、これまで(2015年11月現在)1440回潜航し、非常に多くの方に乗って頂きました。日本は約90年前の1929年に西村一松さんがサンゴ礁の採取を目的に有人潜水調査船を開発し、技術が継承されてきた歴史があります。それなのに6Kは四半世紀たち、マイナーチェンジはしているものの基本的なところは変わっていない。6Kを作った人たちもリタイヤしています。長年培われてきた日本の技術を次の世代にどう渡せるか。技術屋としての使命があります。技術的挑戦という意味では6Kと同じことをしても意味はない。ひとつ上の技術を狙うという点で、究極はフルデプス、地球でもっとも深いところを狙いたい。―世界で一番深い場所まで「全部潜る船」という意味でフルデプス(FULL DEPTH)ですね?磯崎:はい。世界で一番深いのはマリアナ海溝チャレンジャー海淵の1万911m。我々としてはそこに潜れるものに挑戦するしかないと思っています。もうひとつは研究者のニーズです。超深海は真っ暗で何もないところと思われていましたが、研究者がマリアナ海溝の泥を採取して調べたところ、水深6000mの泥よりも1万mの泥のほうが酸素の消費量が多い。水深1万mに我々の知らない生命圏が広がっているということです。圧力が高く、餌のない場所であるにもかかわらず。また2011年3月には東北地方太平洋沖地震が起きました。巨大地震の震源域を調査して海溝型の巨大地震のメカニズムを解明することも、非常に重要です。―2011年夏に6Kが東北地方太平洋沖地震の震源域である日本海溝の水深約3000m~5000mに潜航して、巨大地震の影響と思われる大きな亀裂を確認しましたね磯崎:はい。震源域である日本海溝の水深は8000mを超えます。伊豆小笠原海溝は9780m、つまり1万m近い。日本周辺のこれら海溝域を探査したい。無人探査機もありますが、研究者がそこに行って五感+アルファを駆使して何が起きたのか、何が起きようとしているのか、調査するツールを持ちたいのです。―五感+アルファのアルファとは?磯崎:第六感です。ダーウィンはビーグル号という船に乗ってガラパゴス島に着き、足を踏み入れたところ、それまで考えていたこととは違うのではないかと進化論のヒントを得て著書「種の起源」をまとめたと言われます。諸説ありますが私はそれを信じています。写真ではなく、現場に人間が行くことで、それまでの知見に加えて五感とインスピレーションによって発見をすることはままある。その場に研究者を運ぶことが大事なのです。―無人機だけでは難しいということですか?磯崎:無人機から母船に送られてくる写真だけを見ていると、重要な発見を見逃すことがあります。たとえば2013年の世界一周研究航海(QUELLE2013)で、6Kに乗っていた生物研究者が深海底を見ていたら「石がちょっと違うんじゃないか」と気づいた。鯨の骨だったのです。世界で二番目に深いところで発見された鯨骨で、大発見になりました。無人機でさーっと通り過ぎただけでは気づかなかったのではないか。―人間の目って、一瞬でとらえるところがすごいですね磯崎:長い間、そのテーマに心血を注いできた研究者が集大成として行っているわけですからね。私は(現状の深海探査は)「お釈迦様の手のひらの上にいるようなもの」と言っています。広く深い深海の中で今は水深6500mまでしかいけない。でも12000mまで深く潜れるようにすれば孫悟空の活躍できるエリアを広げることができるのです。深く潜りたい研究者はたくさんいるんです。○「無人か有人か」ではなく、「無人も有人も」―資源探査についてはどうですか?磯崎:もちろん資源探査のニーズもあります。ただ我々は研究機関ですから、資源を回収して利益をあげようという企業を手伝うというより、なぜそこに資源があるのか、たとえば鉄マンガンクラストや熱水鉱床がなぜここにあるのか、どうやって出来るのかを調べるのが仕事。なぜできたかがわかれば、どこにあるかがわかってくるのです。―資源探査についても研究者が行ったほうがいいですか?磯崎:行く意味は大きいですね。ただし有人調査船ひとつではダメで、トータルで動かすことが大事です。有人潜水調査船は言ってみれば「ガンダム」型。人間が乗って動かす。そのほかに「鉄人28号」型と呼んでいる無人探査機(ROV)があります。ケーブルでつないで遠隔で動かします。動ける範囲に限界はありますが。電力を直接送れるし映像はリアルタイムでとれるメリットがあります。そして今、非常に進歩しているのは自律型無人探査機(AUV)。「鉄腕アトム」型です。ケーブルはなく、自分で考えて海底の様々な調査をして帰ってくる。ただし映像を見るのは母船に戻ってからになります。さらに大型の海洋調査船がある。順番としては、まず調査船で広い範囲にわたって海底の地形を見ます。ただしきれいな画像は得られないので、「ここは面白そうだ」というところにAUVをおろして構造を詳しく調べる。さらにピンポイントに絞り込んだ場所にROVを降ろしでサンプルをとる。最終的に6Kで人が潜る。―なるほど、そういう役割分担があるんですね磯崎:それぞれの長所を生かしながら総合的に使いたい。海は広くて深い。我々が知っている場所は、ほんのピンポイントにすぎません。有人も無人もあらゆるツールを統合的に駆使して、探査する必要があるのです。○実は中国の船より潜れる日本!?―世界の有人深海潜水船で気になるのが、中国の動きです磯崎:中国も水深11000mを目指すという構想(有人潜水船「彩虹鱼」)を2015年春に発表していますね。―中国は2012年6月に有人深海潜水船「蛟竜号(ジャオロン号)」で水深7000mを超える潜航に成功し、6Kの記録を塗り替えたと報じられていますね磯崎:深さ競争をするつもりはないのですが、ひとつだけ理解していただきたいのは、中国の耐圧殻(人が乗り込むコックピット)の安全基準の考え方です。日本と違っているのです。―どう違うのですか?磯崎:中国のほうが低い。アメリカもそうですが耐圧殻の安全率は水深に対して1.25倍の圧力をかけなさいと決めています。たとえば水深4000mなら水深5000mの圧力に耐える強度を持ちなさいと。中国も最大1.25倍と言われています。―日本は?磯崎:水深の1.5倍に300mを足しています。つまり6500mなら6500×1.5+300で水深1万500mの圧力に耐える強度で設計しています。―では水深1万mの世界にすでに行ける!磯崎:もしアメリカや中国の基準(1.25倍)を当てはめれば、今の6Kでそのまま8040mまで潜ることができるのです。―え、では中国の7000mを超えてしまう?磯崎:数字のマジックみたいなものですよ(笑)。―それは悔しい気がします。中国はいったいどこまで潜り、何が目的なのでしょうか?磯崎:試験で7000mを超えて潜り中国の旗を立てたと報じられていますが、日々の活動はわかりません。蛟竜号を動かしているのはCOMRA(China Ocean Mineral Resources R&D Association)と呼ばれる中国の資源の研究開発機関です。資源関連で動いているとすれば、どこで何を見つけようとしているかはオープンにはしないでしょう。―なるほど……謎が多いわけですね磯崎:実は中国の蛟竜号を2013年に見せてもらったことがあるのです。日本のある機関が中国の有人潜水船を調査するというので、COMRAの方に頼んだら快諾してくださり、中国で大歓迎してくれました。「待っていた」と。―何を待っていたのですか?磯崎:質問集をいっぱい持っていました。中国は水深7000mに潜れる船を作ったが、当時我々6Kは23年間安全に事故なく動かしていた。どうやって検査しメンテナンスして、どのように動かしているのか知りたいと。技術者として当然の話ですよね。「作ること」と「間違いなく安全に動かしていくこと」は別の技術であって、それをぜひ教えてくれと。私たちのノウハウなので全部はオープンにしませんけどね(笑)。―中国以外の国々で有人深海調査船を持っているのは?磯崎:現在、世界で7隻が動いています。日本の「しんかい6500」、フランスの「ノチール」、アメリカの「アルビン」、ロシアの「ミール」1号、2号と「コンスル」、中国の「蛟竜号」です。みな6000m級です。耐圧殻など現在の技術では6000mがひとつのターゲットなのです。―12000mを狙っている国はありますか?磯崎:中国以外はないです。アメリカやフランスは周りに深いところがありませんからね。日本はちょっと南に行けばマリアナ海溝もあるという特殊な環境にあります。これから有人深海潜水船を作りたい国では韓国、ブラジル、インドがあります。たとえばブラジルに6Kが2013年に行ったときに教えてほしいと。韓国も予算がついて勉強していますと聞きに来たことがありますね。ただしフルデプスを目指すのは我々だけです。―フルデプスという言葉自体が魅力的です。では実際に「しんかい12000」でどのような船を作ろうとしているのか、具体的に聞かせてください(続く)
2015年11月27日
