
富士通研、大規模データから機械学習で短時間に予測モデルを生成する技術
従来、精度の高い予測モデルを生成するためには学習アルゴリズムや動作条件など全ての組合せを調べる必要があり、例えば5,000万件規模のデータによる学習では、1週間以上の時間を要していたという。
新技術では、少量のサンプル・データと過去の予測モデルの精度から機械学習結果を推定し、最も精度の高い結果の得られる学習アルゴリズムや動作条件の組合せを抽出し、大規模データの学習に適用するという。これにより、5,000万件規模のデータであっても数時間で精度の高い予測モデルを得られるとしている。
これらの技術は、OSSの並列実行基盤ソフトウェアであるApache Spark上で試作したという。
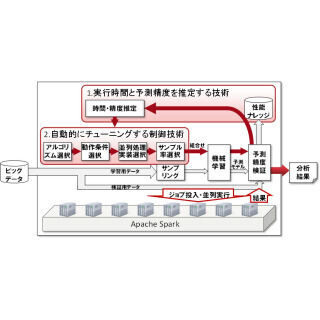
機械学習結果の実行時間と予測精度を推定する技術では、代表的な機械学習のアルゴリズムに関して、データ件数やデータの特徴を表す属性の数を変えながら実際の機械学習の実行時間を計測し、これらの実測値を基に実行時間の傾向を表す実行時間モデルを構築。実行時間の実績に基づいた実行時間推定の補正も実施して推定精度を向上させている。
過去に実施したアルゴリズムや動作条件の組合せと、得られた予測モデルの精度をデータベースである性能ナレッジに記録しておき、新しい組合せの予測精度を推定。これにより、少量のサンプルデータでも予測精度を損なわない必要最小限のデータ量を見極めることができるという。
あらゆる組合せの候補の中から時間効率の高い学習を選び出し、効率的かつ並列に学習を繰り返す、機械学習アルゴリズムを自動的にチューニングする制御技術では、従来、分析者のノウハウに頼った手探りで分析が進められてきたものを、実行時間と予測精度の推定結果を総合判断し、短時間に実行が終わるアルゴリズムと動作条件の組合せを複数抽出して、並列に実行。これにより、実行時間を考慮に入れた最適な順番でアルゴリズムを実行することができ、短時間で高精度な機械学習を選択することが可能になるという。
同社では、社内実験で5,000万件規模のデータを12CPUコアのサーバ8台で処理したところ、従来、1週間程度かかっていた精度96%の予測モデルを、本技術では2時間強で得られることを確認したという。同技術を用いた予測モデルにより、大規模ECサイト会員の退会抑制や設備の故障対応の迅速化といった改善を、タイムリーに実現できるとのことだ。

提供元の記事
提供:




