
今回はマルチスレッドについて扱います。マルチスレッドは、簡単に言ってしまえば複数の処理を「並列」に進めることができるものです。マルチスレッドの反対がシングルスレッドであり、これは複数の処理を順番に進めていくものです。逆に言えば、ある処理が終わるまでは次の処理を実施することはできません。マルチスレッドおよびシングルスレッドの“スレッド”は「プログラムの実行単位」のことで、名前からわかるようにマルチスレッドはプログラムをマルチな実行単位で実行します。今回の流れとしては、まず最初にプログラムの実行時間の測定手法について学びます。これを理解していないとマルチスレッドを使った高速化がどれほど効果的なものか理解しづらいためです。次にさまざまな処理にかかる遅延がどれほどのものかについて学びます。それらの基礎ができたうえで、シングルスレッドの問題点について、その次にマルチスレッドがどのようにその問題を克服するかについて扱います。そして実際にPythonでどのようについてマルチスレッドを使うかを学び、最後にマルチスレッド特有の問題点について学びます。なお、今回も内容が多くなっため前後編に分けます。今回は簡単なマルチスレッドの使い方、次回は発展内容となります。○プログラム速度の測定方法マルチスレッドを使うメリットのひとつに遅延(実行速度が遅い)の問題を回避できる可能性があるというものがあります。ただ単にマルチスレッドの使い方の説明をするよりも、実際にプログラムの速度を計測しながらどのようにして処理速度が向上するかを体験してもらいたいと考えています。そのため、まず最初にプログラムの実行速度の計測方法について扱います。なお、速度の測定をきちんと実施したい場合は、今回扱うような簡易的な方法ではなく、専用のきちんとしたパッケージを使ったほうがいいかもしれません。今回利用する測定方法は簡単に言うと、現在の時刻を取得処理先の時刻と現在の時刻の差分を取得という方法で行います。このようにすることで、上記の「処理」にかかった時間が測定できます。現在の時刻の取得方法はtimeモジュールのtime()関数を使います。簡単にですが、サンプルを試してみましょう。import timetime_before = time.time()time.sleep(5)time_after = time.time()time_elapsed = time_after - time_beforeprint(time_elapsed)最初なので少し冗長に書いていますが、それほど難しくないですね。上記だとtime.sleep()関数で5秒間わざとスリープさせて、その実行速度を求めています。これを実行すると私の環境では以下のようになりました。# python test.py5.00498509407スリープした5秒だけでなく、「時間の取得処理やその他」にかかる時間も含まれますので、ジャスト5秒にはなっていません。まぁ、だいたい5秒なのでOKでしょう。今後はこの方法で時間の測定をしていきます。○さまざまな処理の速度と遅延先程はsleep関数の実行速度を計測しました。ほかの処理はこれほど簡単に実行時間を推測することはできませんが、プログラムの処理速度はその処理内容に応じてかかる時間にある程度の傾向があります。マルチスレッドを使う場合は、この推測される処理時間に意識を配る必要があるので、簡単にではありますが、さまざまな処理の実行速度を計測してみたいと思います。まず、今回の遅延測定のコードのベースとなる「何も遅い原因のないプログラム」の測定をしてみます。import timesum_value = 0current_time = time.time()for i in range(0, 10000):Noneprint(time.time() - current_time)ループ分の中がNone(処理をしない)となっているので、ただ単にループを回しているだけです。この実効速度は以下のようになりました。# python test.py0.0005049705505370.5ミリ秒ですね。次にループ処理の中で合計値sum_valueを求める処理を書いてみます。要するに足し算にかかる処理時間が追加されます。import timesum_value = 0current_time = time.time()for i in range(0, 10000):sum_value += iprint(time.time() - current_time)Noneだったところが変わっていますが、それ以外はまったく同じです。この実行速度は0.000903129577637となっているので、約1ミリ秒と処理にかかる時間はオリジナルの2倍程度になっています。次にprint文で合計値を出力するようにしてみます。これは「画面への出力処理」にかかる時間が追加されるということです。