米戦略軍の統合宇宙運用センター(JSpOC)は11月25日(現地時間)、米海洋気象庁(NOAA)の気象衛星「NOAA-16」が軌道上で分解したと発表した。詳しい状況はまだ不明だが、スペース・デブリ(宇宙ゴミ)が発生したことが確認されている。JSpOCによると、分解したのは日本時間11月25日17時16分(協定世界時同日8時16分)とされる。JSpOCは世界各地に設けられたレーダーや望遠鏡で、地球の周回軌道上にある大小さまざまな物体の監視を行っている。現時点で、分解の原因は明らかになっていない。考えられる原因として、他の人工衛星やデブリとの衝突や、衛星内の燃料やバッテリーの爆発などが挙げられる。また、発生したデブリの数や軌道も明らかになっていないが、26日朝の段階でJSpOCは「現時点では、NOAA-16の破片が他の衛星に危険を及ぼすことはない」と発表している。ただ、NOAA-16が周回していた高度約850km、軌道傾斜角98度の太陽同期軌道は、地球の大気がほとんどないため、デブリの軌道にもよるが、おおむね年単位で軌道に留まり続けることになると見られる。また、摂動などの影響で軌道も変わるため、いずれ他の衛星などと衝突する可能性がないわけではない。NOAA-16はロッキード・マーティンが開発した気象衛星で、2000年に打ち上げられた。設計寿命は2年とされていたが、その予定をはるかに超えて運用が続けられ、2005年には同じ年の5月に打ち上げられた「NOAA-18」に気象観測ミッションを引き継ぎ、以降は予備機として運用されていた。しかし、2014年6月5日に衛星が故障し、復旧の見込みが立たなかったため、6月9日に運用を終了していた。○同型機はバッテリーの爆発でデブリ化NOAA-16は「タイロスN」という衛星バスを使用して造られているが、このバスを使う衛星の一部には、設計上の欠陥により、配線を留めているハーネスが外れ、配線がバッテリーに触れて短絡(ショート)を起こし、バッテリーが過充電状態となって爆発する可能性があることがわかっている。実際に過去には、「NOAA-6」、「NOAA-7」、「NOAA-8」でバッテリーの爆発が原因と見られる故障が起き、少数ながらデブリが発生したことも確認されている。また、米国防総省の気象衛星「DMSP」のうち、同じタイロスNバスを使っている「DMSP F11」が2004年に、「DMSP F13」が2015年に、バッテリーの爆発が原因と見られる事故によってデブリが発生している。そのため、今回のNOAA-16も同じ原因である可能性がある。参考・Space-Track.Org・JSpOC(@JointSpaceOps)さん | Twitter・POES・NOAA retires NOAA-16 polar satellite
2015年11月26日
11月23日(月・祝)に放送となる、最新の科学技術や最前線の研究も取り入れ、地球の謎を解き明かしていく大型サイエンスアドベンチャー番組「テレビ未来遺産地球絶景ミステリー!」のMCに俳優、歌手として幅広い分野で活躍する及川光博が抜擢。あわせて、同番組で女優の二階堂ふみがリポーターに挑戦していることが判明した。アイスランドの“大地の裂け目”に湧き出す神秘の泉、スリランカの“クジラの村”と世界最大の生物シロナガスクジラの作り出す絶景、インドの満月が照らし出す天空の絶景、そして日本各地の息を呑むような絶景…。地球が誕生してから46億年の間に誕生した世界の絶景を紹介するとともに、あらゆる角度からその絶景を分析し、大自然の神秘に迫っていく。MCとして番組全体の進行を担当する及川さん。スタジオ収録はフルバーチャルで行われ、及川さんが片手を上げてパチンと指を鳴らすと、廻りに次々と世界の絶景やその絶景を分かりやすく分析・解析するCGが登場する仕掛けとなっているそう。フルバーチャルをバックにしたMCについて及川さんは「難しかった。緊張した」と感想を述べているが、収録中は何度もアドリブが飛び出すなど、スタジオでの及川さんのコメントにも注目したい。さらに、『蜜のあわれ』、山崎賢人と共演の『オカミ少女と黒王子』など注目作の公開が控える女優・二階堂さんは本番組でリポーターに挑戦。二階堂さんが訪れたのは「行くのが夢だった」という、火山と氷河の国・アイスランド。同国では北アフリカプレートとユーラシアプレートとの裂け目「ギャオ」を取材。二階堂さんはこの“地球の裂け目”が作り出す絶景を訪ねるため、スキューバーダイビングの免許を取得。「唇の感覚がなくなる」というほど冷たい水に潜ったり、ヘリコプターに乗り込み上空からの取材にも果敢に挑戦した。さらには温泉にも訪れて泥パックを経験するなど、水中、上空、地上からまさに体当たりのリポートを行った二階堂さんは、「アイスランドで見た神秘的な景色は、帰国してからも余韻を残し続けています。大きく存する自然を、お楽しみに!」とふりかえる。プロデューサー・樋江井彰敏氏が「インタビュアー・及川、そして、ドラマでは見ることのできない及川さんが見られると思います」と太鼓判を押す及川さんからは、「金星は近すぎて、火星では遠すぎる。約1億5,000万km。太陽からの距離が絶妙な星、それが地球です。水と緑にあふれ様々な生物が進化を遂げた“奇跡の星”には、やはり奇跡のような絶景が存在します。今回番組では、アイスランドの火山や氷河、スリランカの海で泳ぐクジラの群れ、さらに日本中の絶景などを美しい映像で紹介していきます。みなさんにもぜひ、驚いていただきたいですね。すべては宇宙が作り出したもの。ああ、宇宙ってすごい!!」と熱の入ったコメントが寄せられている。「テレビ未来遺産地球絶景ミステリー」は11月23日(月・祝)20時より放送。(text:cinemacafe.net)
2015年11月16日
アールピージー・ラボ(RPGLABO)は11月9日、毎月の従業員への給与支払いデータなどから、マイナンバーの提出と受領を処理できる「マイナンバー収集キット」の提供を開始したと発表した。同キットは、収集のために必要なハードとソフトがすべて一緒になったもので、クラウドシステムなど不要で、初期費用のみで運用できる。大きな特徴としては、既存の業務フローで発生する「当月給与支払いリスト」「当月報酬支払いリスト」「年末調整宛名データ」といった給与関連のデータを、収集キットをインストールしたPCに読み込ませると自動的にQRコードを生成し、マイナンバーを収集する際に、そのデータとマイナンバーを紐付けることができる点が挙げられる。収集担当者は提出された書類をOCRリーダーで読み込むだけで登録できるので、手入力の必要が無い。一方、マイナンバー収集対象者も「通知カード」「マイナンバー付き住民票」などの必要書類をコピーして提出するだけなので、負担が少ないという。価格は160万円(税別)。キットに含まれるものは、マイナンバー収集システムインストール済パソコン(Windows7 Professionalを搭載)、収集アプリ設定済み iPad(iPad mini2 SIMフリー版)、数字(マイナンバー形式)/QRコードの読み取りに対応したOCRリーダー。また、オプションとして、パソコンの設置が難しい営業所など、遠隔地でのデータ収集のために、iPadとOCRリーダーをセットにした追加オプション(価格は25万円)を用意している。
2015年11月10日
東京都・六本木のFUJIFILM SQUARE(フジフイルム スクエア)は、地球上のさまざまな事柄をダイナミックな写真で読者に届ける雑誌の写真展"ナショナル ジオグラフィック「地球の真実」"を開催している。会期は11月18日まで。開館時間は10:00~19:00。入場無料。同展は、1995年に英語以外の初の外国語版として発行されたナショナル ジオグラフィックの日本版創刊20周年を記念し、同誌の所有する約1100万点に及ぶフォトコレクションから、探検家の活動記録、圧倒的スケールの大自然や野生動物の生態、そして科学、歴史文化などから選んだ写真約100点を展示するもの。創刊から127年を迎えるナショナル ジオグラフィックは、地球上のさまざまな事柄を、綿密に取材した記事と各分野の第一線の写真家たちによるダイナミックな写真で読者に届けており、マチュピチュ遺跡の発掘調査や北大西洋に沈んだタイタニック号の発見など、調査研究・発掘プロジェクトなどを支援し、その成果を記録として雑誌を通じて世界に伝え続けてきたという。また、同展関連イベントとしてギャラリートークが開催される。開催日時は11月6日18:00~、11月8日13:00~および15:00~、11月11日18:00~(各回約30分予定)。入場無料、予約不要。なお、ナショナル ジオグラフィック協会は米国ワシントンD.C.に本部を置く、非営利の科学・教育団体。1888年に地理知識の普及と振興をめざして設立されて以来、1万件以上の研究調査・探検プロジェクトを支援し、自然・動物・文化・歴史・科学など、「まだ見ぬ地球の姿」を月刊誌「ナショナル ジオグラフィック」を通じて世界に伝える。同誌は、現在では40カ国語に翻訳され、世界で約850万人に読まれている。
2015年11月04日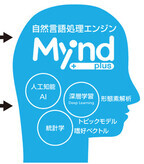
