IPA(独立行政法人情報処理推進機構)情報処理技術者試験センターは12月22日、「情報処理の促進に関する法律施行令の一部を改正する政令(平成27年12月22日閣議決定)」に基づき、経済産業省が所管する国家試験「情報処理技術者試験」の受験手数料が改定されたことを発表した。情報処理技術者試験は、情報処理技術者としての知識・技能が一定以上の水準であることを認定している国家試験。情報システムを構築・運用する技術者から、情報システムの利用者まで、ITに関わるすべての人を対象としている。昭和44年から平成27年度までの累計の応募者数は約1840万人、合格者数は約232万人。情報処理技術者試験の受験手数料は、平成9年度秋期試験から「5100円(税込)」とされていたが、経済産業省において、受験者数の動向などを踏まえ、今後も安定的に試験制度を運営する観点から受験手数料の額が見直され、「情報処理の促進に関する法律施行令の一部を改正する政令(平成27年12月22日閣議決定)」により、「5700円(税込)」に改定された。改定された受験手数料の適用時期は、iパス(ITパスポート試験)が平成28年(2016年)4月1日から、iパス以外の試験区分が平成28年度春期試験からとなっている。
2015年12月22日
アールピージー・ラボ(RPGLABO)は11月9日、毎月の従業員への給与支払いデータなどから、マイナンバーの提出と受領を処理できる「マイナンバー収集キット」の提供を開始したと発表した。同キットは、収集のために必要なハードとソフトがすべて一緒になったもので、クラウドシステムなど不要で、初期費用のみで運用できる。大きな特徴としては、既存の業務フローで発生する「当月給与支払いリスト」「当月報酬支払いリスト」「年末調整宛名データ」といった給与関連のデータを、収集キットをインストールしたPCに読み込ませると自動的にQRコードを生成し、マイナンバーを収集する際に、そのデータとマイナンバーを紐付けることができる点が挙げられる。収集担当者は提出された書類をOCRリーダーで読み込むだけで登録できるので、手入力の必要が無い。一方、マイナンバー収集対象者も「通知カード」「マイナンバー付き住民票」などの必要書類をコピーして提出するだけなので、負担が少ないという。価格は160万円(税別)。キットに含まれるものは、マイナンバー収集システムインストール済パソコン(Windows7 Professionalを搭載)、収集アプリ設定済み iPad(iPad mini2 SIMフリー版)、数字(マイナンバー形式)/QRコードの読み取りに対応したOCRリーダー。また、オプションとして、パソコンの設置が難しい営業所など、遠隔地でのデータ収集のために、iPadとOCRリーダーをセットにした追加オプション(価格は25万円)を用意している。
2015年11月10日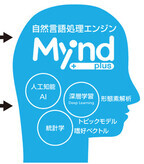
ブレインパッドは10月22日、自然言語処理エンジンの「Mynd plus(マインドプラス)」の提供を開始した。同サービスは、ブレインパッドが提供する「Semantic Finder (セマンティックファインダー)」と、グループ子会社となるMyndが提供する「Mynd Engine (マインドエンジン)」を統合した新サービスで、テキストなどのデジタルデータを独自のアルゴリズムで解釈・処理し、従来人の手で行ってきた業務を「より早く」「より精緻に」処理するほか、人の手では行えない「より高度な」データの処理も実現する。これにより、デジタル・マーケティング領域での活用だけでなく、さまざまなビジネスシーンでの活用が期待できるという。同社は活用例として、Webメディアなどの記事コンテンツに対して「自動タグ付与」や「自動分類」、Webサイト上の類似コンテンツ・類似ユーザーを軸とした「レコメンドコンテンツの抽出」、Webメディアの大量記事や論文などの「自動要約」、コールセンターや相談業務上発生する会話データの「テキストマイニング」、アンケートや口コミのデータなどの「テキストマイニング」などを想定する。
2015年10月23日
腕や脇、脚などのムダ毛処理はきちんとしておきたいですよね。女子力アップのためにムダ毛処理を徹底して行っている人も、意外と見落としているところがあるかも?手や脚などはツルツルでムダ毛の心配はないのに、顔に産毛が…という悲惨な状態になっていませんか? 意外と見ている男性は多く、「他にムダ毛がないからこそ、余計に気になる」と思っているようです。そこで顔の産毛を簡単に処理する方法をご紹介していきます。■産毛のお手入れ方法は?顔の産毛のお手入れ方法はいくつもあるので、自分に合った方法を取り入れましょう。電動シェーバーを使うエステに通うフェイス用の脱毛器を使用する市販のカミソリで剃るもっともキレイに仕上げるには、やはりエステに通うのが1番ですが、お金や時間がネックになりますので、手軽に使える市販のカミソリでの処理方法を解説していきます。 ■フェイス用カミソリでお手軽処理!フェイス用カミソリは、T字タイプ、I字タイプの2つを用意しておくと便利です。また、処理前にはきちんとメイクや汚れを落とすことが大切! 汚れた状態で処理すると、毛穴に雑菌が入りやすくなり、肌トラブルの原因になりかねませんので、しっかりと汚れを洗い落としましょう。顔の汚れを落としたら、蒸しタオルを使って、顔全体を温めます。これは毛穴を開いて肌を柔らかくして処理しやすくするためです。次に美容クリームを顔に塗り、カミソリが滑らかに動くようにします。これは肌への負担を抑える働きもあるので、たっぷりと塗るのがベスト。次に産毛の流れに沿って、ゆっくりとカミソリを滑らせていきましょう。逆から剃ると産毛が目立ってしまうので必ず毛の流れに沿って剃るようにしてくださいね。キレイに剃れたらきちんと洗顔をして、あとはしっかりと保湿して終了です。■産毛をケアするとどんなメリットがある?顔の産毛を処理すると、化粧のノリがよくなり、ファンデーションのもちも良くなります。また、肌が1トーン明るくなる美肌効果も。周りから見ても産毛が生えている顔よりも、きちんと処理されていた方が、清潔感があるでしょう。たくさんのメリットを実感できるので、顔の産毛ケアはしっかりとしておきたいですよね。慣れれば簡単にできるケア方法なので、ぜひ実践してみてください。
2015年10月05日
○GPUは超低速プロセサ図3-28に示したように、GPUは、演算命令を処理するには10~20サイクルを必要とし、ロードストア命令を処理するには400~800サイクル掛かる。仮に、実行する命令の70%が演算命令、30%がロードストア命令とすると、中央値を取って、1命令あたりの平均的な処理サイクル数は15×0.7+600×0.3=190.5サイクルと計算される。そして、クロックが1GHzとすると、1命令を実行するのに190.5ns掛かることになる。一方、IntelのCoreプロセサなどでは、1命令を処理するのに必要なサイクル数は1~2サイクル程度であり、クロックを2.5GHzと想定すると、1命令を実行する時間は0.6ns程度ということになる。つまり、命令の実行時間の比は190.5対0.6で、GPUはCPUと比べると317.5倍遅い超低速プロセサである。そんな物好きな人はいないと思うが、殆ど並列性の無いgccコンパイラをGPUに移植したとすると、この程度の性能比になると思われる。しかし、速度の測り方は色々とある。スポーツカーとバスのどちらが速いかと聞かれれば、普通はスポーツカーと答えるのであるが、50人を目的地まで運ぶ場合はどちらが速いかと言われれば、スポーツカーで50往復するよりも、バスで50人を1回で運ぶ方が速いに決まっている。CPUは、乗客は助手席に1人乗せられるだけであるが、とにかく速く走れるように設計されたスポーツカーであるのに対して、GPUは定員一杯の乗客を乗せた場合に最大の効果を発揮するバスである。そして、バスのメリットをフルに発揮するには、運行する全区間で、満員の乗客を乗せて走る必要があり、これに近い状態で運行することが重要である。そして、乗客として、バラバラのところに行く人を集めてもだめで、まとまって同じ目的地(米国のスクールバスの場合は学校)に行く人を集めなければならない。これをGPUの用語で言うと、並列に実行できる最大スレッド数に近い数の、ほぼ同じ処理を行うスレッドを集めて並列処理を行うことがGPUの効率を発揮するためには欠かせないということになる。
2015年09月25日
今回はファイル処理をメインに取り扱います。実際の業務で使うアプリケーションやサービスは、なんらかの形でファイルを利用する場合が多いです。たとえばCSV(カンマ区切りの表)を読み込んだり、書き出したり……。また、アプリケーションの状態(設定など)やログを残すためにファイルを利用することもあります。ファイルにはバイナリ(01)で構成される画像ファイルや、テキストで構成されるテキストファイルがあります。バイナリのファイルがどのようなものかについても軽く触れますが、初心者はあまり操作しないと思うので、テキストファイルが話の中心となります。そのため、テキストファイルを扱うために必要なテキスト処理についても扱います。なお、日本語テキストの処理などについては別途扱います。○テキストを生成する方法テキスト処理は要するに、文字列型の処理です。第5回で簡単に扱ったのですが、テキストファイルの処理では文字列型の処理が必須となるので少し発展させて復習します。まず、文字列は以下のように定義するのでした。text1 = ’hello python’text2 = ’’’helloworldpython’’’ひとつめに関しては今さらいうこともないですが、2つめに関しては複数行でテキストをプログラム中で定義する方法でしたね。記号「’」の代わりに記号「"」を使うことも可能ですが、文字列の前後で統一されている必要があります。文字列の結合に関しては「+」記号でできますが、数字などを結合するときは「文字列に変換」してから結合するのでした。ほかの型から文字列型への変換にはstr関数を使います。print(’hello ’ + ’world’)# hello worldprint(’hello ’ + str(5)) # hello 5結合の代わりに、文字列にテキストや数字を埋め込むという手法で文字列を生成することも可能です。>>> ’hello {} {}’.format(’python’, 5)’hello python 5’文字列のformat関数(メソッド)の引数に {} に対応する文字列なり数値なりを与えています。このformat関数の使い方を詳細に伝えるとそれだけで連載2~3回分になってしまいますので、詳しくはこちらのドキュメントをご参照ください。結合より埋め込みのほうがコードがきれいになる場合が多いので、積極的に活用してもらいたいです。文字列のフォーマットに関わるところでは、ほかには数値の整形をしたいことがよくあります。たとえば、1,2……というように連番でテキストを表示なり書き込みする場合、なにも配慮しないと次のように桁数が違うとガタガタになってしまいます。1: some text2: some text……9: some text10: some text11: some text……次のように0で揃えられているときれいですね。01: some text02: some text……09: some text10: some text11: some text……このような場合には以下の方法で文字列の数字に「0詰め」をすると便利です。zfillで桁数を指定したり、先のformat関数に出力の細かい指定をしたりしています。print(’5’.zfill(5)) # 00005print(str(101).zfill(5)) # 00101print(’hello {0:05d} world’.format(5)) # hello 00005 world最後に文字列で使われる特殊記号についてお話します。特殊記号はプログラム中で意味を持ってしまう特別な記号のことです。たとえば「’」という記号は文字列を作成する際に利用する特別な記号です。そのほかにはビープ音なども記号に分類されます。