import timesum_value = 0current_time = time.time()for i in range(0, 10000):sum_value += iprint(sum_value)print(time.time() - current_time)この実行速度は私の環境では0.027067899704となりました。オリジナルのループするだけのコードに比べると処理時間が約54倍となっています。足し算に比べて処理時間が一気に跳ね上がりましたね。ここまでをまとめると、以下のようなことがわかります。足し算は速度が早いprint文による画面出力は遅いこの処理速度の違いはなんだと思いますか? 答えは簡単で、足し算は「CPUとメモリ」の処理であり、print文は「画面出力というIO処理」というところです。Pythonで処理を書く場合、その実効速度は以下の図のような傾向があります。Pythonで書いても直接Cで実行される場合とインタプリタで解釈されて実行される場合があります。前者のほうが当然速いのですが、どういう場合にCが走るかを知っていないと使いこなせないので、初心者はそこまで両者を区別する必要がないです。ただ、図の青色の処理は主にCPUとメモリだけで実行されるのに対して、オレンジの処理は「より低速であるほかの装置」が関わってくるので実行時間がガクンと落ちるということは知っておく必要があります。print文も画面出力が関わってくるので、実行速度が落ちたのですね。さて、次はディスクアクセスをさせてみます。なお、私の環境はSSDなのですが、HDDだと実行速度がこれよりも大幅に落ちる可能性があります。また、ディスクアクセスは最適化が走りやすい処理内容なので、同じコードでもPythonのバージョンやOSによっても処理速度が大きく変わる可能性があります。プログラムは以下のようになります。まず、ファイルをオープンして、そこにループで連続で追記を行い、最後にクローズをするというコードです。import timesum_value = 0current_time = time.time()f = open(’/Users/yuichi/Desktop/a.txt’, ’a’)for i in range(0, 10000):sum_value += if.write(str(sum_value) + ’\n’)f.close()print(time.time() - current_time)この実行速度は先程のprint文よりも早く、0.00518202781677となりました。ループ内での足し算だけのコードに比べ、6倍ほどの実行時間がかかっているものの、print文よりかはだいぶ速いですね。ただ、先に言ったようにSSDではなくHDDだともっと速度が遅くなる可能性が高いです。これはSSDがランダムアクセスに強いのに対して、HDDは回転するディスクと移動するヘッダという構成なので、飛び飛びのデータを読んだり書いたりする動作が遅いためです(おそらく書き込み処理は最適化でバッファリングされると思うので、今回のような使い方ならHDDでもそれほど遅くない気がします)。なお、ファイルのオープン・クローズをfor文の中で行うと実行時間は0.567183971405となりました。ここから「ファイルに書き込む処理」よりも「ファイルのオープン・クローズ処理」のほうがずいぶん時間がかかることがわかりますね。こういうように速度を検証すると書き込むたびにオープン・クローズするよりも、オープンしたファイルに連続で書き込むほうがよいということがわかってくると思います。検証は大事です。次に機器外へのネットワークを経由したアクセスを試してみます。具体的には外にデータを送ったり、取ってきたりといった処理です。Pythonだと普通はTCP/IPネットワークの利用だけがこれに該当すると思います。サンプルコードはさまざまな有名なWebサイトのトップページのHTMLを取得するというものです。import time, urllib2current_time = time.time()urls = [’’, ’’, ’’]for url in urls:response = urllib2.urlopen(url)html = response.read()print(time.time() - current_time)urllib2というライブラリを使って、指定されたページを開いてHTMLを取得しています。この実行速度は私の環境(携帯の回線)では0.623227119446となりました。たった3ループするだけで0.6 秒かかっていますね。1万ループさせるまでもなく低速なことがわかります。ある程度察しはつくかと思いますが、なぜこれほど処理に時間がかかるかは次に述べます。○マルチスレッドの基本今までの話を通して、処理によってかかる時間に違いがあることがわかりました。問題なのはネットワークアクセスのような「時間がかかる処理」を順に実施すると、合計の処理時間が長くなってしまうことでした。