ブレインパッドは10月22日、自然言語処理エンジンの「Mynd plus(マインドプラス)」の提供を開始した。同サービスは、ブレインパッドが提供する「Semantic Finder (セマンティックファインダー)」と、グループ子会社となるMyndが提供する「Mynd Engine (マインドエンジン)」を統合した新サービスで、テキストなどのデジタルデータを独自のアルゴリズムで解釈・処理し、従来人の手で行ってきた業務を「より早く」「より精緻に」処理するほか、人の手では行えない「より高度な」データの処理も実現する。これにより、デジタル・マーケティング領域での活用だけでなく、さまざまなビジネスシーンでの活用が期待できるという。同社は活用例として、Webメディアなどの記事コンテンツに対して「自動タグ付与」や「自動分類」、Webサイト上の類似コンテンツ・類似ユーザーを軸とした「レコメンドコンテンツの抽出」、Webメディアの大量記事や論文などの「自動要約」、コールセンターや相談業務上発生する会話データの「テキストマイニング」、アンケートや口コミのデータなどの「テキストマイニング」などを想定する。
2015年10月23日
腕や脇、脚などのムダ毛処理はきちんとしておきたいですよね。女子力アップのためにムダ毛処理を徹底して行っている人も、意外と見落としているところがあるかも?手や脚などはツルツルでムダ毛の心配はないのに、顔に産毛が…という悲惨な状態になっていませんか? 意外と見ている男性は多く、「他にムダ毛がないからこそ、余計に気になる」と思っているようです。そこで顔の産毛を簡単に処理する方法をご紹介していきます。■産毛のお手入れ方法は?顔の産毛のお手入れ方法はいくつもあるので、自分に合った方法を取り入れましょう。電動シェーバーを使うエステに通うフェイス用の脱毛器を使用する市販のカミソリで剃るもっともキレイに仕上げるには、やはりエステに通うのが1番ですが、お金や時間がネックになりますので、手軽に使える市販のカミソリでの処理方法を解説していきます。 ■フェイス用カミソリでお手軽処理!フェイス用カミソリは、T字タイプ、I字タイプの2つを用意しておくと便利です。また、処理前にはきちんとメイクや汚れを落とすことが大切! 汚れた状態で処理すると、毛穴に雑菌が入りやすくなり、肌トラブルの原因になりかねませんので、しっかりと汚れを洗い落としましょう。顔の汚れを落としたら、蒸しタオルを使って、顔全体を温めます。これは毛穴を開いて肌を柔らかくして処理しやすくするためです。次に美容クリームを顔に塗り、カミソリが滑らかに動くようにします。これは肌への負担を抑える働きもあるので、たっぷりと塗るのがベスト。次に産毛の流れに沿って、ゆっくりとカミソリを滑らせていきましょう。逆から剃ると産毛が目立ってしまうので必ず毛の流れに沿って剃るようにしてくださいね。キレイに剃れたらきちんと洗顔をして、あとはしっかりと保湿して終了です。■産毛をケアするとどんなメリットがある?顔の産毛を処理すると、化粧のノリがよくなり、ファンデーションのもちも良くなります。また、肌が1トーン明るくなる美肌効果も。周りから見ても産毛が生えている顔よりも、きちんと処理されていた方が、清潔感があるでしょう。たくさんのメリットを実感できるので、顔の産毛ケアはしっかりとしておきたいですよね。慣れれば簡単にできるケア方法なので、ぜひ実践してみてください。
2015年10月05日
防衛省は9月25日、装備品への適用面から着目される大学、国立研究開発法人などの研究機関や企業などにおける独創的な研究を発掘し、将来有望な研究の育成を目指して2015年度より開始した安全保障技術研究推進制度において9件の研究課題を採択したと発表した。募集期間は2015年7月8日から8月12日で、応募総数は109件。大学などから58件、独立行政法人などの公的研究機関から22件、そして民間企業などから29件の応募があったという。なお、今回採択された9件の研究テーマと研究代表機関は以下の通り。
2015年09月26日
○GPUは超低速プロセサ図3-28に示したように、GPUは、演算命令を処理するには10~20サイクルを必要とし、ロードストア命令を処理するには400~800サイクル掛かる。仮に、実行する命令の70%が演算命令、30%がロードストア命令とすると、中央値を取って、1命令あたりの平均的な処理サイクル数は15×0.7+600×0.3=190.5サイクルと計算される。そして、クロックが1GHzとすると、1命令を実行するのに190.5ns掛かることになる。一方、IntelのCoreプロセサなどでは、1命令を処理するのに必要なサイクル数は1~2サイクル程度であり、クロックを2.5GHzと想定すると、1命令を実行する時間は0.6ns程度ということになる。つまり、命令の実行時間の比は190.5対0.6で、GPUはCPUと比べると317.5倍遅い超低速プロセサである。そんな物好きな人はいないと思うが、殆ど並列性の無いgccコンパイラをGPUに移植したとすると、この程度の性能比になると思われる。しかし、速度の測り方は色々とある。スポーツカーとバスのどちらが速いかと聞かれれば、普通はスポーツカーと答えるのであるが、50人を目的地まで運ぶ場合はどちらが速いかと言われれば、スポーツカーで50往復するよりも、バスで50人を1回で運ぶ方が速いに決まっている。CPUは、乗客は助手席に1人乗せられるだけであるが、とにかく速く走れるように設計されたスポーツカーであるのに対して、GPUは定員一杯の乗客を乗せた場合に最大の効果を発揮するバスである。そして、バスのメリットをフルに発揮するには、運行する全区間で、満員の乗客を乗せて走る必要があり、これに近い状態で運行することが重要である。そして、乗客として、バラバラのところに行く人を集めてもだめで、まとまって同じ目的地(米国のスクールバスの場合は学校)に行く人を集めなければならない。これをGPUの用語で言うと、並列に実行できる最大スレッド数に近い数の、ほぼ同じ処理を行うスレッドを集めて並列処理を行うことがGPUの効率を発揮するためには欠かせないということになる。
2015年09月25日
地球上には現在、3兆本以上の樹木があります。最新の調査によって、2年前に推定されていた40億本よりも、はるかに多い数の樹木が地球上に存在していることがわかりました。しかし、そんなにたくさんあるなら大丈夫だと安心はできません。なぜなら、人類が生まれる前は、樹木は現在より46%も多かったからです。樹木は毎年150億本失われており、植樹は50億本しか行われていません。このままでは地球上の樹木は減る一方です。『Mint Press News』では、止まらない森林破壊に警鐘を鳴らしています。私たちと樹木との関係は、これからどうなってしまうのでしょうか?■テクノロジーの発達で地球上の樹木の数が判明!森林は地球のメカニズムのなかでも、もっとも重要な役割を果たしている機関です。ところが人類がその重要性に気づき、保持しようと動き始めたのはごく最近。そもそも人類は、自分たちが生活しているこの地球上に、どれだけの樹木が存在しているのか把握していなかったのです。これまで、今回のような大規模な森林調査が行われたことはありませんでした。しかしこの調査結果は、炭素除去などの地球規模の自然のメカニズムを知るのに役に立つのだといいます。樹木の数は、大気中の炭素除去や土壌改良、水や大気の浄化など、人間が暮らすために必要なさまざまなことに関係しています。にも関わらず、いままで地球上の樹木の数は正しく把握されてこなかったのです。それは地球があまりに広大で、木の数を1本1本数えることなど到底不可能だったから。しかし、技術の発達により、今回のような地球規模の調査を行うことが可能になりました。人口衛星による映像や、コンピューターによる解析など、あらゆるテクノロジーを駆使することにより、地球上の樹木の数が明らかになったのです。■森林の状態から生活に与えられる影響が明らかにいちばん樹木が多い地域は熱帯でした。熱帯には全体の43%もの樹木が集まっているのです。しかし、樹木の密度の高さで勝っているのは、北方の針葉樹林帯。どの地域でも森林破壊は起きていますが、熱帯はその割合が一番高い地域でした。森林破壊の様子を見ていると、人類の出現により、環境のシステムが変化してしまったことが伺えると研究者は語っています。私たちはすでに、環境破壊が私たちの生活に与える影響を知っています。しかし、この調査によって、人類はさらに森林を守り、増やす努力をしなければならないことが明らかになったのです。*日本は、国土面積の66%が森林という森林大国。世界的に見ても、フィンランド、スウェーデンに次いで3位の森の国です。森林の数自体はあまり心配しなくてもいいようですが、木材のために植えられた人工林が手入れされずに、山が荒れているなど、違った問題が発生しています。人間が生きていく環境を整えるために、なくてはならない森林。私たちは森林破壊が生活に与える影響をもっと真剣に考え、行動を起こさなければならないのかもしれません。(文/スケルトンワークス)【参考】※Humankind Has Halved The Number Of Trees On The Planet-Mint Press News※日本の森林面積と森林率-森林・林業学習館