これらは文法的な理由やそもそもそれを表現する記号がキーボードのキーにないことから、「これは XX ですよ」という特別なルールにもとづいて文字列に表記します。そのルールに利用されるのがエスケープ記号と呼ばれるもので半角のバックスラッシュ「\」(英語キーボード)か、半角の円記号「\」(日本語キーボード)を利用します。このエスケープ記号の後に特別な文字を続けることで、それが特別な意味を持つのです。たとえば「’」とビープ音は以下の用に記載できます。print(’escape sample1 \’.’)print(’escape sample2 \a.’)ほかには改行とエスケープ記号自身あたりをよく使います。print(’escape sample1 \n.’)print(’escape sample1 \\.’)エスケープ記号一覧はこちらのページの中央付近に記載されています。なお、記事掲載時から時間が経ってリンク切れしている場合は、適当に検索するなどして調べてみてください。○テキストを加工する方法テキストの生成について取り扱ったので、次はそのテキストを加工する方法について扱います。基礎的な機能を順に紹介していきます。これ以外にも多数の機能がありますが、必要になった時点で調べて覚えていけばよいでしょう。まず、文字列中の「文字」の取得ですが、以下のように [X] で位置を指定して行います。>>> text = ’hello world python’>>> print(text[4])o>>> print(text[100])Traceback (most recent call last):File "<stdin>", line 1, in <module>IndexError: string index out of range>>> print(text[-4])tこの位置の指定はリストの要素の数え方と同じで0から始まります。先頭から0、1、2……と数えていくと4はoに対応していますね。範囲を超えてしまうとエラーになります。面白いのがこの値をマイナスにできるところです。このように指定すると後ろ側から取得してきます。この際、0からではなく-1、-2、-3……とカウントすることに注意してください。文字列から「文字列」を取得するには、以下のように行います。>>> text = ’hello world python’>>> print(text[6:11])world>>> print(text[-12:-7])worldこれは「スライシング」と呼ばれるテクニックで、[X:Y]とあるとXからYまで取得という意味になります。[X:Y] と指定する際はX < Yとなるようにしてください。先ほどと同じように、範囲指定にもマイナス値を利用できます。前と後ろを指定するのではなく、Xより前、Xより後という指定の仕方も可能です。>>> print(text[6:])world python>>> print(text[:11])hello world>>> print(text[:])hello world python見ていただくとわかるように [X:Y] の片方を省略しています。そうすると先頭から、もしくは末尾までという意味になります。あまり使いどころはありませんが、両方とも省略すると、文字列のすべてが取得されます。次に文字列の置き換えです。テキストエディタなどである特定のキーワードを別のキーワードに置き換えることがあるかと思いますが、それと同じ要領です。>>> text = ’hello world python’>>> print(text.replace(’o’, ’0’))hell0 w0rld pyth0n>>> print(text.replace(’world’, ’WORLD’))hello WORLD python>>> print(text)hello world python文字列.replace(置き換える文字列, 置き換えられる文字列)とすると、変換された文字列が返されます。例にもあるように、元の文字列自体は変化していないので注意してください。文字列の検索もそれほど難しくはありません。検索には「存在の確認」と「位置の確認」の2つの使い方があり、それぞれ次のようになります。>>> text = ’hello world python’>>> ’wor’ in textTrue>>> ’w0r’ in textFalse>>> text.find(’wor’)6>>> text.find(’w0r’)-1>>> text.find(’o’)4inについてはlistでの使い方とほぼ同じですね。find については最も左側にあるマッチした位置を返します。そのため、’o’は何個もありますが、一番左の位置となっています。マッチしない場合は-1が返ってきます。それほど使う場面は多くないのですが、前側を指定した数だけ飛ばして途中から検索したり、右側から探索をすることも可能です。>>> text.find(’o’, 10)16>>> text = ’hello world python’>>> text.rfind(’o’)16次に文字列の前後からの特定の文字の削除です。よく利用するのは、前後の空白や改行コード、タブなどを取り除く場合などでしょう。>>> text = ’ hello world \n’>>> text.strip()’hello world’>>> text.strip(’ hell’)’o world \n’strip関数に引数を指定しないと、文字列の前後の空白とタブ、改行が取り除かれます。引数に文字列を指定すると、その文字列が取り除かれます。また、特定の区切りで文字列を分割して文字列のリストにすることも可能です。「,」記号で要素が区切られたCSV(Excel出力)やログの解析あたりでよく使うテクニックです。>>> text = ’1, taro, 35, male’>>> text.split(’,’)[’1’, ’ taro’, ’ 35’, ’ male’]text = ’’’1, taro, 35, male2, jiro, 29, male3, hanako, 23, female’’’for line in text.split(’\n’):elems = line.split(’,’)print(’{} {}’.format(elems[1].strip(), elems[2].strip()))# taro 35# jiro 29# hanako 23分割の逆で文字列を「特定の文字列」で結合していくことも可能です。2次元配列(リストにリストが入っている)に格納された情報をCSV形式でファイルに書き出したりする際に便利な手法です。書式は「結合に使う文字列.join(文字列のリスト)」となります。>>> l = [’1’, ’taro’, ’35’, ’male’]>>> ’, ’.join(l)’1, taro, 35, male’○ファイル処理の概念ファイル処理については、プログラミングというよりも「OSのファイル処理の方式」をまず理解しておく必要があります。そのため、最初にファイル処理の概念について説明します。これがわかってしまえば、その利用はさほど難しくありません。なお、プログラムがどのようにファイルを扱うかは、OSの仕組みにもとづいているため、多くのプログラミング言語でさほど変わりません。ファイル処理がOSにおいてどう実現されているかを抽象化すると以下のようになります。実際はもっと複雑ですが、通常のプログラミングではそこまで意識する必要はないので詳細は割愛します。まずご存知のようにOSにはディレクトリがあり、それが階層構造を作っています。ファイルはそのディレクトリのなかに保存されています。OSはこの階層構造を管理しています。ディレクトリやファイルは、サイズなどの情報と共にポインタのようなものを持っていて、それがファイルの実体を指しています。構造についての話はこれぐらいにして、実際にファイルをどのように処理するか話をしましょう。OSにおけるファイル処理は主に以下のような流れとなります。まず絶対パス(ルートやCドライブなどからのパス)や相対パス(現在いるディレクトリから指し示すパス)を使ってファイルを指定します。それに対して読み、書き、読み書きなどのモードを指定してファイルをオープンします。そして読み書きなどの必要な処理を繰り返し、処理がすべて完了したらファイルをクローズして終わりです。クローズし忘れないようにしてくださいね。読み書きなどの具体的な処理はそれほど難しくありません。一言でいってしまえば、「テキストファイルは行ごとに処理する」「バイナリファイルは先頭から何バイトめか(位置)を指定して処理する」ことです。たとえば、テキストファイルで以下のものがあるとします。worldpythonjavaこの内容にすべて"hello "を加えて画面に表示するというプログラムを書く場合、ループ処理を利用してということを繰り返して処理するのが一般的です。「テキストファイルは行ごとに処理する」のが基本であることを覚えておいてください。次にバイナリファイルです。バイナリファイルは中身が01から構成されているファイルで、一般的には画像ファイルや音声ファイル、それに加えてアプリケーション特有のファイル(たとえば word など)があります。こちらはテキストと違うのでそもそも行という概念がありません。正直なことをいうと、テキスト処理よりもバイナリファイルの処理は骨が折れます(笑)。ただ、ファイルを読み書きできないかというと、そんなことはありません。そのバイナリファイルの構造を知ってさえいれば操作は可能です。著者はビットマップ形式の画像ファイルの合成とWAV形式の音声データの加工の経験があるので、それをベースにしてバイナリファイルの処理についてお話をします。ビットマップは以下の図のように、ピクセルから構成されている画像ファイルです。それぞれのピクセルはRGB(赤緑青)で表現されています。それぞれの色は1バイト(0~255)の容量があるので、ようするに1ピクセルは3バイトです。つまりファイルサイズは「縦のピクセル数×横のピクセル数×3」バイトになります。ここまでわかってしまえば、あとは簡単です。たとえば画像Aに画像Bをオーバーレイ(一部上書き)するとします。この際、Bの画像の黒(RGBが0, 0, 0)は透過させます。すると、以下の図のようにして合成が可能です。Bの左上は黒なのでAのものを合成画像に利用。その右隣は黒ではないのでBのものを利用。その右隣はA……といった感じでどんどん処理をしていくと、最終的に右の図のようになります。これをファイルに書き込めば、自分でバイナリファイルを作ったことになります。次にWAV音声ファイルです。これも比較的わかりやすい形式ですが、先ほどのビットファイルと違って「ヘッダ」と「データ」に分かれています。データは先程のビットマップと同じく音声のデータ(波形)を含んでいるだけなので簡単ですが、ヘッダにはデータをどのように表現するかといった情報が含まれています。後ろのデータを変えれば当然再生される音も変わりますが、その際に必要に応じてヘッダを変更する必要があります。最後にバイナリデータの処理のコツを伝えます。それは「プログラムで処理しやすい生(raw)の形式に一旦戻す」ということです。たとえばビットマップであれば編集は簡単ですが、JPEGやPNGを編集するのは非常に難しいです。そのためまずはJPEG → ビットマップに変換してやり、ビットマップで編集を行った後に再度、ビットマップ → JPEGに変換すればよいのです。音声も同じでmp3を直接編集するのではなく、mp3 → wav → 編集 → new wav → mp3とすればよいです。これらの変換には組み込みもしくは外部のライブラリを使用してかまいません。○実際にファイル処理をしてみよう長くなりましたが、実際に pythonでテキストファイルの処理をどのようにするか紹介します。先ほどの概念さえわかってしまえば非常に簡単です。worldpythonjavaと書かれたテキストファイルtext.txtの各行にhelloを加えて表示するサンプルを書いてみます。f = open(’text.txt’, ’r’)print(type(f))for line in f:print(’hello ’ + line)f.close()まずファイル ’txt.txt’ をモード ’r(読み)’ でオープンしています。