先ほどのHTML取得の例は以下の図のようなイメージです。ただ、よく考えてみてください。あるサイトからHTMLを取得する際に、そのリクエストをするホスト(Pythonを動かしているPC)は何をするかというと以下のとおりです。リクエストをするレスポンスを待つレスポンスを受ける2番目の処理は上記図の「HTTP Request (1) + サーバー処理(2) + HTTP Response (3) 」となります。この間はただ待っているだけですので、要するにPythonのプログラムを動かしているホストは「時間だけ使っているが何もしていない」状態です。3つのサイトからHTMLを取得するということは、その何もしない待ち状態の処理を3回繰り返します。この時間の無駄遣いは、ある程度は解消できます。どうせ待つのであれば、以下の図のように連続で並列にリクエストをしてしまえばよいのです。そうすると処理時間は「各処理(HTML取得)の合計値」ではなく、「最長となった処理の時間」となります。これを実現するのがマルチスレッドと呼ばれる機能です。マルチスレッドを使うことで、本来はプログラムが待ちになってしまう箇所で別の処理を実行することが可能なため、CPU の計算資源をより有効に活用することができます。これはなにも計算資源の節約のためではなく、アプリケーションやサービスのユーザビリティの向上やレスポンス時間の短縮にも利用することができます。少し説明をします。たとえばあるGUIのプログラムがあるとしましょう。もしこれがマルチスレッドを使わずに動いていたとすれば、ある重たい処理をGUIで実行すると、その間はほかの処理が停止してしまいます。GUIの操作を受け付けられなくなり、見た目のアップデートもされなくなるのでアプリケーションがフリーズしてしまったように見えるはずです。一方、マルチスレッドでその重たい処理を実行すれば、重たい処理を実行しているもののアプリケーションは実行可能(GUIの見た目もアップデート可能)です。ほかの例としては複数のホストから依頼を受けるサーバプログラムがあげられます。そのサーバープログラムがシングルスレッドだと、あるホストから処理のリクエストを受けてからそのレスポンスを返すまでは、別のホストからのリクエストが来たとしても処理できず待たせることになります。一方、マルチスレッドにすればあるリクエストの実行中であっても、別のリクエストを受けることが可能になります。そのため複数のリクエストを同時にこなすことが可能になります。○マルチスレッドの限界マルチスレッドが万能かというと必ずしもそうではありません。なぜならマルチスレッドは計算資源を「分けあって使う」だけであり、計算資源そのものを多く使えるわけではないためです。たとえば、使用しているPCでCPUを100%状態でフル活用すればタスクAを10秒、タスクBも10秒で終わらせられるとします。そのとき、マルチスレッドを使うとタスクAとタスクBを同時に実行できるものの、それぞれにかかる時間が20秒に増えてしまいます。たとえばプログラムの処理がCPUを100%使い切る場合、複数の処理を並列に実行することはできても、その合計処理時間はシングルスレッドと理論上は変わりません。これは処理Aと処理Bを同時に実行する場合、AとBは計算資源を分けあってしまうのでそれぞの処理が終わるのに必要な時間が伸びてしまうからです。このイメージ図を以下に記載します。そのため、何に起因して処理に遅延が発生しているのか把握したうえでマルチスレッドを使うことが望ましいです。昨今はCPUはマルチコアになっているので、CPU依存のプログラムであってもシングルスレッドだとコアをひとつしか使えなかったが、マルチスレッドならコアを2つ以上使えて高速化するというシナリオはあるでしょうが。プログラムが複雑化するという以外にマルチスレッドを使うデメリットはそれほど多くないので、時間がかかる処理が存在するとわかっていれば、最初からマルチスレッドを念頭に入れて設計してみてもいいかもしれませんね。○Pythonでのマルチスレッドの利用Pythonでマルチスレッドを使う方法は主に2つあるのですが、まず「ある関数の処理をマルチスレッドとして呼び出す」という方法について扱います。さっそくなのですが、サンプルコードを書いてみます。インポートしているthredingモジュールのThreadクラスに着目してください。import threading, timedef prints(name, sleep_time):for i in range(10):print(name + ’: ’ + str(i))time.sleep(sleep_time)thread1 = threading.Thread(target=prints, args=(’A’, 1,)) # Initializethread2 = threading.Thread(target=prints, args=(’B’, 1,))thread1.start() # Startthread2.start()これを実行すると以下のようになります。