2015年09月23日
欧州委員会は9月15日(現地時間)、「Italian military to switch to LibreOffice and ODF|Joinup」において、イタリア防衛省が向こう1年半かけてLibreOffice およびOpen Document Formatの採用を進めると発表した(アナウンス: Accordo di Collaborazione tra Associazione LibreItalia ONLUS e Difesa per l’adozione del prodotto LibreOffice quale pacchetto di produttività open source per l’Office Automation)。欧州委員会の説明によれば、イタリアの防衛省は2015年10月から1年半をかけて15万台ほどのPCにLibreOfficeの採用を進めるとして、2016年中には作業の完成を目指している。欧州ではフランスの内務省が24万台ほどのPCでオープンソースのオフィスアプリケーションを採用しており、今回のイタリア防衛省の取り組みはこれに次ぐ規模のオープンソースへの取り組みとなる。イタリア公的機関の電子化を進める同国当局は今回のこの発表を好ましいものととらえ、他の機関もこの取り組みにならうことを期待するとしている。イタリアでは2012年6月に国の公的な取り組みにおいてオープンソース・ソフトウェアをデフォルトの選択肢として提供するという法律が定められており、今回は発表はこの法律の制定を受けたものとされている。
2015年09月16日
太陽系惑星の中で生物が存在しているのは、地球だけだと考えられています。ではなぜ、地球だけなのでしょうか?それはまずハビタブル・ゾーン(生命居住可能領域)と呼ばれる気温が安定している場所に位置しているためです。では、他の太陽系の惑星はどうなのでしょう?地球のように生物が存在できる環境って、本当にないのでしょうか?惑星の温度に焦点を絞って、考えてみましょう。■地球は時間や季節で気温が変わる地球の表面温度は、気温を測定する時間や、季節、そして場所によっても変わってきます。地球は約24時間に1回自転しますが、地球の片側には光が当たらない時間ができるため、昼には気温が上がり、夜には下がります。また、地球の傾斜軸は、太陽の黄道に対して約23度傾斜しています。そのため北半球と南半球は夏と冬の間、片方が太陽に近づきもう片方は離れるため、季節が真逆になります。季節の変化がない地域もあり、赤道上では平均気温が他よりも高く、雨季になると気温も少し変化しますが、寒暖の変化がほとんどありません。これは、赤道に到達する日光の量があまり変化しないからです。■最高気温と最低気温は163.9度差!地球表面の平均気温はおおよそ14度ですが、地域によってかなり差があります。記録的な最高気温は、イランのルート砂漠で観測された70.7度です。一方、記録的最低気温は1983年7月21日に、旧ソ連の南極観測基地であるボストーク基地で観測された-89.2度です。2010年8月10日には、人工衛星により、再び南極で-93.2度が計測されましたが、地表で計測されたものかわからないので、ボストーク基地での記録がいまだに歴史的最低気温になっています。それでは他の惑星はどうなのでしょう。■他の惑星はもっと極端な気温差が地球の気温は、1日の時間、季節、場所によって変動しますが、太陽系の他の惑星に比べるとかなり安定しています。水星の気温は、極端な暑さから極限の寒さまで幅広く変化します。これは太陽に近く、空気が無く、自転の速度が遅いせいです。気温は、太陽光のあたる側では465度まで上がり、あたらない側では-184℃まで下がります。金星は、二酸化炭素と二酸化硫黄を含む大気のおかげで、温室効果が生じるため、太陽系の中でもっとも熱い惑星です。気温が一番高い時で460度まで上がります。火星の表面の平均温度は-57度ですが、赤道では日中に20度まで上がり、両極では-153度まで下がります。気温差はあまりなく、ハビタブル・ゾーン(生命居住可能領域)のぎりぎりの外縁部に位置していますが、地球よりずっと寒く大気も薄いので、生物が熱を保つのには不十分です。木星は巨大ガス惑星で、地面が固体でなく、地表の温度を正確に測ることはできませんが、雲の上から測定すると、気温は推定-145℃です。土星は、平均気温-178℃の冷たい巨大ガス惑星ですが、傾斜しているので、南半球と北半球が別々に温められて、季節ごとに気温が変化します。天王星は、太陽系で最も冷たい惑星で、記録にある最低気温は-224度です。一方、海王星の上層大気の温度は、-218度まで下がります。このように、太陽系惑星の気温差には幅があります。その中で、地球だけが気温が安定していて、生命を維持できる環境を作り出しているのです。■地球ほど安定した気候の惑星ない地球は3.75億年前の太陽系の初期、太陽光は現在の25%ほど弱く、地球の大気はまだ形成過程でしたが、メタンガスと二酸化炭素の濃度によって、地球の原子大気は地表の温度を氷点以上に保持できていたようです。地球ではまた、2.4億年前に5度の氷河期を含む断続的な気候変動がありました。氷期と氷期の間には、間氷期があり、この時期に地球の気温は上がり、雪解けが起きました。二酸化炭素と温室効果ガスの濃度が上がったおかげで、20世紀半ば以降、地表の平均気温は安定して上がっていきました。しかしどれだけ長い氷河期を迎えても、他の惑星と比較すれば安定した気候と言えるのです。太陽系惑星の温度は、それぞれにかなり違います。しかしほとんどが極端に熱かったり、冷たかったりして、安定した気候を作っている惑星は地球以外には無いようです。やはり、今のところは地球だけが寒暖差が少なく安定した状態を維持できているので、生物が存在するのです。私たちが将来、生命体を発見できるとしたら、太陽系から遥かかなたにある惑星なのかもしれません。(文/スケルトンワークス)【参考】※What is Earth’s Average Temperature?-io9.com
2015年09月12日
2015年1月から3月までテレビ放送され、男子高校生たちが地球を守るために魔法少女を彷彿とさせる戦士姿に変身するという斬新な設定で人気を博したアニメ「美男高校地球防衛部LOVE!」のイベントが8月9日(日)日比谷公会堂にて開催。メインキャストの山本和臣、梅原裕一郎、西山宏太朗、白井悠介、増田俊樹に、福山潤、寺島拓篤ら人気声優陣が登壇し、最後にはアニメ第2期制作決定のニュースで会場を大いに沸かせた。とある街の眉難高校「地球防衛部=何もしない部」の男子高校生5人が、謎の桃色の生物ウォンバットと出会い“バトルラバーズ”に変身し、愛と勇気とラブメイキングで愛する地球のために戦う物語を描いた本作。アニメ放送以外にも、山本さん、梅原さん、西山さん、白井さん、増田さんら5人がパーソナリティを務めるニコ生放送や、キャラクターソングCD発売、ゲーム化、コミック化と様々なメディアミックス展開がファンの心を掴み、放送終了後もその人気と勢いは衰え知らずだ。これまでもイベントが開催された本作だが、今回のイベントでは初めて、地球防衛部と対峙する地球征服部(生徒会メンバー)から福山さんと寺島さんが出演。総勢7名の人気声優たちが浴衣姿で登場すると、イベント開始早々、会場のボルテージはMAXに。そんな熱気の中、イベントは防衛部と征服部に分かれ対決形式で進行。アニメ本編をクイズで振り返るコーナーや、劇中に登場するハリネズミキャラを模したダーツを使ったゲームコーナーが行われ、大喜利的な珍回答や「自分」というタイトルで必至に即興ポエムを披露する増田さん、福山さん、西山さんの姿に、会場からは終始爆笑が巻き起こった。特に盛り上がりをみせたのが、本作のニコ生「バトルナマァーズ」で人気の、カッコイイ台詞で如何に女性を口説くかを競う「ラブメイキング対決」コーナー。今回は“お祭りに一緒に来た女子がキュンとする愛の告白”をお題にそれぞれが女性を口説くシチュエーションを熱演。女性役を演じる福山さんを後ろから抱きしめる西山さんや、「2人で愛の打ち上げ花火、打ち上げようぜ」とセクシーに決める白井さん。また、梅原さんからはまさかの下ネタ台詞が飛び出し、会場は割れんばかりの黄色い悲鳴に包まれた。さらに、テクニシャンな口説きシーンを演出した山本さんや、いきなりキスで迫り「続きは祭りの後で、な」と笑顔を投げた寺島さんなど…思い思いの演出に、詰めかけた女性ファンの熱い歓声が止むことはなかった。その後イベントは、初実施となる朗読コーナーや、地球防衛部によるライブと続き、福山さんと寺島さんのコーナーでは様々な撮影裏話が明らかに。