オープンしたファイルオブジェクトに対してfor文を使うと1行1行取得できるので、行ごとにprintする処理をしています。これを実行すると以下のような出力となります。<type ’file’>hello worldhello pythonhello javaprint文の改行に加えて、もとのテキストの改行も表示されるので1行スペースがあいてしまっていますね。print文の改行をなくすには以下のようにprint文の後に「,」を書けばよいです。print(’hello\n’),print(’world\n’),ほかにはファイルを丸ごと読む方法もあります。f = open(’text.txt’, ’r’)text = f.read()print(text)lines = text.split(’\n’)print(lines)f.close()ファイルオブジェクトに対してread関数を使うことで、その中身をすべて文字列として取得します。それを行ごとに処理したいのであれば、文字列を先に説明した改行コードで分割することで行ごとのリストになるので、それに対して処理を行うことができます。次に書き込み方法について説明します。書き込みも読み込みと大差ありませんが、ファイルをオープンする際に書き込みモードを指定します。以下のテキストファイルtext.txtに書き込みをするとします。hello書き込みのコードは以下となります。f = open(’text.txt’, ’w’)f.write(’123’)f.write(’456’)f.close()コードを見てもらうと想像がつくとは思いますが、openの第二引数が書き込みモードの ’w’ となっています。そしてファイルオブジェクトにたいしてwriteすることで、実際にファイルに書き込み処理がされています。最後にクローズですね。するとファイル text.txt は以下のようになりました。123456見てもらうとわかるように、もともとのテキストであるhelloが消えていますね。上書きされていることがわかります。ただ、場合によっては「追記(もとの中身を残したまま後ろに加える)」しないといけないこともあります。その場合はモードを ’a’ の「追記」にすれば実現できます。モードのみ修正して以下のコードにしてみます。f = open(’text.txt’, ’a’)f.write(’123’)f.write(’456’)f.close()これを実行すると、123456123456となりました。もとの ’123456’ は残ったままで、その後ろに ’123456’ が新しく追加されていますね。ファイルのオープンごとに以前の内容が消えないので、アプリケーションのログなどを取る際に便利な手法です。なお、書き込みを「次の行」にする場合は「\n」を書き込めばいいです。最後に小ネタを話して終わりたいと思います。ファイル処理をする際に心の片隅においていただきたいのが「バッファリング」という処理です。ご存知かもしれませんが、ハードディスクへのアクセス速度はメモリへのアクセス速度に比べて何桁も遅いです。そのため、ファイルを何度も細かく書くことを繰り返しているとプログラムが非常に低速になってしまいます。この問題を防ぐために、出力があるたびに毎回ディスクに書き込むのではなく、メモリ上の高速な一時領域にデータをおいておき、まとめてそれを書き込むという処理が行われます。こうすることで低速なディスクアクセスの回数が減らせるのでプログラムが高速化されます。これがバッファリングの基本的な概念です。以下にこれを図で示します。このディスクへの書き込みは特定のタイミングで発生するようですが、それを強制的に行いたい場合はflush()関数を使います。f = open(’text.txt’, ’w’)f.write(’123’)f.flush()f.write(’456’)f.close()closeのタイミングで必ず書き込まれるので、今回のようにopenからcloseまで時間が短い場合はflushは不要です。ただ、openしっぱなしで、なかなかcloseしないようなプログラムは適切なタイミングでflush するように心がけてください。でないと、プログラムが強制終了されてしまった場合などに、ファイルに書き込みがされていない可能性があります。以上でファイルに関する基本的な話は終了です。ある特定ディレクトリ配下のすべてのファイルを調べるのに便利なglobや、リソース管理のwith文などもあるのですが今回は割愛します。便利なのである程度レベルがあがったら、ぜひ自分で調べてみてください。○「Pickle」とは最後に「Pickle」についてご紹介します。PickleはPythonのデータをファイルに保存し、それを読み取って復元する目的で使えます。あるアプリケーションで終了時に保持するデータをPicklで保存し、再度開いた際にPickelで読み取れば、前回終了した際の状態に戻すといった使い方ができます。Pickle の使い方はそれほど難しくないので、以下にサンプルを載せます。import picklea = {’hello’:1, ’world’:[1,2,3]}f1 = open(’test.dump’, ’wb’) # WRITEpickle.dump(a, f1)f1.close()f2 = open(’test.dump’, ’rb’)b = pickle.load(f2) # READf2.close()print(b) ## {’world’: [1, 2, 3], ’hello’: 1}まずPickleパッケージをインポートしています。そして書き出すファイルを書き込みモードでオープンし、pickle.dump関数でデータをファイルに書き込んでいます。Pickleで書き込まれるデータはバイナリなので’w’ではなく’wb’でバイナリとしてオープンしています。’w’でもおそらく問題はないと思います。次に Pickleのデータが書き込まれたファイルから中身をロードしてきています。これには pickle.load 関数を使っています。’wb’と同様に、こちらもバイナリの読み込みなので’rb’でファイルをオープンしています。簡単ですね。演習1以下のCSV形式のテキストデータから教科ごとの生徒の平均点を算出してください。text = ’’’lecture\students, 1, 2, 3, 4math, 80, 70, 75, 54english, 60, 80, 90, 80’’’可能なら生徒や教科が増えても対応可能なプログラムにしてください。演習2あるテキストファイルAの内容を読み取り、まったく同じ内容をファイルBに書き出すプログラムを書いてください。演習3演習2で作ったプログラムを改良し、ファイルBに行番号を書き出すようにしてください。ただし、行番号は最後の行の桁数にあるように0詰めしてください。たとえば以下のようになります。abc……ijk……z01 a02 b03 c……09 i10 j11 k……26 z演習4標準入力で入力されたテキストをpickleでファイルに保存してください。そしてそれをロードして、画面に表示してください。さまざまなデータをPickleで保存して、そのファイルを開いて中身を確認してみてください。※解答はこちらをご覧ください。次回は正規表現と日本語の扱いについて解説します。
2015年08月10日
ニフティは8月5日、定期処理の自動実行を指示するサービス「ニフティクラウド タイマー」を提供開始したと発表した。同サービスは、あらかじめ指定した時間に、処理の自動実行を指示するサービス。料金は月2,000円(税抜)から。HTTPリクエストを用いて、任意の処理の自動実行を指示し、数分おきに監視処理を実行したり、毎日決まった時間にログをバックアップするなどのバッチ処理に活用できる。また、ニフティクラウドのサーバーと連携していて、サーバーの起動、停止、再起動、削除、スペック変更、および「カスタマイズイメージ」と「ワンデイスナップショット」の自動実行が可能。指定した時間帯だけサーバーを稼働させたり、定期的にイメージを取得してサーバーをバックアップするといった用途に利用することができる。さらに、IoT/M2Mに最適化された軽量な通信プロトコル「MQTT」に対応し、2015年5月からβ版を提供している「ニフティクラウドMQTT」と組み合わせて利用すれば、IoT化されたデバイスへの定期的なメッセージ発行も可能となる。これまで、サーバー構築などの一連の手順を自動化できる機能「ニフティクラウド Automation」や各種APIの提供を通して、システム担当者の負担軽減と利便性向上に取り組んでおり、今後は、ニフティクラウド タイマーの提供により、システム運用のさらなる自動化を実現するとともに、企業のIoT活用を促進していく。
2015年08月06日
LINEは30日、同社の子会社であるLINE Payが運営するモバイル送金・決済サービス「LINE Pay」において、一部の決済代行企業における請求処理に不具合が発生していたことが判明したと発表した。決済取引において正しくは「JPY(円)」のところ「USD(アメリカドル)」で請求されていたという。今回の不具合では、2015年7月15日から2015年7月22日の間、一部の決済代行企業を経由する決済取引において、正しくは「JPY(円)」であるものを「USD(アメリカドル)」で請求していた。同期間中にKEB Hana Cardの決済システムを経由し、「LINE Pay」で決済を利用した372名(460件)が該当するとしている。LINEとLINE Payではすでに、該当するユーザーの特定を完了し、30日16時半頃にメールでの一時連絡を実施。該当する可能性があるユーザーにメールの確認を呼びかけている。また、登録した電話番号への連絡もあわせて行い、今後の対応説明を順次していく。「LINE Pay」は、2014年12月より提供開始した「LINE」アプリ上で利用できるモバイル送金・決済サービス。提携する店舗やWebサービス・アプリ内における支払いを「LINE」アプリ上で行うことができる。そのほか、「LINE」アプリでつながっている友人に送金できる機能や、送金依頼をする機能、均等に按分された金額をグループのメンバーに請求できる「割り勘」機能などを搭載している。
2015年07月31日
インテルとマイクロン・テクノロジー(マイクロン)は7月28日、従来のNAND型フラッシュメモリーの1000倍の処理速度を持つ新型半導体メモリーを開発したと発表した。新型メモリーには「3D Xpoint」という技術が使われており、NAND型フラッシュメモリーの1000倍の処理速度に加え、DRAMに比べて10倍のデータ容量を実現したという。年内には一部の顧客向けにサンプル出荷を開始する予定。両社は、新型メモリーによって大量のデータへのアクセスおよびその処理が高速化されることで、金融詐欺の早期発見や、医療分野におけるリアルタイムでの疾病追跡などが可能になるとしている。
2015年07月29日
日本電気(NEC)は21日、従来比で約1/2のデータ処理量を実現した認証暗号技術「OTR」を発表した。データ処理性能に制約がある機器をIoTでつなげる際、データ送受信時の処理量を約1/2に低減しながら、セキュリティの高い認証暗号を行えるとする。通常、「暗号化」と「認証」のデータ処理は別々に行う必要があり、「認証」には「暗号化」と同程度のデータ処理量が必要となる。このため、認証暗号のデータ処理量は「暗号化」のみの場合と比べほぼ2倍で、対応機器の処理性能も2倍必要となり、認証暗号の利用が困難となっていた。OTRは、固定長のデータで暗号化を行う既存の暗号化方式「ブロック暗号」を用い、暗号化と認証を効率良く行なう独自の認証暗号技術。ブロック暗号の適用法を工夫して暗号化と認証用タグ生成の処理を共通化し、データ量を従来から約2分の1程度に低減した。また、並列処理によるデータ処理の高速化も可能で、受信時の復号処理ではブロック暗号の「暗号化関数」を用い「復号関数」が不要となるため、小型センサや機器への実装性を向上させている。同社は今回発表したOTRと、米国政府の標準暗号化方式としても採用されている暗号方式AESを組み合わせた「AES-OTR」で、次世代認証暗号が決定される技術審査会「コンペティションCAESAR」の第1次選考を通過したことも、合わせて発表した。