python test.pyA: 0B: 0A: 1B: 1A: 2B: 2まず、上記のプログラムではdef printsにて指定された秒ごとにループを回してメッセージを出力する「関数」が定義されています。この関数がマルチスレッド化する処理の対象です。Initializeとコメントされている箇所で、そのprintsをthredingモジュールのThreadクラスのコンストラクタに関数printsの引数とともに与えています。なお、与える引数についてはタプルとしてまとめています(タプルの最後に , をいれているのはタプルの要素がひとつのときでも必ずタプル型になるようにするため)。ここはタプルではなく、リストでもかまいません。prints関数をprints(’A’, 1)としてマルチスレッドとして呼び出すようなイメージです。そして最後に作成されたインスタンスのstartメソッドでマルチスレッドとして並列に実行させています。これを呼び出すと新しいスレッドを開始して、すぐに次の行の実行に移ります。prints関数を見てもらうとわかるように、通常どおりシングルスレッドで呼び出していれば、まず引数A,1で呼び出し、そのprints関数の呼び出しが「終了」したら再度B,1で呼び出すという動きをします。出力としては、A: 0A: 1…A: 8A: 9B: 0B: 1…B: 8B: 9となりますね。ただ、マルチスレッドの出力を見てもらうとわかるように、1回目の関数呼び出しによる出力と2回目の関数呼び出しによる出力が混じって出力されていることがわかります。これはつまり、1回目の関数呼び出しを実行している最中に2つめの関数呼び出しも実行されているということです。両者の違いを絵にまとめます。○スレッドが終了するまで待機する方法複数のスレッドが連携して動作する場合は「スレッドAはスレッドBの結果を利用する」などといった使い方をすることがあります。この場合、スレッドAはスレッドBが終わるまで「待つ」必要があります。あるスレッドが終わるまで待機するには、そのスレッドのインスタンスのjoinメソッドを呼び出す必要があります。別の言い方をすると、joinメソッドの「呼び出し元」は「joinメソッドのインスタンス」のstartメソッドで呼び出されたスレッド処理が終了するまではjoinメソッドを呼び出した箇所で待ち状態になります。たとえば先程のコードを少し変えて、thread1.start()thread1.join() # WAIT HEREthread2.start()とすると、thread1が終了するまでthread1.join()の箇所で待機するため、thread2.start()はすぐには実行されません。結果としてprint出力はシングルスレッドのときと同じものになります。この「スレッドの待ち」を使って、以下のように「基本はシングルスレッドだが、特定のタイミングのみで複数の処理を走らせる」という方法はよく使われる手法です。複数の時間がかかる処理を実行する必要がある場合はそれらを順に実施するよりも、このように並列に実行したほうが実行時間が短くてすみます。この手法を使って、先ほどの複数のWebページからトップページのHTMLを取得するプログラムを高速化してみます。コメントでStart Threadsとなっている箇所で図の処理2を開始し、Wait Threadsとコメントしている箇所で処理2を待機しています。Threadのインスタンスを作ったタイミングでリストに格納し、待つ場所でそれらすべてに対してjoinを呼び出すという方法ですべてのスレッドが終了するまで待機させています。import threading, time, urllib2def get_html(url):current_time = time.time()response = urllib2.urlopen(url)html = response.read()print(url + ’: ’ + str(time.time() - current_time))urls = [’’, ’’, ’’]threads = []# Start Threadscurrent_time = time.time()for url in urls:thread = threading.Thread(target=get_html, args=(url,))thread.start()threads.append(thread)# Wait Threadsfor thread in threads:thread.join()print(’Time: ’ + str(time.time() - current_time))これを実行すると以下のようになりました。 