実はズンダー役の声優・安元洋貴が地球防衛部役でオーディションを受けていたことや、豪華すぎることで話題を呼んだ毎話のゲスト声優たちについて知られざるキャスティング秘話が語られると、客席からは驚きの声が漏れた。そして、イベント終盤に本作の第2期制作決定のニュースが突如発表! 何も知らされていなかった5人はステージ上で呆然と立ち尽くしたり、ジャンプしたり、しゃがみ込んだりと動揺している様子。だが、目にキラリと光るものを浮かばせながら大喜びする姿に、客席から「おめでとう!」と大きな祝福の声が贈られるとともに、多くの観客の目にも涙が浮かんでいた。この発表を受け、寺島さんと福山さんは「僕らも嬉しくなった。これが実現したのは彼ら(メインキャスト5人)の頑張りとみんなの愛のおかげなんだな、と思って温かい気持ちになった」(寺島さん)、「5人がいろんなことを本当に頑張ってきた作品で2期に行けるっていうストーリーを、先輩として、また同じ制作者のひとりとして、見てると胸が熱くなる」(福山さん)と先輩らしい暖かいコメントを寄せた。最後に、メインキャスト5人からもそれぞれ感想が述べられ、「こうやって1つずつ階段を登って、永遠に続くコンテンツにしていきたい」(増田さん)、「メインキャストを演じるのも2期をやるのも初めて。自分にとって大事な作品がもっと大事になった」(白井さん)、「1期ではすごく背中を押してもらえた。2期からは僕たちの背中についてきて下さい」(西山さん)、「2期ではもっとキャラを深く知ることができるんじゃないか」(梅原さん)、「皆さんの生活の一部になるくらい傍においてもらえたら」(山本さん)と、みな一様に応援してくれているファンに熱い感謝を述べた。未だ内容や放送時期などは未発表だが、今後も本作が益々盛り上がるのは間違いない。「美男高校地球防衛部LOVE!」で一躍知名度を上げたメインキャスト5人の更なる活躍とともに、本作の続報に期待したい。(text:cinemacafe.net)
2015年08月10日
今回はファイル処理をメインに取り扱います。実際の業務で使うアプリケーションやサービスは、なんらかの形でファイルを利用する場合が多いです。たとえばCSV(カンマ区切りの表)を読み込んだり、書き出したり……。また、アプリケーションの状態(設定など)やログを残すためにファイルを利用することもあります。ファイルにはバイナリ(01)で構成される画像ファイルや、テキストで構成されるテキストファイルがあります。バイナリのファイルがどのようなものかについても軽く触れますが、初心者はあまり操作しないと思うので、テキストファイルが話の中心となります。そのため、テキストファイルを扱うために必要なテキスト処理についても扱います。なお、日本語テキストの処理などについては別途扱います。○テキストを生成する方法テキスト処理は要するに、文字列型の処理です。第5回で簡単に扱ったのですが、テキストファイルの処理では文字列型の処理が必須となるので少し発展させて復習します。まず、文字列は以下のように定義するのでした。text1 = ’hello python’text2 = ’’’helloworldpython’’’ひとつめに関しては今さらいうこともないですが、2つめに関しては複数行でテキストをプログラム中で定義する方法でしたね。記号「’」の代わりに記号「"」を使うことも可能ですが、文字列の前後で統一されている必要があります。文字列の結合に関しては「+」記号でできますが、数字などを結合するときは「文字列に変換」してから結合するのでした。ほかの型から文字列型への変換にはstr関数を使います。print(’hello ’ + ’world’)# hello worldprint(’hello ’ + str(5)) # hello 5結合の代わりに、文字列にテキストや数字を埋め込むという手法で文字列を生成することも可能です。>>> ’hello {} {}’.format(’python’, 5)’hello python 5’文字列のformat関数(メソッド)の引数に {} に対応する文字列なり数値なりを与えています。このformat関数の使い方を詳細に伝えるとそれだけで連載2~3回分になってしまいますので、詳しくはこちらのドキュメントをご参照ください。結合より埋め込みのほうがコードがきれいになる場合が多いので、積極的に活用してもらいたいです。文字列のフォーマットに関わるところでは、ほかには数値の整形をしたいことがよくあります。たとえば、1,2……というように連番でテキストを表示なり書き込みする場合、なにも配慮しないと次のように桁数が違うとガタガタになってしまいます。1: some text2: some text……9: some text10: some text11: some text……次のように0で揃えられているときれいですね。01: some text02: some text……09: some text10: some text11: some text……このような場合には以下の方法で文字列の数字に「0詰め」をすると便利です。zfillで桁数を指定したり、先のformat関数に出力の細かい指定をしたりしています。print(’5’.zfill(5)) # 00005print(str(101).zfill(5)) # 00101print(’hello {0:05d} world’.format(5)) # hello 00005 world最後に文字列で使われる特殊記号についてお話します。特殊記号はプログラム中で意味を持ってしまう特別な記号のことです。たとえば「’」という記号は文字列を作成する際に利用する特別な記号です。そのほかにはビープ音なども記号に分類されます。これらは文法的な理由やそもそもそれを表現する記号がキーボードのキーにないことから、「これは XX ですよ」という特別なルールにもとづいて文字列に表記します。そのルールに利用されるのがエスケープ記号と呼ばれるもので半角のバックスラッシュ「\」(英語キーボード)か、半角の円記号「\」(日本語キーボード)を利用します。このエスケープ記号の後に特別な文字を続けることで、それが特別な意味を持つのです。たとえば「’」とビープ音は以下の用に記載できます。print(’escape sample1 \’.’)print(’escape sample2 \a.’)ほかには改行とエスケープ記号自身あたりをよく使います。print(’escape sample1 \n.’)print(’escape sample1 \\.’)エスケープ記号一覧はこちらのページの中央付近に記載されています。なお、記事掲載時から時間が経ってリンク切れしている場合は、適当に検索するなどして調べてみてください。○テキストを加工する方法テキストの生成について取り扱ったので、次はそのテキストを加工する方法について扱います。基礎的な機能を順に紹介していきます。これ以外にも多数の機能がありますが、必要になった時点で調べて覚えていけばよいでしょう。まず、文字列中の「文字」の取得ですが、以下のように [X] で位置を指定して行います。>>> text = ’hello world python’>>> print(text[4])o>>> print(text[100])Traceback (most recent call last):File "<stdin>", line 1, in <module>IndexError: string index out of range>>> print(text[-4])tこの位置の指定はリストの要素の数え方と同じで0から始まります。先頭から0、1、2……と数えていくと4はoに対応していますね。範囲を超えてしまうとエラーになります。面白いのがこの値をマイナスにできるところです。このように指定すると後ろ側から取得してきます。この際、0からではなく-1、-2、-3……とカウントすることに注意してください。文字列から「文字列」を取得するには、以下のように行います。>>> text = ’hello world python’>>> print(text[6:11])world>>> print(text[-12:-7])worldこれは「スライシング」と呼ばれるテクニックで、[X:Y]とあるとXからYまで取得という意味になります。[X:Y] と指定する際はX < Yとなるようにしてください。先ほどと同じように、範囲指定にもマイナス値を利用できます。前と後ろを指定するのではなく、Xより前、Xより後という指定の仕方も可能です。>>> print(text[6:])world python>>> print(text[:11])hello world>>> print(text[:])hello world python見ていただくとわかるように [X:Y] の片方を省略しています。そうすると先頭から、もしくは末尾までという意味になります。