2015年07月21日
ドイツのフランクフルトで開催中のISC 2015において、ビッグデータ処理の性能を測定するGraph500ベンチマークで、理化学研究所 計算科学研究機構(理研AICS)の京コンピュータが1位となったことが発表された。これは、科学技術振興機構(JST)の戦略的創造研究推進事業CRESTの九州大学(九大)の藤澤克樹教授の率いるグループの成果である。このグループには、九大の他に、東京工業大学(東工大)、京コンピュータを運用している理研AICS、京コンピュータを開発した富士通などが含まれている。京コンピュータは、2014年6月のGraph500で1位となったが、2014年11月のGraph500では米国ローレンスリバモア研究所のSequoiaに抜かれて2位に後退していた。それを今回、アルゴリズムの改良で処理データ量を減らして約2倍という性能向上を達成し、1位に返り咲いたものである。Graph500では、例えば、1億2000万人の日本人が、1日平均16回通話したとする。そして、誰から誰に通話したかという1億2000万×16=19億2000万件の通話記録を入力データとして受け取る。そして、1人の人から、通話のあった人をすべて見つけ、次に、それらの人と通話のあった人をすべて見つけ、さらに、それらの人と通話のあった人全員を見つけるということを繰り返して、通話記録に含まれるすべての人を出来るだけ短い繰り返し回数で見つけるというビッグデータの問題を解く。また、Twitterの個々のフォローの集合を入力として、1人の元となる発言者から、第1次のフォロワー、第2次のフォロワーというようにたどって行って、何ステップで何人にたどり着けるかという解析も同様の処理である。このような解析から通話やフォローの多い人のグループを見つけ出すというように、関係性の高いものを見つけ出すことができる。しかし、入力データが膨大なので、京コンピュータの場合は82,944台の計算ノードに分散してデータを配置する。このため、計算ノード間で多くの通信が必要となり、高い処理性能を実現するのが難しい問題である。このデータは、人間と人間を通話という関係でつないだ形になっており、グラフの世界では、人間をノード、1回の通話をエッジとして表す。今回、京コンピュータが解いた問題は、2の40乗ノード(約1.1兆ノード、前の1億2000万人の通話の例のおおよそ1万倍のデータ)、17.6兆エッジのグラフを調べるものであり、38621.4GTEPS(Giga Traversed Edge Per Second)、毎秒38兆6214億エッジの接続を調べるという処理速度を達成して1位となった。なお、2014年11月には、Sequoiaが23751GTEPSで1位、京コンピュータは19585.2GTEPSで2位となっていたが、今回は、京コンピュータが38621.4GTEPSと性能を伸ばしたのに対してSequoiaは前回のスコアに留まっており、京コンピュータが再びトップに立った。
2015年07月14日
情報処理推進機構(IPA)の情報処理技術者試験センターは7月13日、「平成27年度秋期情報処理技術者試験」の受験申込みの受付を同日より開始したと発表した。情報処理技術者試験は、経済産業省所轄の国家試験で、情報処理技術者としての知識・技能が一定以上の水準であることを認定するもの。情報システムを構築・運用する技術者から、情報システムの利用者まで、ITに関わるすべての人を対象としている。試験は、春期・秋期の年2回実施されており、平成27年度秋期試験は2015年10月18日に実施される。申込み受付期間は、インターネット申込みの場合が7月13日10時~8月21日20時で、願書郵送申込みの場合は7月13日~ 8月10日(消印有効)。受験手数料は各区分の試験のいずれも5,100円(税込)となっている。
2015年07月13日
プログラムの基本的な流れは上から下へ一行ずつ実行していくというものです。単純なプログラムですと、テキストファイルに実施する処理を順番に羅列するだけで実現できます。いわゆる「バッチ処理」と呼ばれているやつです。ただ、複雑なプログラムだと、このような「上から下に順番に実行していく」というスタイルだけでは処理を実現できなくなってきます。たとえば、天気予報を確認するアプリケーションでは、「今日が晴れなら晴れマークを表示、雨なら雨マークを表示」といった具合に「あるものがAならBをする。そうでないならCをする」という処理が必要になってきます。「条件」に応じて処理が「分岐」しているので、こういった処理のことを「条件分岐」といいます。ほかには、同じ処理を何度も繰り返す「ループ処理」があります。たとえば、「クラス全員のテストの平均点を求め、その平均点と各生徒の点数の差分をチェックする」といった場合を考えてみましょう。平均を求めるには「生徒の点数の合計/人数」とする必要がありますが、この合計を求めるために「先頭の生徒から最後の生徒まで順番に点数を足していく」という「繰り返し(ループ)」が必要となります。平均との差分の算出も同様です。今回はこのような条件分岐やループ処理といった「プログラムの制御構造」について取り扱います。これらの処理を使うこと自体はそれほど難しくないので、何度も書いて慣れてしまえば、簡単に使いこなせるようになるはずです。なお、今までの記事ではプロンプトベースで説明を進めてきましたが、コードが長くなりはじめたのでプログラムファイルで実行することを前提に解説します。IDLEのエディタで書いてF5(MacはFn + F5)で実行するなり、pythonコマンドで実行するなりしてください。○条件分岐さっそく、最も使われる制御構造のひとつである「条件分岐」について学んでいきましょう。条件分岐は、条件分岐の式を満たすか満たさないかで実行される処理が変わるという制御構造です。型について取り扱った際に紹介した「Bool型」が条件判定に利用され、その値がTrueかFalseかで実行するプログラムが変わります。以下に条件分岐の仕組みを図で記します。上記の図のうち、「elif」は任意の数(0も含む)繰り返すことができ、「else」も省略することができます。elseがないときは、どの条件にも合致しない場合は何もしないということです。Pythonのプログラムでは以下のように書きます。if(条件A):処理1-1 # 条件 A が True の時に実行される処理処理1-2elif(条件B):処理2 # 条件 A が False で条件 B が True の時に実行される処理elif(条件C):処理3 # 条件 A,B が False で条件 C が True の時に実行される処理else:処理4 # 全ての条件が False の時に実行される処理上記のifからelseの次の行までがひとつの「if文のカバー範囲」であり、そのなかにあるifやelif、elseが細かい処理の単位だと思っていただければ大丈夫です。上記のプログラムには「if、else、elifのあとの処理が字下げ(インデント)されている」という規則性が見えますね。このインデントされている場所は「コードブロック」と呼ばれるもので、同じインデントのレベル(深さ)で揃えると同じコードブロックに属しているとみなされます。なんだか難しいようですが、ようするに上記のif文でいうと「処理1-1、1-2はif(条件A)のカバー範囲」であるということです。同様に処理2は「elif(条件B)」の範囲であり、処理3は「elif(条件C)」、処理4は「else」の範囲です。実際に条件分岐を行うプログラムを書くことで、条件分岐の使い方をイメージしてみましょう。プログラムは非常に簡単で、変数xの値が0より大きければ「+」と出力し、ピッタリ0なら「0」と「Zero」、0未満なら「-」と出力するというものです。これは以下のようになります。x = 5if(x > 0):print(’+’)elif(x == 0):print(’0’)print(’Zero’)else:print(’-’)繰り返しになりますが「print(’0’)」と「print(’Zero’)」は同じコードブロックです。上記プログラムをIDLEのエディタに書いて実行してみてください。xに5が代入されているので、「+」と出力されたはずです。これはx < 0の条件式が満たされ(Trueとなり)、「print(’+’)」が実行されたからです。このxに代入する値をいろいろ変えて動かしてみると、どの条件式がチェックされ、「if、elif、else」のどの処理が実行されたのかイメージできるはずです。○コードブロック条件分岐の話が終わったので、インデント(字下げ)についてもう少し詳しくお話しましょう。先ほどのプログラムは最初から最後までif文でしたが、実際には、if文は多くの処理のなかに埋もれるかたちで処理します。すると、ifなどの制御構造が「どこからどこまでをカバーしているか」をどのような形で表現するかが問題になってきます。たとえば、処理1、2、3、4、5とあるなかで条件Aを満たす場合のみ処理2、3を実行し、満たさない場合は4を実行するとした場合、どのように表現すればよいでしょうか。勘のいいかたなら気が付かれたかもしれませんが、インデント(字下げ)をすることでこれを実現しています。処理1if(条件A):# ここから処理2処理3# ここまでがコードブロックelse:# ここから処理4# ここまでがコードブロック処理5字下げをすることでコードブロックを表現する。簡単ですね。なお、CやJavaにもコードブロックはありますが、その書き方は異なっています。たとえばJavaだと上記のサンプルコードは以下のようなものとなります。処理1if(条件A){// ここから処理2 // 字下げは必須ではない処理3// ここまでがコードブロック}else{// ここから処理4// ここまでがコードブロック}処理5{}で囲むことでコードブロックを表しています。たいていは読みやすいように上記のようにインデントをしますが、プログラムとしてはインデントをする必要性はありません。コードブロックはifやループなどの制御構造だけではなく、関数やクラスでも利用されます。なお、Pythonのインデントの仕方は「半角空白を2つまたは4つ」が普通だと思います。自分や属するプロジェクトのコーディング規約次第があればそれに従ってください。○コードブロックのネスト(入れ子)コードブロックの中にコードブロックを作ることも可能です。たとえば条件分岐の中に、さらに条件分岐を作ったりすることもできます。書き方は簡単で、コードブロックの内側にさらにコードブロックを作るというものです。その際、内側のコードブロックは外側のコードブロックに属しています。サンプルコードをあげてみます。if(条件A):処理1 # "if(条件1)"のコードブロックに属するif(条件B):処理2 # "if(条件1)" と "if(条件2)" の両方法のコードブロックに属する処理3else:処理4処理1、2、3はすべて「if(条件1)」のコードブロックに属していますが、処理2だけではそれに加えて 「if(条件B):」にも属しています。そのため、処理2が実行されるのは条件A、Bが共にTrueのときのみです。たとえ条件BがTrueであっても、条件AがFalseなら処理2は実行されません。なお、コードブロックに限らず、プログラミングで「入れ子」構造にすることを一般的に「ネストする」と言いますので覚えておいてください。ネストすること自体には問題はありませんが、その深さが増えてくるとプログラムが非常に読みにくくなります。深いレベルのネストが必要な状況になってきたら、アルゴリズムそのものを見直すか、後の連載で扱う「関数」に処理を分割することで読みやすくすることが多いです。○ループ処理次に、別の制御構造であるループ処理について扱います。ループ処理はその名前からわかるように「同じ処理を何度も繰り返す」という処理です。ループ処理の制御構造にはforとwhileの2つがあり、両者の使うべきポイントは若干異なっています。そのため、それぞれ別に説明します。for「for」は「グループにある要素すべてを処理する」といったときに使われるループ構造です。