0.322998046875 0.402767896652 0.848864078522Time: 0.849572896957今までは約1.6秒かかっていたものが、約半分の時間になりましたね。マルチスレッドを使うことでプログラムの実行速度が大幅に向上しました。すべてのスレッドの処理が終わるまでjoinのループで待ちますので、プログラムの実行時間は一番取得に時間がかかったサイトに依存しています。表示結果を見る限り、今回はgoogleのページの取得に一番時間がかかり、プログラムの実行時間はgoogleのページの取得時間とほぼ同じになっていますね。今回は3つのサイトだけでしたが、これが10、20などになってくるとより効果的になります。ただ、ネットワークの帯域幅などがボトルネックになりだすとスレッドを使っても解決できなくなる可能性があります。そのときはthreadpoolなどのテクニックを使って特定個数のスレッドを使いまわしたりするのですが、入門レベルを超えるので割愛します。次回もマルチスレッド処理について解説していきます。クラスの継承によるマルチスレッドの実現や、マルチスレッド特有の難しさ、またマルチスレッド以外の並列処理について扱います。
2016年01月05日
IPA(独立行政法人情報処理推進機構)情報処理技術者試験センターは12月22日、「情報処理の促進に関する法律施行令の一部を改正する政令(平成27年12月22日閣議決定)」に基づき、経済産業省が所管する国家試験「情報処理技術者試験」の受験手数料が改定されたことを発表した。情報処理技術者試験は、情報処理技術者としての知識・技能が一定以上の水準であることを認定している国家試験。情報システムを構築・運用する技術者から、情報システムの利用者まで、ITに関わるすべての人を対象としている。昭和44年から平成27年度までの累計の応募者数は約1840万人、合格者数は約232万人。情報処理技術者試験の受験手数料は、平成9年度秋期試験から「5100円(税込)」とされていたが、経済産業省において、受験者数の動向などを踏まえ、今後も安定的に試験制度を運営する観点から受験手数料の額が見直され、「情報処理の促進に関する法律施行令の一部を改正する政令(平成27年12月22日閣議決定)」により、「5700円(税込)」に改定された。改定された受験手数料の適用時期は、iパス(ITパスポート試験)が平成28年(2016年)4月1日から、iパス以外の試験区分が平成28年度春期試験からとなっている。
2015年12月22日
アールピージー・ラボ(RPGLABO)は11月9日、毎月の従業員への給与支払いデータなどから、マイナンバーの提出と受領を処理できる「マイナンバー収集キット」の提供を開始したと発表した。同キットは、収集のために必要なハードとソフトがすべて一緒になったもので、クラウドシステムなど不要で、初期費用のみで運用できる。大きな特徴としては、既存の業務フローで発生する「当月給与支払いリスト」「当月報酬支払いリスト」「年末調整宛名データ」といった給与関連のデータを、収集キットをインストールしたPCに読み込ませると自動的にQRコードを生成し、マイナンバーを収集する際に、そのデータとマイナンバーを紐付けることができる点が挙げられる。収集担当者は提出された書類をOCRリーダーで読み込むだけで登録できるので、手入力の必要が無い。一方、マイナンバー収集対象者も「通知カード」「マイナンバー付き住民票」などの必要書類をコピーして提出するだけなので、負担が少ないという。価格は160万円(税別)。キットに含まれるものは、マイナンバー収集システムインストール済パソコン(Windows7 Professionalを搭載)、収集アプリ設定済み iPad(iPad mini2 SIMフリー版)、数字(マイナンバー形式)/QRコードの読み取りに対応したOCRリーダー。また、オプションとして、パソコンの設置が難しい営業所など、遠隔地でのデータ収集のために、iPadとOCRリーダーをセットにした追加オプション(価格は25万円)を用意している。
2015年11月10日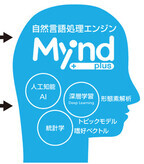
ブレインパッドは10月22日、自然言語処理エンジンの「Mynd plus(マインドプラス)」の提供を開始した。同サービスは、ブレインパッドが提供する「Semantic Finder (セマンティックファインダー)」と、グループ子会社となるMyndが提供する「Mynd Engine (マインドエンジン)」を統合した新サービスで、テキストなどのデジタルデータを独自のアルゴリズムで解釈・処理し、従来人の手で行ってきた業務を「より早く」「より精緻に」処理するほか、人の手では行えない「より高度な」データの処理も実現する。これにより、デジタル・マーケティング領域での活用だけでなく、さまざまなビジネスシーンでの活用が期待できるという。同社は活用例として、Webメディアなどの記事コンテンツに対して「自動タグ付与」や「自動分類」、Webサイト上の類似コンテンツ・類似ユーザーを軸とした「レコメンドコンテンツの抽出」、Webメディアの大量記事や論文などの「自動要約」、コールセンターや相談業務上発生する会話データの「テキストマイニング」、アンケートや口コミのデータなどの「テキストマイニング」などを想定する。