あまり使いどころはありませんが、両方とも省略すると、文字列のすべてが取得されます。次に文字列の置き換えです。テキストエディタなどである特定のキーワードを別のキーワードに置き換えることがあるかと思いますが、それと同じ要領です。>>> text = ’hello world python’>>> print(text.replace(’o’, ’0’))hell0 w0rld pyth0n>>> print(text.replace(’world’, ’WORLD’))hello WORLD python>>> print(text)hello world python文字列.replace(置き換える文字列, 置き換えられる文字列)とすると、変換された文字列が返されます。例にもあるように、元の文字列自体は変化していないので注意してください。文字列の検索もそれほど難しくはありません。検索には「存在の確認」と「位置の確認」の2つの使い方があり、それぞれ次のようになります。>>> text = ’hello world python’>>> ’wor’ in textTrue>>> ’w0r’ in textFalse>>> text.find(’wor’)6>>> text.find(’w0r’)-1>>> text.find(’o’)4inについてはlistでの使い方とほぼ同じですね。find については最も左側にあるマッチした位置を返します。そのため、’o’は何個もありますが、一番左の位置となっています。マッチしない場合は-1が返ってきます。それほど使う場面は多くないのですが、前側を指定した数だけ飛ばして途中から検索したり、右側から探索をすることも可能です。>>> text.find(’o’, 10)16>>> text = ’hello world python’>>> text.rfind(’o’)16次に文字列の前後からの特定の文字の削除です。よく利用するのは、前後の空白や改行コード、タブなどを取り除く場合などでしょう。>>> text = ’ hello world \n’>>> text.strip()’hello world’>>> text.strip(’ hell’)’o world \n’strip関数に引数を指定しないと、文字列の前後の空白とタブ、改行が取り除かれます。引数に文字列を指定すると、その文字列が取り除かれます。また、特定の区切りで文字列を分割して文字列のリストにすることも可能です。「,」記号で要素が区切られたCSV(Excel出力)やログの解析あたりでよく使うテクニックです。>>> text = ’1, taro, 35, male’>>> text.split(’,’)[’1’, ’ taro’, ’ 35’, ’ male’]text = ’’’1, taro, 35, male2, jiro, 29, male3, hanako, 23, female’’’for line in text.split(’\n’):elems = line.split(’,’)print(’{} {}’.format(elems[1].strip(), elems[2].strip()))# taro 35# jiro 29# hanako 23分割の逆で文字列を「特定の文字列」で結合していくことも可能です。2次元配列(リストにリストが入っている)に格納された情報をCSV形式でファイルに書き出したりする際に便利な手法です。書式は「結合に使う文字列.join(文字列のリスト)」となります。>>> l = [’1’, ’taro’, ’35’, ’male’]>>> ’, ’.join(l)’1, taro, 35, male’○ファイル処理の概念ファイル処理については、プログラミングというよりも「OSのファイル処理の方式」をまず理解しておく必要があります。そのため、最初にファイル処理の概念について説明します。これがわかってしまえば、その利用はさほど難しくありません。なお、プログラムがどのようにファイルを扱うかは、OSの仕組みにもとづいているため、多くのプログラミング言語でさほど変わりません。ファイル処理がOSにおいてどう実現されているかを抽象化すると以下のようになります。実際はもっと複雑ですが、通常のプログラミングではそこまで意識する必要はないので詳細は割愛します。まずご存知のようにOSにはディレクトリがあり、それが階層構造を作っています。ファイルはそのディレクトリのなかに保存されています。OSはこの階層構造を管理しています。ディレクトリやファイルは、サイズなどの情報と共にポインタのようなものを持っていて、それがファイルの実体を指しています。構造についての話はこれぐらいにして、実際にファイルをどのように処理するか話をしましょう。OSにおけるファイル処理は主に以下のような流れとなります。まず絶対パス(ルートやCドライブなどからのパス)や相対パス(現在いるディレクトリから指し示すパス)を使ってファイルを指定します。それに対して読み、書き、読み書きなどのモードを指定してファイルをオープンします。そして読み書きなどの必要な処理を繰り返し、処理がすべて完了したらファイルをクローズして終わりです。クローズし忘れないようにしてくださいね。読み書きなどの具体的な処理はそれほど難しくありません。一言でいってしまえば、「テキストファイルは行ごとに処理する」「バイナリファイルは先頭から何バイトめか(位置)を指定して処理する」ことです。たとえば、テキストファイルで以下のものがあるとします。worldpythonjavaこの内容にすべて"hello "を加えて画面に表示するというプログラムを書く場合、ループ処理を利用してということを繰り返して処理するのが一般的です。「テキストファイルは行ごとに処理する」のが基本であることを覚えておいてください。次にバイナリファイルです。バイナリファイルは中身が01から構成されているファイルで、一般的には画像ファイルや音声ファイル、それに加えてアプリケーション特有のファイル(たとえば word など)があります。こちらはテキストと違うのでそもそも行という概念がありません。正直なことをいうと、テキスト処理よりもバイナリファイルの処理は骨が折れます(笑)。ただ、ファイルを読み書きできないかというと、そんなことはありません。そのバイナリファイルの構造を知ってさえいれば操作は可能です。著者はビットマップ形式の画像ファイルの合成とWAV形式の音声データの加工の経験があるので、それをベースにしてバイナリファイルの処理についてお話をします。ビットマップは以下の図のように、ピクセルから構成されている画像ファイルです。それぞれのピクセルはRGB(赤緑青)で表現されています。それぞれの色は1バイト(0~255)の容量があるので、ようするに1ピクセルは3バイトです。つまりファイルサイズは「縦のピクセル数×横のピクセル数×3」バイトになります。ここまでわかってしまえば、あとは簡単です。たとえば画像Aに画像Bをオーバーレイ(一部上書き)するとします。この際、Bの画像の黒(RGBが0, 0, 0)は透過させます。すると、以下の図のようにして合成が可能です。Bの左上は黒なのでAのものを合成画像に利用。その右隣は黒ではないのでBのものを利用。その右隣はA……といった感じでどんどん処理をしていくと、最終的に右の図のようになります。これをファイルに書き込めば、自分でバイナリファイルを作ったことになります。次にWAV音声ファイルです。これも比較的わかりやすい形式ですが、先ほどのビットファイルと違って「ヘッダ」と「データ」に分かれています。データは先程のビットマップと同じく音声のデータ(波形)を含んでいるだけなので簡単ですが、ヘッダにはデータをどのように表現するかといった情報が含まれています。後ろのデータを変えれば当然再生される音も変わりますが、その際に必要に応じてヘッダを変更する必要があります。最後にバイナリデータの処理のコツを伝えます。それは「プログラムで処理しやすい生(raw)の形式に一旦戻す」ということです。たとえばビットマップであれば編集は簡単ですが、JPEGやPNGを編集するのは非常に難しいです。そのためまずはJPEG → ビットマップに変換してやり、ビットマップで編集を行った後に再度、ビットマップ → JPEGに変換すればよいのです。音声も同じでmp3を直接編集するのではなく、mp3 → wav → 編集 → new wav → mp3とすればよいです。これらの変換には組み込みもしくは外部のライブラリを使用してかまいません。○実際にファイル処理をしてみよう長くなりましたが、実際に pythonでテキストファイルの処理をどのようにするか紹介します。先ほどの概念さえわかってしまえば非常に簡単です。worldpythonjavaと書かれたテキストファイルtext.txtの各行にhelloを加えて表示するサンプルを書いてみます。