一番よく使われるのが、前回お話したリスト(配列)に格納されている要素すべてをチェックするような処理です。JavaやCで使われるfor文と書き方はかなり異なるものの、ほとんど同じような場面で使います。Pythonのfor文のイメージを以下の図に書きます。難しい用語でいうと「イテレーター」と呼ばれる処理方式なのですが、ようするに「たくさんある集合の先頭ひとつを取り出して、それを処理する。それが終わったら、次を取り出して処理をする」ということを、集合が空になるまで繰り返すというイメージです。それほど難しくないので例で示しましょう。1、2、3、4、5という数字が格納されているリストの中身を一つひとつすべてprint出力する処理をforで書くと以下のようになります。a = [1,2,3,4,5]for i in a:print(i)1、2、3、4、5という集合から、リスト a から 1 を取り出して i に格納。それをprint出力リスト a から 2 を取り出して i に格納。それをprint出力…(中略)…リスト a から 5 を取り出して i に格納。それをprint出力リスト a からすべてを取り出したのでforのコードブロックを終了という動きをします。すでに想像はついているかと思いますが、出力は以下のようになります。12345イテレーターを使っているので、Javaのfor文で使うような「インデックス(配列の何番目か)による制御」に比べて、間違った要素を指定するリスクが減っています。whilewhileもforと同じくループ処理のための制御構造です。ただ、whileは「ループを何周すればいいかわからない処理」に利用されます。先ほどのforの例を思い出して下さい。forでのループ回数は「リストaに格納されている要素の数」と明確にわかりますよね。このような場合はforで処理すべきです。一方、たとえば「123456789という数字を2進数で表現するのに必要な桁数を求める処理」が必要だとした場合、これをどうfor文で処理すればいいか、想像できますか。私はシンプルでスマートな実装は思いつかないです。解き方はいろいろあると思いますが、一番簡単な解法の一つとして、以下のようなものが考えられます。2 の 1 乗は 123456789 より大きいか-< No2 の 2 乗は 123456789 より大きいか-< No..2 の N 乗は 123456789 より大きいか-< No2 の N+1 乗は 123456789 より大きいか-< YESN+1桁あれば 123456789 を表現可能だとわかるこの処理では2を1乗、2乗とループ処理でどんどん大きくしていきますが、最終的に2の何乗になるかがわかりませんよね。このようなときに「特定の条件をクリアするまでループを回す」ためにwhileを使うと便利です。以下にwhile文の使い方のイメージ図をのせます。上記の図を見てもらうとわかるように、while文はループを回るごとに条件式をチェックして、それがTrueならループを継続して、Falseならループを抜けるという処理をします。これはJavaやCのwhileとまったく同じです。先ほどの2進数の桁数を求めるプログラムをwhileで書いてみます。a = 123456789i = 1while(2**i < a):i+=1print(i)すでに扱った内容ですが、上記のプログラムを補足すると、2**iは「2のi乗」を計算していて、i+=1はiをインクリメント(i = i + 1)しています。2**iが123456789より小さい間はiをインクリメントしていき、2**iが123456789より大きくなったらループを抜けるという動きをします。ループを抜けた際iに入っている値が必要な桁数を表しています。○break と continue制御そのものの打ち切りや「ループのその回だけ」の打ち切りが必要な場面があります。たとえば以下のようなプログラムがあるとします。a = [1,3,5,7,9,10,11,13,15]has_even = Falsefor i in a:if(i%2 == 0):has_even = Trueprint("List has even: " + str(has_even))偶数がリストの中にあるかどうかをチェックしていますね。リストの中に10があるので、当然Trueとなります。ただ、よく考えてみてください。なにか無駄な処理があると思いませんか。そう、ループが10になった回で偶数があることがわかったのに、さらにチェックを繰り返しています。10が現れた時点で偶数があることはわかりきっているので、ループを回し続けるのは無駄なのです。「break」を使って処理を打ち切ることで、この問題を解決できます。a = [1,3,5,7,9,10,11,13,15]has_even = Falsefor i in a:print(i) # NEW CODEif(i%2 == 0):has_even = Truebreak # NEW CODEprint("List has even: " + str(has_even))確認のためにbreakだけでなく、print文も追加しています。これを実行すると以下のようになります。1357910List has even: Trueどうです、11以降のチェックをしなくなりましたよね。このようにbreakはかなり使える処理なので覚えておく必要があります。一方「continue」ですが、正直こちらはbreakほど頻繁に利用されない気がします。ただ、ループで「特定の条件の場合だけ処理をしたい」というときに利用されることが多いです。たとえば、数値1から99のリストのうち、3でも5でも割り切れるものだけを画面出力する必要があるとします。リストを使わないで愚直な書き方をすると以下のようになります(実際はcontinueを使わなくとも、もっとスマートに書けます)。a = []for i in range(1,100):if(i%3 == 0):if(i%5 == 0):print(i)range関数は第一引数(1)から第二引数(100)のひとつ前までの数値のリストを作成する関数です。もし、iが3で割り切れたら、もしiが5で割り切れたら……などというように条件分岐がどんどん深くなってしまいます。これをcontinueを使って書き直すと、次のようになります。a = []for i in range(1,100):if(i%3 != 0):continueif(i%5 != 0):continueprint(i)行数は増えてしまいましたが、プログラムの見渡しはよくなりましたね。このように使いようによっては、breakとcontinueは便利です。個人的に私がよく使うのは「whileの条件判定にTrueをいれた無限ループ」をbreakで抜けるというものです。たとえば以下のような構造です。while(True):処理if(条件):処理break処理気をつけないと無限ループから抜けられなくなりますが、適切に使えば、きれいなコードが書けます。演習1[[1,5,3], [2,6,4]] は、リストにリストが入っています。内側のリストの最大値をそれぞれ求めるプログラムを書いて下さい。演習21から100までの整数で3の倍数の時は Fizz5の倍数の時はBuzz3の倍数でもあり5の倍数でもあるときは FizzBuzzと表示するプログラムを書いて下さい。※解答はこちらをご覧ください。次回はモジュールや関数について扱います。よろしくお願いします。
2015年06月29日
薄着必須のこれらからの季節、ムダ毛処理は避けて通れません。みなさんは腕や脚、わきなどのムダ毛、どうやって処理していますか?今回はムダ毛処理でよくおこなう「抜く」と「剃る」どちらのほうが肌に優しいのかを、美容ライターの大野えりかが紹介いたします。■ムダ毛処理が与える肌ダメージまず知っておいてほしいのは、むだ毛処理はどうしたって肌に負担をかけてしまうのだということ。肌に負担がかかることで日々ケアしている自慢の腕や脚が炎症を起こしやすくなり、見た目や触り心地まで変えてしまうことにもつながります。「抜く」と「剃る」の場合、実は「抜く」ほうが肌へのダメージが大きくなります。というのも、「抜く」という行為は肌の一部をちぎっていることになるからです。■抜く痛みは細胞が切り裂かれておこる!毛を抜くときチクッとした痛みを伴いますが、この痛みは細胞が切り裂かれる痛みだと言われています。毛根にある毛母細胞は周囲の血管から酸素や栄養をもらって成長しているため、「生きた細胞」ということになります。生きた細胞を傷つけるのですから、痛みを伴うのは当然のこと。そして、毛穴の奥ではちょっとした出血もしているのです。毛を抜いたあとに炎症を起こしたり、場合によっては膿んだりシミになったりするのはそのためです。■剃るならT字型のカミソリでオススメしたいのはT字型のボディ用カミソリです。電気カミソリは深くカットできる分、一見キレイに剃れたように感じるのですが、毛穴の中の毛を巻き込みながらカットするため、どうしても皮膚表面まで一緒にカットしてしまいます。それに比べ、T字のカミソリであれば自分で力加減ができるため、毛穴を傷つけることもありません。■ムダ毛処理によるダメージを減らすには?ムダ毛処理はどうしたって肌に負担をかけてしまうとお話しましたが、その負担をできるだけ軽くする方法があります。1.ムダ毛処理はお風呂あがりに皮膚は温度が下がると毛穴が閉じ、硬くなってしまいます。そこで、お風呂上りで肌が柔らかくなっている状態で行うのがおすすめ。また、ムダ毛処理をする際は肌を清潔にし、傷口から雑菌が入るのを防ぐ必要があります。処理する部分はボディソープで丁寧に洗っておきましょう2.ムダ毛処理後はクールダウン処理後は肌に負担がかかっていますし、除毛方法によっては内部で出血が起こっていることも。そのため、水で冷やしたタオルをあてるなどして、ムダ毛処理による炎症をおさえましょう。3.生理中、体調不良のときはやらない体調がわるいときは肌の免疫力が下がり、肌トラブルがおこりやすい状態になっています。こうしたタイミングで起こる肌トラブルはを治りが悪く、いつまでも炎症によるブツブツやシミが残ってしまうことにもつながります。これは「剃る」に限らず、抜いたり、除毛クリームを使う場合にも共通するムダ毛処理時のお約束です。■おわりに肌をきれいに見せるためにおこなっているムダ毛処理なのですから、肌になるべく負担をかけない方法を選びたいですよね。彼と腕が触れ合ったとき、「スベスベだね」と言われる肌を目指して、ムダ毛処理を行ってみてはいかがでしょうか。(大野えりか/ハウコレ)
2015年06月25日
日本オラクルは5月11日、東京電力がスマートメーターから取得するデータの高速処理IT基盤に、オラクルのデータベース・マシン「Oracle Exadata Database Machine」を導入し、稼働開始したと発表した。東京電力は、2014年4月よりスマートメーターの導入を開始し、2020年には2700万台に達する見込みだという。また、2015年2月1日より東京電力多摩支店サービスエリアのスマートメーター約14万台を対象に新システムの稼働を開始しており、段階的に拡大している。今回、これらスマートメーターから取得する検針値などのデータを収集管理するIT基盤として、スマートメーター運用管理システムを構築することが決定。東京電力はハードウェアとソフトウェアが最適に稼働するよう設計されたエンジニアドシステムズの活用により、導入作業開始から1年未満でシステムの稼働開始を実現したという。東京電力は、信頼性と拡張性の高いスマートメーター基盤の実現により、今後、顧客の使用形態に応じた多様な料金メニューの設定、よりきめ細かな省エネ支援などに取り組んでいく。
2015年05月11日