f = open(’text.txt’, ’r’)print(type(f))for line in f:print(’hello ’ + line)f.close()まずファイル ’txt.txt’ をモード ’r(読み)’ でオープンしています。オープンしたファイルオブジェクトに対してfor文を使うと1行1行取得できるので、行ごとにprintする処理をしています。これを実行すると以下のような出力となります。<type ’file’>hello worldhello pythonhello javaprint文の改行に加えて、もとのテキストの改行も表示されるので1行スペースがあいてしまっていますね。print文の改行をなくすには以下のようにprint文の後に「,」を書けばよいです。print(’hello\n’),print(’world\n’),ほかにはファイルを丸ごと読む方法もあります。f = open(’text.txt’, ’r’)text = f.read()print(text)lines = text.split(’\n’)print(lines)f.close()ファイルオブジェクトに対してread関数を使うことで、その中身をすべて文字列として取得します。それを行ごとに処理したいのであれば、文字列を先に説明した改行コードで分割することで行ごとのリストになるので、それに対して処理を行うことができます。次に書き込み方法について説明します。書き込みも読み込みと大差ありませんが、ファイルをオープンする際に書き込みモードを指定します。以下のテキストファイルtext.txtに書き込みをするとします。hello書き込みのコードは以下となります。f = open(’text.txt’, ’w’)f.write(’123’)f.write(’456’)f.close()コードを見てもらうと想像がつくとは思いますが、openの第二引数が書き込みモードの ’w’ となっています。そしてファイルオブジェクトにたいしてwriteすることで、実際にファイルに書き込み処理がされています。最後にクローズですね。するとファイル text.txt は以下のようになりました。123456見てもらうとわかるように、もともとのテキストであるhelloが消えていますね。上書きされていることがわかります。ただ、場合によっては「追記(もとの中身を残したまま後ろに加える)」しないといけないこともあります。その場合はモードを ’a’ の「追記」にすれば実現できます。モードのみ修正して以下のコードにしてみます。f = open(’text.txt’, ’a’)f.write(’123’)f.write(’456’)f.close()これを実行すると、123456123456となりました。もとの ’123456’ は残ったままで、その後ろに ’123456’ が新しく追加されていますね。ファイルのオープンごとに以前の内容が消えないので、アプリケーションのログなどを取る際に便利な手法です。なお、書き込みを「次の行」にする場合は「\n」を書き込めばいいです。最後に小ネタを話して終わりたいと思います。ファイル処理をする際に心の片隅においていただきたいのが「バッファリング」という処理です。ご存知かもしれませんが、ハードディスクへのアクセス速度はメモリへのアクセス速度に比べて何桁も遅いです。そのため、ファイルを何度も細かく書くことを繰り返しているとプログラムが非常に低速になってしまいます。この問題を防ぐために、出力があるたびに毎回ディスクに書き込むのではなく、メモリ上の高速な一時領域にデータをおいておき、まとめてそれを書き込むという処理が行われます。こうすることで低速なディスクアクセスの回数が減らせるのでプログラムが高速化されます。これがバッファリングの基本的な概念です。以下にこれを図で示します。このディスクへの書き込みは特定のタイミングで発生するようですが、それを強制的に行いたい場合はflush()関数を使います。f = open(’text.txt’, ’w’)f.write(’123’)f.flush()f.write(’456’)f.close()closeのタイミングで必ず書き込まれるので、今回のようにopenからcloseまで時間が短い場合はflushは不要です。ただ、openしっぱなしで、なかなかcloseしないようなプログラムは適切なタイミングでflush するように心がけてください。でないと、プログラムが強制終了されてしまった場合などに、ファイルに書き込みがされていない可能性があります。以上でファイルに関する基本的な話は終了です。ある特定ディレクトリ配下のすべてのファイルを調べるのに便利なglobや、リソース管理のwith文などもあるのですが今回は割愛します。便利なのである程度レベルがあがったら、ぜひ自分で調べてみてください。○「Pickle」とは最後に「Pickle」についてご紹介します。PickleはPythonのデータをファイルに保存し、それを読み取って復元する目的で使えます。あるアプリケーションで終了時に保持するデータをPicklで保存し、再度開いた際にPickelで読み取れば、前回終了した際の状態に戻すといった使い方ができます。Pickle の使い方はそれほど難しくないので、以下にサンプルを載せます。import picklea = {’hello’:1, ’world’:[1,2,3]}f1 = open(’test.dump’, ’wb’) # WRITEpickle.dump(a, f1)f1.close()f2 = open(’test.dump’, ’rb’)b = pickle.load(f2) # READf2.close()print(b) ## {’world’: [1, 2, 3], ’hello’: 1}まずPickleパッケージをインポートしています。そして書き出すファイルを書き込みモードでオープンし、pickle.dump関数でデータをファイルに書き込んでいます。Pickleで書き込まれるデータはバイナリなので’w’ではなく’wb’でバイナリとしてオープンしています。’w’でもおそらく問題はないと思います。次に Pickleのデータが書き込まれたファイルから中身をロードしてきています。これには pickle.load 関数を使っています。’wb’と同様に、こちらもバイナリの読み込みなので’rb’でファイルをオープンしています。簡単ですね。演習1以下のCSV形式のテキストデータから教科ごとの生徒の平均点を算出してください。text = ’’’lecture\students, 1, 2, 3, 4math, 80, 70, 75, 54english, 60, 80, 90, 80’’’可能なら生徒や教科が増えても対応可能なプログラムにしてください。演習2あるテキストファイルAの内容を読み取り、まったく同じ内容をファイルBに書き出すプログラムを書いてください。演習3演習2で作ったプログラムを改良し、ファイルBに行番号を書き出すようにしてください。ただし、行番号は最後の行の桁数にあるように0詰めしてください。たとえば以下のようになります。abc……ijk……z01 a02 b03 c……09 i10 j11 k……26 z演習4標準入力で入力されたテキストをpickleでファイルに保存してください。そしてそれをロードして、画面に表示してください。さまざまなデータをPickleで保存して、そのファイルを開いて中身を確認してみてください。※解答はこちらをご覧ください。次回は正規表現と日本語の扱いについて解説します。
2015年08月10日
SCSKは8月7日、コールセンターにおいて音声認識されたテキスト文章などをもとに、苦情の発見、離反、成約をリアルタイムに予測するシステム「VOiC for SAP HANA」を9月から提供すると発表した。「VOiC for SAP HANA」では、音声認識技術を用いて問い合わせ相手とオペレーターの会話を瞬時にテキスト化し、会話内容から苦情の発生や満足度の向上・低下の確率をリアルタイムに算出する機械学習モデルを構築している。モデルによる判定は、単なるキーワードのマッチングでなく、表現の組み合わせ、回数、会話スピード、会話比率など100以上の特徴からスコア付けを行い、最適な予測を行うモデルを生成。これにより、オペレーターや分析者などがあらかじめ単語を設定するなどの手間をかけずに、精度の高い判定ができるようになっている。今回、SAPジャパンの「SAP Predictive Analytics」を活用し、これまで数カ月かかっていた機械学習モデルの作成期間を数時間に短縮したという。また、平均2秒に1回発生するコールセンターの発話データに対処するため、データを高速で処理するプラットフォームとして、SAPジャパンの「SAP HANA」を採用している。リアルタイムで音声認識テキストを取得する仕組みは、アドバンスト・メディアの「AmiVoice Communication Suite2」と連携しており、精度の高い音声認識テキストの生成もできる。