ON Semiconductorとオーディオ技術企業のAfterMaster HD Audio Labsは、共同でオーディオ向けデジタル信号処理(DSP)チップ「BelaSigna 300R AM」を開発し、発売を開始したと発表した。同製品は、1.8V電源で4mA動作が可能なほか、リアルタイムのマスタリング/リマスタリング処理技術、独自のAdaptive Intuitive Responseメカニズムを使用して原音の品質を維持するとともに、あらゆるリスニング体験にこれまで以上に奥深く明瞭で豊かな音質を提供するAfterMaster HDのアルゴリズムを実行することで、テレビ、ヘッドフォン、スピーカー、携帯端末、ストリーミングサービスなどをはじめとするオーディオ機能を備えた機器やサービスに対して高音質のハイファイサウンドを提供する。また、小型のWLCSPパッケージを採用しているほか、低消費電力であるため、ヘッドフォンやスマートフォンなどの小型のエレクトロニクス製品でもAfterMaster HD処理技術を活用することが可能になるという。なお、同製品はON Semiconductorのグローバルな販売チャネルおよび流通ネットワークを通じて入手することが可能だという。
2015年05月08日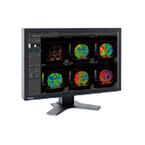
東芝メディカルシステムズは、複数のモダリティに対応する医用画像処理ワークステーション「Vitrea V7」の国内販売活動を開始したと発表した。Vitreaは、これまでCT専用ワークステーションとして国内外に向けて販売されてきた。新製品となるVitrea V7では、CT、MR、ガンマカメラ、PET-CTなど複数のモダリティで撮影された画像データを統合的に扱うことが可能になり、さまざまな臨床アプリケーションのほか、撮影プロトコルの管理、線量情報管理ツールなどを搭載していることから、撮影から画像処理までトータルに提供し、高度な診断の支援と院内業務の効率化を実現するという。また、新開発のプラットフォームを採用することでさまざまばアプリケーションの搭載を可能としており、他社アプリの搭載により、臨床現場の多彩なニーズに応えることを可能としている。
2015年04月16日
暖かくなり、これから肌の露出が増える季節。夏に向けて今からむだ毛処理はしておきたいところ。とは言え、人気の脱毛サロンに予約して行く時間も、毎日カミソリなどで地道に処理するのも時間がないので、なんとかケアできないかなと考えていました。今回、リニューアルしたというPHILIPS(フィリップス)の光美容器「Lumea(ルメア) プレジションプラス」を実際に体験してみました。2015年2月にリニューアルした「Lumea プレジションプラス」、主なリニューアルポイントは照射回数を8万回から14万回に増やして、より長期間使用できるようになったことや、アタッチメントが「ボディ用」だけでなく「顔用」、そして業界初の「ビキニエリア用」と3種類あることだそうです。実は私、脱毛サロンに行ったことはあるのですが、自分で光美容器を使ってケアするのは今回が初めて。ちょっとドキドキ&不安…。まずは下準備としてカミソリや電気シェーバーでむだ毛を除毛します。ジェルなどは一切いらないそう。そしてルメアの本体電源ボタンを押し、照射レベルを設定します。日本人推奨レベルは3~4だそうです。初めて使う時や自分に適した強さがわからない場合は照射レベル1から試せるのもいいですね。肌に正しく当たると、「READY」ランプが緑色に点灯。これが準備完了の合図です。あとは照射ボタンを押すだけ! すると黒色の毛に反応し、赤くバチっと光ります。「安全リング」という、肌に直角に当たっていないと照射できない仕様になっているので、誤作動も起きにくくなっています。多少パチっとした刺激はありますが、「痛い」というほどには感じませんでした。最初の1回目は、“バチ”っという照射音にびっくりしましたが、むしろ「これでいいの?」と思うぐらい、簡単にできることに驚き。これなら、自宅で気軽にできるからラクでいいですよね。しかもコードレスで使いやすかった!今回はむだ毛が気になる腕や脚に光を当てましたが、「Lumea プレジションプラス」なら「顔用」「ビキニエリア用」のアタッチメントもついてきます。「顔用」は、うぶ毛が気になる口周りなどがお手入れできて、「ビキニエリア用」はより太い毛にも対応するそう。部分や毛に合わせて、カスタマイズが効くのは便利ですよね。ちなみにお手入れの頻度としては、最初の2ヵ月は2週間ごと。その後は1~2か月に一度のお手入れで良いそう。頻繁にお手入れをしても効果は変わらないそう。ということで、また2週間後に試してみますね。たった2回の使用でツルすべ効果を実感できる※ようなので楽しみ。続編に乞うご期待くださいませ!※90人による12週間のテストの結果、ただし、個人差があります。/フィリップス社調べ(2012年)・Lumea 公式サイト ・ 毎日のむだ毛処理から解放! 2回でツルすべ肌を実感できる「Lumea」がかなり使いやすい【後編】
2015年04月03日
島津製作所は3月16日、全自動LC/MS前処理装置「SCLAM-2000」(研究用)を発売した。「SCLAM-2000」は、遠心処理を行った採血管などのチューブと試薬、2種類の前処理専用容器をセットし、PCまたは装置本体からの操作することで、全自動で生体試料の前処理とLC/MSによる分析が実行できる装置。最大60検体のLC/MS分析を自動で実行可能で、オンラインでLC/MSに接続されているため、前処理後に試料を手動でLC/MSにセットし直す必要がない。1時間あたり約20検体を処理することが可能だ。また、1検体ごとに逐次処理を行う方式を採用しており、検体ごとの前処理反応時間の差など、個体間のばらつきをなくし、日内差、日間差を含めた再現性≦10%の分析精度を実現する(同社評価による)。バーコードリーダ(オプション)による検体のID管理や分析結果の校正機能、試薬の残量や使用期限などの管理機能、装置保守履歴の記録機能といった多彩な精度管理機能により、常に最適な状態で装置を維持し信頼性の高いデータが取得できるとしている。さらに、キャップを外した採血管や試薬をセットした後は、検体および試薬を入力する2ステップのシンプルな操作で前処理を開始できるため、手技の操作ミスを低減することができる。加えて、満杯検知センサー付きの前処理容器の廃棄ボックスや廃液タンクを装置内に備えており、感染性試料を扱う際の感染リスク低減にも工夫がなされている。なお、価格はソフトウェア込みで1750万円(税別)。
2015年03月16日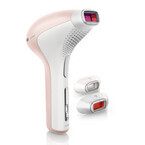
フィリップス エレクトロニクス ジャパンは1月27日、ムダ毛処理用の光美容器「Lumea(ルメア)」の新モデルとして「ルメア プレシジョンプラス」と「ルメア エッセンシャル」を発表した。発売は2月上旬。価格はオープンで、推定市場価格はプレシジョンプラスが69,800円、エッセンシャルが44,800円(いずれも税別)。○ルメア プレシジョンプラスルメア プレシジョンプラスには、照射面積の広いボディ用と敏感な肌に配慮した顔用、強い光でケアするビキニエリア用のアタッチメントが付属する。ビキニエリア用アタッチメントが付属するのは業界初だという(同社調べ)。安全リングが設置され、肌に密着していない状態では光を照射できない設計だ。ランプの耐久性を向上させ、前モデルの約80,000回から約140,000回へ照射回数を増やした。サイズはW150×D85×H235mm、重量は538g。出力は5段階で調整できる。電源は内蔵バッテリーで、約1時間40分でフル充電される。最大約370回の連続使用が可能だ(レベル5の場合)。カラーはピンク×ホワイト。○ルメア エッセンシャルルメア エッセンシャルは、ボディ用と顔用のアタッチメントが付属するエントリーモデル。照射回数は約100,000回。サイズはW140×D95×H180mm、重量は360g。コードの長さは1,950mm。出力は5段階で調整できる。カラーはシャンパンゴールド×ホワイト。
2015年01月27日
Imagination Technologies(IMG)は1月16日、Android向けPowerVR画像処理フレームワークを発表した。ハイダイナミックレンジ(HDR)、パノラマ合成、ジェスチャ認識、拡張現実(AR)など、先進的な画像処理や写真技術を処理するには、大量の演算能力が必要である。現在、CPUやDSPコアの能力に依存してこの性能要件を満しているが、こうしたプロセッサでハイダイナミックなコンテンツの映像フレーム処理を継続すると、デバイスの発熱に起因する課題が出てくる。PowerVR画像処理フレームワークは、独自の低消費電力並列処理を活用し、GPUとカメラセンサ、画像信号プロセッサ(ISP)、CPU、その他のSoC特有ハードウェアのシステムコンポーネントと密接に統合し、カメラアプリケーションに容易に組み込めるプログラマブルな画像処理パイプラインを実現できる。さらに、PowerVR GPUの電力効率と演算効率によって、将来の専用ハードウェア化SoCを待つことなく、スマートフォン、タブレット、その他民生電子機器における消費電力の制約の範囲内で、最先端の画像処理機能をカメラアプリケーションに組み込めるようになる。そして、今回のAndroid向けPowerVR画像処理フレームワークには、OpenCLおよびEGLアプリケーションプログラミングインタフェース(API)への拡張が含まれており、YUVとRGBカメラデータの効率的なゼロ・コピー・サンプリングを実現する。この拡張を使用すると、たとえばYUVデータ形式を直接操作して、輝度データに対してのみ動作するアルゴリズムの高速化ができる。また、別の拡張としてサンプリング時にYUVデータをRGBに動的に変換する構成を、ハードウェアに与えることができる。加えて、このフレームワークには、ゼロコピー拡張をカメラのHAL(Hardware Abstraction Layer)に実装するための、ローレベルの関数も含まれている。この拡張実装によって、カメラレンズ、画像信号プロセッサ(ISP)ハードウェアの諸機能やAndroid標準のカメラアプリケーションの制約を超えた利用が可能になる。なお、すでにフレームワークのゼロコピー機能を使用しているユーザーは、高速画像処理アプリケーションを実装するために、共有ハードウェアの追加は必要ないという。
2015年01月19日
肌の露出が少ない冬は、ついついムダ毛処理を怠ってしまいがち。「見えないもん、気にする必要ないじゃない」と思ったあなたは要注意!見られているのは、服で隠れる場所だけではありません。顔の産毛や手先などは、冬でも油断できない部分です。特に口の周りの産毛には注意したいもの。「牛乳を飲んでいた時に、産毛に牛乳がべったりついてしまった」という、リアルな声もあるほどです。カーディガンのそでをまくったときにムダ毛丸出し、なんていう状況も避けたいですよね。産毛の処理ってどうすればいいの?肌のお手入れをきちんとしているのに、肌がくすんで見えることはありませんか?もしかすると、そのくすみは顔の産毛が原因かもしれません。定期的に産毛の処理をしてあげると、肌のトーンが明るく見えます。また、角質を落とすことで、化粧ノリもよくなるんですよ!でもカミソリを使うと、お肌に負担をかけてしまうことも……。オススメは、毛の黒い色素にだけ働きかける、お肌に優しい光脱毛です!脱毛するなら自宅が一番!テレビや電車内の広告で目にすることが多い「光脱毛」ですが、脱毛サロンや美容整形外科へ通わなければできないものと思っていませんか?光脱毛器があれば、自宅でも手軽にムダ毛の処理を行うことができます!サロンへ通う手間もなく、また価格の面から見てもメリットがいっぱい。サロンへ通う場合には毛周期の関係で、2~3カ月に1度、足を運ぶ必要があります。自分の家で脱毛をすることができれば、通う手間が省けますし、しつこい勧誘に疲弊することもありません。たとえば手のひらサイズの『センスエピG』なら、自分のライフスタイルに合わせて、自宅で光脱毛をすることが可能です。気になる部分のムダ毛処理を、思い立ったときに人目を気にせずできるため、とても便利です。安い!! 美容大国イスラエルの技術がギュッと詰まった脱毛器センスエピGは、わずか220gという軽量でコンパクトなサイズなので、首筋やうなじなど自分では処理の難しかった部分もラクにお手入れすることができます。また、面倒なカートリッジ交換も、ジェルやクリームを塗る必要もありません。思い立ったら、さっとお手入れできちゃいます。ワキならわずか1分、両脚も約10分でスピーディーに照射できますよ。1台で顔から指先まで全身の脱毛が可能で、値段は1台1万円台。10万円以上かかるサロンでの全身脱毛と比べれば、ずっと経済的。この美容機器、業界で多くの商品開発に携わってきたイスラエルの専門家チームによって開発されました。イスラエルの美容分野は各国でも評価が高く、美容機器や死海の塩を利用したスキンケア商品は世界の女性たちから支持を受けていますよね。今から始めれば、夏に「勝ち組」になれる!毛周期に合わせて処理すると、効果が実感できるのに一般的には半年かかると言われています。今から半年後といえば、露出の増える夏に突入する時期です。夏と比べて紫外線の量が減る冬は、脱毛に適した時期でもあります。日焼けしている状態では肌に負担がかかりやすいのです。また、露出することが少ない冬は、処理中の状態を隠しておくこともできます。このように、冬に脱毛を始めるメリットはいっぱい!今ならセンスエピGを購入した人のなかから、抽選で20名様にOZmallのスペシャルディナーまたはホテル宿泊で使える2万円分のチケットが当たるキャンペーンを実施中です。毛周期に合わせて今からお手入れを始めれば、夏までにキレイを実現できそうですね。※参考: 家庭用脱毛器「センスエピG」Image photo by Imagia、Pinterest
2014年12月20日
○3D点群処理エンジニアの歴史と人口前回まで紹介した「3D点群処理が実現できる事の多さや利点」ですが、コンピュータビジョン界隈のエンジニアでさえも、「そもそも知らない」「知っていても使いこなせるレベルにはない」方が多いのが現状です。なぜなら、安価なデプスセンサーが登場するまでは3Dコンピュータビジョンとはマイナー技術で、センサーの購入にお金もかかるので、エンジニアや顧客の人口も少ない技術であったのが理由です。従って、Kinect登場以前は3D点群や距離画像を用いた処理のビジネス応用は、限定的なものでした。かつては非常に高額な3Dセンサーしか市場には存在しなかったので、その需要は高額の投資ができる大企業や大学の研究室など限定的で、近年価格帯は下がってきたものの、一般の人の目にはなかなか触れない技術でもありました。Kinect登場以前から3D点群が活用されていた分野の例としては、建築土木などでの測量や、工場用機械・ロボットの眼としてのマシンビジョン、また医療用の3Dスキャン(MRIやCT)などがあげられると思います。これらの応用先においては、たとえ3Dセンサーが数百万円以上の非常に高価なものであろうと、「製品や広い空間を3Dで広範囲にかつ精密に測ることでメリットが出る分野」であり、3D画像センシング技術は活用されてきました。ここ10年で、レーザーレンジファインダーの低価格化や高性能化・安定化が始まり、Kinect前後登場の前後から、数十万円台の3Dセンサー(ステレオカメラやレーザーレンジファインダーにプロジェクターカメラなど)の応用先も増えています。ただ、これらの3Dセンサーも、一般の消費者向けの応用は過去ほとんど存在していなかったので、私のように計測業界の会社で仕事をしたことがある人でもないと、実際の3Dセンシングの活用イメージや技術の使い方を知り得なかった時代が、Kinect登場までは続いていました。○Point Cloud Libraryとモバイルタブレットで始まる3Dセンシングの民主化Kinectと同時期に登場した「Point Cloud Library」という、業界初のオープンソースの点群処理ライブラリの登場が、点群処理ソフトウェアの開発を容易にし、参入の敷居を一気に下げています。OpenCVの3D点群版とも言えるPoint Cloud Libraryについて、私は登場時からWebで技術情報を積極的に発信していた事もあり、2年ほど前から3D点群処理を活用したい企業に、技術的なコンサルティングを行っております。また、Point Cloud Libraryの入門セミナーの講師としても登壇させて頂いており、ブログやメルマガなども含めて、点群処理が必要なエンジニアの学習サポートにも力を入れております。旧来からの、B2B寄りの高価な計測器を用いて精度の高い点群を取得する用途においても、無料でオープンソースの点群処理ライブラリ「Point Cloud Library」の登場によって、点群処理アプリケーションの生産性が飛躍的に改善しています。OpenCVのようなオープンソースの大規模ライブラリが存在しなかったのがこの3D点群処理分野であり、個別に各3D点群処理を実装していく必要がありました。それが、Point Cloud Libraryにはフィルタリング、平面推定、点群間の位置合わせ、特徴量の計算、各種デプスセンサーとの簡単な接続など、基本的な点群処理が揃っており、3D点群処理ソフトウェアを開発するための敷居が、初めて大きく下がったと言えます。これまでも3Dセンシングを活用してきた計測分野寄りの皆様が、私のPoint Cloud Libraryのセミナーに毎回多くお越しいただいているのを見ると、まずは旧来からのB2B分野ではPoint Cloud Libraryによるソフトウェア開発への移行が始まっています。一方、これまでのKinectなどの安価なデプスセンサーは、すでに本連載でもとりあげてきたように、ディスプレーの前に据え置きで用いる用途が主流でした(もしくは主な想定でした)。それに対して、2015年にGoogleから登場する予定のTangoセンサーを用いたタブレットや、以前本連載でも紹介した「Structure Sensor」など、モバイル向けのデプスセンサーが登場し始めています。今後モバイルでのデプスセンサーの普及も進めば、B2C向けのデプスセンサーのビジネス用途も拡大するはずです。ただし、旧来の計測的な需要を安価なデプスセンサーで置き換える用途はさておき、B2C向けでは点群のビジネス活用例がまだまだ少ないのが現状です。とはいえPoint Cloud Libraryとモバイルデプスセンサーで、参入の敷居が下がる事は確かなので、今後少しずつ3D画像センシングの需要が一般ユーザー向けにも拡大していくと、個人的には思っております。以上で、3D点群編の導入は終わりとします。次回以降、まずは昔から点群処理が応用されている分野での、3D点群処理の応用例を紹介していきます。その後、現在の安価なデプスセンサーを用いた3D点群処理の話へと進んでいきたいと思います。点群処理のご興味のあるエンジニアの方は、私が後方支援しておりますPoint Cloud Consortiumの活動もチェックしていただければ幸いです。林 昌希(はやし まさき)慶應義塾大学大学院 理工学研究科、博士課程。チームスポーツ映像解析プロジェクトにおいて、動画からの選手の姿勢の推定、およびその姿勢情報を用いた選手の行動認識の研究に取り組み中。(所属研究室が得意とする)コンピュータビジョン技術によって、人間の振る舞いや属性を機械学習・パターン認識により計算機で理解する「ヒューマンセンシング技術」全般に明るい。技術商社でエンジニアをしていたこともあり、海外のIT事情にも詳しい一方、デプスセンサ等で撮影した実世界の3D点群データの活用を推進するための「Point Cloud コンソーシアム」での活動など、3Dコンピュータビジョンのビジネスでの普及にも力を入れている。また、有料メルマガ「DERiVE メルマガ 別館」では、コンピュータビジョン・機械学習の初~中級者のエンジニア向けの、他人と大きな差がつく情報やアイデアを発信中(メルマガでは、わかりやすい理論や使いどころの解説込みの、OpenCVの初心者向け連載なども展開中)。翻訳書に「コンピュータビジョン アルゴリズムと応用 (3章前半担当)」。
2014年11月25日
20~30代の女性を対象にしたムダ毛処理に関するインターネット調査結果家庭用脱毛器を製造・販売するホーム・スキノベーションズ・ジャパン株式会社は、20歳以上40歳未満の女性661人を対象にインターネットにて「ムダ毛処理に関する調査」を実施した。その調査結果によると、「ムダ毛処理の仕方」は68.9%がカミソリと回答。ムダ毛処理の経験については、86.7%の人が「現在している」と答え、3.6%の人が「全くしていない」となった。処理方法はカミソリに続き、エステサロン/クリニックという回答が16.6%という結果に。また、頻度についての質問では、冬の頻度は全体的に落ち込み、年間を通して最も多かったのは「週1回」という回答だった。そして、約8割の女性がムダ毛処理の際に、肌への負担を感じた経験を持っていることが分かった。ムダ毛処理による肌への影響の認識は薄い?ムダ毛処理が肌にどれだけの影響があるかの認識については、60.4%の女性が「季節によってムダ毛処理は負担が左右する」ことを知らないと答えている。また、毛周期についての知識も薄く、「毛周期を意識してムダ毛処理」を行っているかの質問では、63.6%が「している」、3.6%の人が「全くしていない」という結果になった。毛周期を把握している女性は少なく、把握している女性はわずか16%であった。最後に、「ムダ毛処理をしておけば良かったと思った時はありますか」という質問では、82.9%の人が「はい」と回答。効率的なムダ毛処理を知ることで肌への負担も変わってくるようだ。(画像はプレスリリースより)【参考】・PRTIMES
2014年11月18日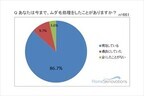
ホーム・スキノベーションズ・ジャパンはこのほど、「ムダ毛処理に関する調査」の結果を発表した。同調査は10月16日~20日、20歳以上40歳未満の女性を対象として実施。661名の回答を得た。○ムダ毛処理の回数は「週1回」が最多「ムダ毛処理の経験」を聞いたところ、86.7%が「現在している」と答えた。「全くしていない」人はわずか3.6%だった。「ムダ毛処理の頻度」を聞いたところ、年間を通して最も多かったのは「週1回」。僅差で「週2~3回」が続いた。また、冬になると処理の頻度が低下していることもわかった。さらに、82.9%が「ムダ毛処理をしておけばよかったと思ったことがある」と答えた。「最も行ったムダ毛処理の仕方」は、「カミソリ」が63.9%で最多。「サロン・クリニック」が16.6%、「家庭用脱毛器」が10.8%などとなった。「ムダ毛処理後の肌への負担」については、8割以上の女性が、負担を感じたことがあると答えた。○季節によってムダ毛処理の負担が変わる知識がない女性が6割「ムダ毛処理は季節によって肌への負担が増減することを知っているか」と聞いたところ、「知っている」と答えた女性は4割未満だった。また、「毛周期」について聞いたところ、自分の毛周期を把握している女性は16.0%にとどまったのに対し、「毛周期自体を知らない」女性は44.0%にのぼった。
2014年11月17日
NXP Semiconductorsは、「常時ON」センサの信号処理を低消費電力で実現することを可能とするマイコン「LPC54100シリーズ」を発表した。同シリーズは、センサ・リスニング時に必要な電流を3μAに抑えているほか、非対称デュアルコア・アーキテクチャを採用することで、スケーラブルなアクティブ消費電力/性能の最適化を実現することが可能となっている。このため、競合製品に対し平均消費電力を20%低減することが可能だという。また、センサ・データの収集や蓄積、外部との通信には55μA/MHz Cortex-M0+コアを用い、高度な数値演算を伴うアルゴリズム(モーション・センサ・フュージョンなど)ではCortex-M4Fコア(100μA/MHz)を使用することで処理時間を短縮することから、全体的な消費電力の節減が可能となっている。さらに、電力効率向上のためにゼロから開発したアナログ/デジタル・インタフェースを採用しており、センサ信号処理ではクラス最小の消費電力を実現しているほか、全電圧範囲(1.62V~3.6V)でフルスペック性能の実現を可能にする12ビット、4.8MspsのA/Dコンバータ(ADC)や低消費電力のシリアル・インタフェースなども含まれているという。なお同シリーズは3.2mm角のWLCSP49と10mm角のLQFP64パッケージで2015年第1四半期から出荷開始予定で、単価は1万個で1.99ドルからとなっている。
2014年11月13日