2015年08月07日
ニフティは8月5日、定期処理の自動実行を指示するサービス「ニフティクラウド タイマー」を提供開始したと発表した。同サービスは、あらかじめ指定した時間に、処理の自動実行を指示するサービス。料金は月2,000円(税抜)から。HTTPリクエストを用いて、任意の処理の自動実行を指示し、数分おきに監視処理を実行したり、毎日決まった時間にログをバックアップするなどのバッチ処理に活用できる。また、ニフティクラウドのサーバーと連携していて、サーバーの起動、停止、再起動、削除、スペック変更、および「カスタマイズイメージ」と「ワンデイスナップショット」の自動実行が可能。指定した時間帯だけサーバーを稼働させたり、定期的にイメージを取得してサーバーをバックアップするといった用途に利用することができる。さらに、IoT/M2Mに最適化された軽量な通信プロトコル「MQTT」に対応し、2015年5月からβ版を提供している「ニフティクラウドMQTT」と組み合わせて利用すれば、IoT化されたデバイスへの定期的なメッセージ発行も可能となる。これまで、サーバー構築などの一連の手順を自動化できる機能「ニフティクラウド Automation」や各種APIの提供を通して、システム担当者の負担軽減と利便性向上に取り組んでおり、今後は、ニフティクラウド タイマーの提供により、システム運用のさらなる自動化を実現するとともに、企業のIoT活用を促進していく。
2015年08月06日
LINEは30日、同社の子会社であるLINE Payが運営するモバイル送金・決済サービス「LINE Pay」において、一部の決済代行企業における請求処理に不具合が発生していたことが判明したと発表した。決済取引において正しくは「JPY(円)」のところ「USD(アメリカドル)」で請求されていたという。今回の不具合では、2015年7月15日から2015年7月22日の間、一部の決済代行企業を経由する決済取引において、正しくは「JPY(円)」であるものを「USD(アメリカドル)」で請求していた。同期間中にKEB Hana Cardの決済システムを経由し、「LINE Pay」で決済を利用した372名(460件)が該当するとしている。LINEとLINE Payではすでに、該当するユーザーの特定を完了し、30日16時半頃にメールでの一時連絡を実施。該当する可能性があるユーザーにメールの確認を呼びかけている。また、登録した電話番号への連絡もあわせて行い、今後の対応説明を順次していく。「LINE Pay」は、2014年12月より提供開始した「LINE」アプリ上で利用できるモバイル送金・決済サービス。提携する店舗やWebサービス・アプリ内における支払いを「LINE」アプリ上で行うことができる。そのほか、「LINE」アプリでつながっている友人に送金できる機能や、送金依頼をする機能、均等に按分された金額をグループのメンバーに請求できる「割り勘」機能などを搭載している。
2015年07月31日
インテルとマイクロン・テクノロジー(マイクロン)は7月28日、従来のNAND型フラッシュメモリーの1000倍の処理速度を持つ新型半導体メモリーを開発したと発表した。新型メモリーには「3D Xpoint」という技術が使われており、NAND型フラッシュメモリーの1000倍の処理速度に加え、DRAMに比べて10倍のデータ容量を実現したという。年内には一部の顧客向けにサンプル出荷を開始する予定。両社は、新型メモリーによって大量のデータへのアクセスおよびその処理が高速化されることで、金融詐欺の早期発見や、医療分野におけるリアルタイムでの疾病追跡などが可能になるとしている。
2015年07月29日
防衛省は22日、DJI製ドローン「ファントムII」がテスト飛行中に風の影響で制御不能になり、東京都・市ヶ谷にある防衛省の敷地外上空で見失ったと発表した。ドローンは、23日に開催する防衛省・自衛隊が保有する小型無人機対処資機材の説明に使われる予定だった。22日13時頃、防衛省グラウンド上で、民間業者が実際にドローンを飛行させ事前予行していたところ、防衛省敷地の北側上空に流されそのまま見失った。使われたドローンはDJI製の「ファントムII」で、本体サイズはW30×D30×H8cm程度。防衛省では職員約20名で付近を捜索していたが、東京都・新宿区西五軒町で該当ドローンを発見した一般人が、110番通報。実際にドローンを操作していた民間業者が、防衛省敷地内から飛び出したドローンと同一であることを確認し、22日18時頃に返却された。人的・物的被害はないという。
2015年07月23日
日本電気(NEC)は21日、従来比で約1/2のデータ処理量を実現した認証暗号技術「OTR」を発表した。データ処理性能に制約がある機器をIoTでつなげる際、データ送受信時の処理量を約1/2に低減しながら、セキュリティの高い認証暗号を行えるとする。通常、「暗号化」と「認証」のデータ処理は別々に行う必要があり、「認証」には「暗号化」と同程度のデータ処理量が必要となる。このため、認証暗号のデータ処理量は「暗号化」のみの場合と比べほぼ2倍で、対応機器の処理性能も2倍必要となり、認証暗号の利用が困難となっていた。OTRは、固定長のデータで暗号化を行う既存の暗号化方式「ブロック暗号」を用い、暗号化と認証を効率良く行なう独自の認証暗号技術。ブロック暗号の適用法を工夫して暗号化と認証用タグ生成の処理を共通化し、データ量を従来から約2分の1程度に低減した。また、並列処理によるデータ処理の高速化も可能で、受信時の復号処理ではブロック暗号の「暗号化関数」を用い「復号関数」が不要となるため、小型センサや機器への実装性を向上させている。同社は今回発表したOTRと、米国政府の標準暗号化方式としても採用されている暗号方式AESを組み合わせた「AES-OTR」で、次世代認証暗号が決定される技術審査会「コンペティションCAESAR」の第1次選考を通過したことも、合わせて発表した。
2015年07月21日
ドイツのフランクフルトで開催中のISC 2015において、ビッグデータ処理の性能を測定するGraph500ベンチマークで、理化学研究所 計算科学研究機構(理研AICS)の京コンピュータが1位となったことが発表された。これは、科学技術振興機構(JST)の戦略的創造研究推進事業CRESTの九州大学(九大)の藤澤克樹教授の率いるグループの成果である。このグループには、九大の他に、東京工業大学(東工大)、京コンピュータを運用している理研AICS、京コンピュータを開発した富士通などが含まれている。京コンピュータは、2014年6月のGraph500で1位となったが、2014年11月のGraph500では米国ローレンスリバモア研究所のSequoiaに抜かれて2位に後退していた。それを今回、アルゴリズムの改良で処理データ量を減らして約2倍という性能向上を達成し、1位に返り咲いたものである。Graph500では、例えば、1億2000万人の日本人が、1日平均16回通話したとする。そして、誰から誰に通話したかという1億2000万×16=19億2000万件の通話記録を入力データとして受け取る。そして、1人の人から、通話のあった人をすべて見つけ、次に、それらの人と通話のあった人をすべて見つけ、さらに、それらの人と通話のあった人全員を見つけるということを繰り返して、通話記録に含まれるすべての人を出来るだけ短い繰り返し回数で見つけるというビッグデータの問題を解く。また、Twitterの個々のフォローの集合を入力として、1人の元となる発言者から、第1次のフォロワー、第2次のフォロワーというようにたどって行って、何ステップで何人にたどり着けるかという解析も同様の処理である。このような解析から通話やフォローの多い人のグループを見つけ出すというように、関係性の高いものを見つけ出すことができる。しかし、入力データが膨大なので、京コンピュータの場合は82,944台の計算ノードに分散してデータを配置する。このため、計算ノード間で多くの通信が必要となり、高い処理性能を実現するのが難しい問題である。このデータは、人間と人間を通話という関係でつないだ形になっており、グラフの世界では、人間をノード、1回の通話をエッジとして表す。今回、京コンピュータが解いた問題は、2の40乗ノード(約1.1兆ノード、前の1億2000万人の通話の例のおおよそ1万倍のデータ)、17.6兆エッジのグラフを調べるものであり、38621.4GTEPS(Giga Traversed Edge Per Second)、毎秒38兆6214億エッジの接続を調べるという処理速度を達成して1位となった。なお、2014年11月には、Sequoiaが23751GTEPSで1位、京コンピュータは19585.2GTEPSで2位となっていたが、今回は、京コンピュータが38621.4GTEPSと性能を伸ばしたのに対してSequoiaは前回のスコアに留まっており、京コンピュータが再びトップに立った。
2015年07月14日




