キヤノンITソリューションズは9月26日、画像処理アプリケーションの開発を支援するツール「RobustFinder Source-Code Generator 1.0」の販売を開始した。対応OSはWindows 7(32ビット/64ビット)で、価格はオープン。RobustFineder Source-Code Generatorは、工場の生産設備や検査設備など、さまざまな産業用装置に組み込まれる位置決め制御や表面検査、異物検査、個数検査などを目的とする画像処理アプリケーションの作成を支援するツール。具体的には、同社の産業用画像処理ライブラリ「RobustFinder 10」および、Matrox社の画像処理ライブラリ「MatroxImagingLibrary 10」から、「位置決め」や「解析」などの画像処理モジュールをマウス操作で選択することで、アルゴリズムを構築、ソースコードを自動生成する。同ツールを使えば、産業用のさまざまな装置で使用する画像処理アプリケーションを短期間で作成できるというわけだ。近年、画像処理アプリケーションは、処理内容や開発環境の多様化や複雑化に伴い、開発工数の短縮・効率化が課題となっている。そこで同社は今回、1998年から開発販売を手掛けるRobustFinderの機能や性能を生かせる画像処理アプリケーション開発支援ツールを開発した初年度の目標販売数は100本を見込む。
2014年09月26日
(画像はプレスリリースより)今や女子高生も「ムダ毛処理」は常識?女子高生や女子大生などの若い世代の女の子の間で、「ムダ毛のお手入れ」はもはや常識。それに伴い、ムダ毛の自己処理による肌トラブルも増加傾向にあるそうです。美容サロンが意識調査美容脱毛専門サロン「ミュゼプラチナム」では、関東地区・関西地区の女子高生や女子大生などの若い世代の女性600名と、娘を持つ母親200名を対象に「脱毛に関する意識調査」を実施しました。8割以上の女性がムダ毛の自己処理トラブルを経験調査にて、ムダ毛を自己処理し、失敗した経験があるか質問をしたところ、8割以上がカミソリ負けなどの肌トラブルや失敗を経験したことがあるとのこと。ムダ毛の自己処理は手軽ですが、なかなか上手くできないもの。多くの女性に失敗経験があるようです。好きな人がいるとアンダーヘアのムダ毛が気になる?アンダーヘアの手入れについての質問をしたところ、女子大生の約7割が「手入れをしている」と回答。女子高生でも約3割が何らかの手入れをしているということが分かりました。若い世代でも「アンダーヘアのお手入れ」は欠かせないようです。また、調査では「好きな人がいる女子の方がアンダーヘアのムダ毛が気になっている」という調査結果も。正しい「ムダ毛の自己処理」を「正しいムダ毛の自己処理方法」としておすすめの道具は、毛包炎や、埋没毛のなりやすい「毛抜き」よりも「カミソリ」だそう。また、お手入れは、お風呂上がりのタイミングや、ホットタオルで肌を温めるなどをして肌をやわらかい状態にしてから行った方がいいとのことです。秋になりやすい“秋バテ肌”に注意!秋頃のお肌は、夏に受けたさまざまなダメージにより肌トラブルになりやすい“秋バテ肌”になりがち。正しいお手入れの仕方でトラブルのない美しいお肌を保ちましょう。【参考】・株式会社ジンコーポレーション プレスリリース
2014年09月10日
肌の露出が増える季節になると気になる、脇や手足などのムダ毛。のばしたままにはできないので、処理をするのはやむを得ないのですが、ムダ毛処理はどうしても肌に負担をかけてしまうと心得てから行いましょう。特に剃刀などで「剃る」よりも、毛抜きなどで「抜く」ほうが、肌へのダメージは大きくなります。というのも、抜くという方法では、皮膚の一部をちぎることになるからです。毛は、毛根にある毛母細胞の分裂によって成長します。毛母細胞は、まわりにある血管から酸素や栄養をもらって細胞分裂を繰り返します。つまり、毛根自体は生きているのです。毛を抜くと、この生きた組織を引き裂くことになるので、当然痛みをともないます。目には見えませんが、毛穴の奥で多少の出血もしていま す。これを繰り返していると、毛穴が炎症を起こして膿んだり、その炎症の跡がシミになったりと、さまざまな肌トラブルが起きてしまいます。数ある除毛方法の長所、短所を理解して、無理のない方法を選びましょう。■1.除毛方法<剃る>・電気カミソリ穴の中に毛を引き込みながらカットしていくので、深剃りができます。ただし、その分皮膚まで一緒に切ってしまうこともあります。その傷口からかゆみが出たり、シミになったりすることもあります。・安全カミソリT字型の安全カミソリタイプは、自分で細かい手加減がし易いのが特徴です。毛穴が鳥肌のようにボツボツと立っている人は、深剃りの電気カミソリだと肌を傷つけやすいので、こちらの方が向いているでしょう。ただし、剃った後に肌が乾燥して、かゆくなることもあります。■2.除毛方法<抜く>・毛抜き毛抜きを使って1本ずつ毛を抜く方法。手間がかかる上に、トラブルが起きやすいです。ワキをずっと毛抜きで抜いていると、皮膚が硬くなり、ひきつれたようになることもあるので注意。また、皮膚の下に埋もれた「埋没毛」ができ、そこから毛嚢炎を起こすことがあります。・テープ除毛したい部分に粘着力のある専用のテープを貼って、はがし取る方法。一度にたくさん抜ける手軽さはありますが、そのぶんダメージも大きいです。また、ワックスと違って、角質も一緒にはがしてしまうことも多いです。肌の弱い方は極力避けてください。・ワックス温めたワックスを皮膚に塗り、冷えて固まったら剥がすタイプです。皮膚が温められるため、毛抜きやテープなどより若干負担は少ないでしょう。また、パラフィンパックと同じ原理で、除毛後に肌がしっとりする保湿効果もあります。・脱毛機器電気式の脱毛器で、皮膚を温めたり、まわりの皮膚を押さえたりしながら抜くので、毛抜きよりは肌への負担が少ないでしょう。しかし、抜くことに変わりはないのでトラブルも多いです。「永久脱毛」などとうたった家庭用脱毛器がありますが、抜いている限りまた毛は生えてきます。「レーザー照射で永久脱毛」という商品も出回っていますが、レーザーは医療機関でしか扱えないため、家庭用として販売されることはありませんので注意してください。■3.除毛のルールを守りましょうどれだけ気を使っても肌ダメージが避けられない除毛ですが、以下のルールを守ればダメージは確実に減らせます。これはどんな方法でも共通です。除毛のタイミングは体が温まっているお風呂上りがベストです。・皮膚を清潔にしてから行う除毛すると、皮膚が傷つきますので、清潔にしておかないと雑菌が入ってしまう恐れがあります。石鹸で丁寧に洗ってから行いましょう。・皮膚を温める皮膚も毛も、温度が下がると硬くなり処理しにくくなります。除毛する部位の皮膚を温めておきましょう。・処理後はクールダウン除毛した部位に水で冷やしたタオルなどをあてて、暫く皮膚をクールダウンさせましょう。こうすることで肌の炎症をおさえます。■おわりに肌はとてもデリケート。ムダ毛ケアは自分の肌に合った方法を選択してください!(下山一/ハウコレ)
2014年08月30日
夏はムダ毛の処理の回数がぐっと増えますね。ムダ毛の処理は永久脱毛を除けば、剃る、抜く(脱毛)、溶かす(クリームなど)という3通りが主流ですが、実はいずれの処理方法も肌にかなりのダメージを与えてしまうことをご存知ですか? 画像:(c)japolia - Fotolia.com適切な処理をおこなうことはもちろんですが、処理後のケアを怠ると、肌が炎症を起こし黒ずみになってしまう可能性もあります。■ワキは特に黒ずみやすい場所特にワキは処理後のケアを忘れがちな部位のためか、黒ずみをつくってしまう方が多くいらっしゃるようです。もともと熱がこもりやすく汗をかきやすいワキこそ、きちんとしたケアが必要ですから、怠らないようにしてくださいね。さっそく、適したムダ毛処理とおすすめのケア方法を解説しますので、参考にしてください。■まずは体のコンディションチェックから意外かもしれませんが、まずは体のコンディションを確認してください。というのは、抵抗力が低下してしまう生理前にムダ毛の処理をするのはおすすめできないからです。抵抗力が万全でないと肌が敏感になっていることが多いため、炎症が起きやすくなっています。もちろん生理前でなくとも体調が優れないときも同様です。<処理前の事前準備>ムダ毛の処理時、ぜったいに止めてほしいのが、乾燥した肌に処理を施すことです。これはワキだけでなく脚や腕、お顔のムダ毛処理の際も同様ですが、乾燥している肌というのはわずかな刺激でダメージを受けやすくなっています。ですから、お風呂にゆっくり浸かって肌をやわらかくしてからの処理がもっともおすすめ。もし時間がないのであれば、蒸しタオルで肌をやわらかくしたり、保湿クリームなどでマッサージをし、肌を整えてからおこなうのがよいでしょう。■いざ! ムダ毛処理<剃る>シェービングによる処理の場合は、肌の滑りをよくするためにシェービング剤を使用しましょう。石けんやボディシャンプーの泡を使われる方がいらっしゃいますが、毛をやわらかくする成分を配合しているシェービング剤の方が、より肌にやさしく剃ることができます。さらに、ジェルタイプのシェービング剤であれば毛や肌の凹凸が見えますので、肌を傷つける心配が少なく処理することができます。シェービング剤がなじんだら、カミソリを持つ手を(滑って肌を傷つけないよう)きちんと洗い、肌に刃を押し付けないようにして軽いタッチで剃ります。<抜く>お肌のことを考えるとムダ毛を抜くことはあまりおすすめできませんが、脱毛処理をおこなう際は、脱毛器、テープ、ワックスいずれを使用する場合でも毛を短くカットしてからにしましょう。皮膚が引っ張られる力を軽減し、肌ダメージを最小限にとどめます。毛抜きで処理する際は、生え際近くの皮膚を押さえながら脱毛してください。<溶かす>タンパク質という体毛の成分に着目し、アルカリ性の成分を用いて毛を溶かす脱毛方法。クリームが代表的ですね。パッチテストをかならずにおこない、用法、用量を守って処理をしてください。次のページからは処理後のケア方法をご紹介します。■ムダ毛処理後のおすすめケア<剃った後>カミソリ負けしていないようであれば、アフターローションをたっぷり塗布します。アフターローションがなじんだら、黒ずみを防ぐために化粧水、乳液でケアします。万が一カミソリ負けをしてしまっていたら、ひやっとする程度の冷たさにした濡れタオルでワキを冷やし、消炎作用のある軟膏などを塗ります。<抜いた後>ムダ毛を抜いたあとはすぐに冷やします。氷などではなく、適度に冷やしたひやっとする程度の濡れタオルがいいでしょう。ムダ毛を抜いた後は毛穴が開いている状態ですので、濡れタオルで肌が落ち着いたら消毒液をコットンにしみこませワキにあてます。その後は殺菌効果のある化粧水などでケアします。<溶かした後>既定の時間が終了したら、まずはしっかり流します。薬剤が残っていると肌はますますダメージを受けますので、ぬるま湯など刺激の少ない温度の水でやさしく隅々まで流してください。薬剤が塗布された時点でお肌はダメージを負っていますので、ゴシゴシと洗うのは厳禁! あくまでやさしく流し落としてください。その後は保湿クリームなどでケアしますが、スクラブ入り、フルーツ酸系など刺激のあるものはもちろんNG。肌にやさしいものを使ってください。■もしも黒ずみができてしまったら…ムダ毛の生える範囲は実に広範囲。場合によっては黒ずみも広範囲に及びます。ですから外側からだけのケアではなく、体の内側からの同時アプローチをおすすめします。まずはビタミンCを意識して摂取しましょう。加えて保湿効果の高いしっとり系のケアをワキ全体に施します。そしてしばらくムダ毛処理をお休みしてから、メラニンに対するケアをおこなってください。美白といわれるメラニンケア用品は傷や炎症のある肌にとっては刺激となる場合が多いため、処理による炎症のあるうちは逆効果になってしまうことがあります。タイミングの見極めが重要です。特にワキは汗や汚れで炎症が治まりづらい部位といえます。肌の状態をきちんと見極めたケアを繰り返すことが、黒ずみ解消に適したケアといえるのです。夏は電車のつり革につかまるだけでワキも露出してしまいます。適したケアでどんなところもキレイでいてくださいね。
2014年08月24日




