2015年10月23日
腕や脇、脚などのムダ毛処理はきちんとしておきたいですよね。女子力アップのためにムダ毛処理を徹底して行っている人も、意外と見落としているところがあるかも?手や脚などはツルツルでムダ毛の心配はないのに、顔に産毛が…という悲惨な状態になっていませんか? 意外と見ている男性は多く、「他にムダ毛がないからこそ、余計に気になる」と思っているようです。そこで顔の産毛を簡単に処理する方法をご紹介していきます。■産毛のお手入れ方法は?顔の産毛のお手入れ方法はいくつもあるので、自分に合った方法を取り入れましょう。電動シェーバーを使うエステに通うフェイス用の脱毛器を使用する市販のカミソリで剃るもっともキレイに仕上げるには、やはりエステに通うのが1番ですが、お金や時間がネックになりますので、手軽に使える市販のカミソリでの処理方法を解説していきます。 ■フェイス用カミソリでお手軽処理!フェイス用カミソリは、T字タイプ、I字タイプの2つを用意しておくと便利です。また、処理前にはきちんとメイクや汚れを落とすことが大切! 汚れた状態で処理すると、毛穴に雑菌が入りやすくなり、肌トラブルの原因になりかねませんので、しっかりと汚れを洗い落としましょう。顔の汚れを落としたら、蒸しタオルを使って、顔全体を温めます。これは毛穴を開いて肌を柔らかくして処理しやすくするためです。次に美容クリームを顔に塗り、カミソリが滑らかに動くようにします。これは肌への負担を抑える働きもあるので、たっぷりと塗るのがベスト。次に産毛の流れに沿って、ゆっくりとカミソリを滑らせていきましょう。逆から剃ると産毛が目立ってしまうので必ず毛の流れに沿って剃るようにしてくださいね。キレイに剃れたらきちんと洗顔をして、あとはしっかりと保湿して終了です。■産毛をケアするとどんなメリットがある?顔の産毛を処理すると、化粧のノリがよくなり、ファンデーションのもちも良くなります。また、肌が1トーン明るくなる美肌効果も。周りから見ても産毛が生えている顔よりも、きちんと処理されていた方が、清潔感があるでしょう。たくさんのメリットを実感できるので、顔の産毛ケアはしっかりとしておきたいですよね。慣れれば簡単にできるケア方法なので、ぜひ実践してみてください。
2015年10月05日
○GPUは超低速プロセサ図3-28に示したように、GPUは、演算命令を処理するには10~20サイクルを必要とし、ロードストア命令を処理するには400~800サイクル掛かる。仮に、実行する命令の70%が演算命令、30%がロードストア命令とすると、中央値を取って、1命令あたりの平均的な処理サイクル数は15×0.7+600×0.3=190.5サイクルと計算される。そして、クロックが1GHzとすると、1命令を実行するのに190.5ns掛かることになる。一方、IntelのCoreプロセサなどでは、1命令を処理するのに必要なサイクル数は1~2サイクル程度であり、クロックを2.5GHzと想定すると、1命令を実行する時間は0.6ns程度ということになる。つまり、命令の実行時間の比は190.5対0.6で、GPUはCPUと比べると317.5倍遅い超低速プロセサである。そんな物好きな人はいないと思うが、殆ど並列性の無いgccコンパイラをGPUに移植したとすると、この程度の性能比になると思われる。しかし、速度の測り方は色々とある。スポーツカーとバスのどちらが速いかと聞かれれば、普通はスポーツカーと答えるのであるが、50人を目的地まで運ぶ場合はどちらが速いかと言われれば、スポーツカーで50往復するよりも、バスで50人を1回で運ぶ方が速いに決まっている。CPUは、乗客は助手席に1人乗せられるだけであるが、とにかく速く走れるように設計されたスポーツカーであるのに対して、GPUは定員一杯の乗客を乗せた場合に最大の効果を発揮するバスである。そして、バスのメリットをフルに発揮するには、運行する全区間で、満員の乗客を乗せて走る必要があり、これに近い状態で運行することが重要である。そして、乗客として、バラバラのところに行く人を集めてもだめで、まとまって同じ目的地(米国のスクールバスの場合は学校)に行く人を集めなければならない。これをGPUの用語で言うと、並列に実行できる最大スレッド数に近い数の、ほぼ同じ処理を行うスレッドを集めて並列処理を行うことがGPUの効率を発揮するためには欠かせないということになる。
2015年09月25日
野菜が高い時期や買いに行けなかった時のために、市販の冷凍野菜を常備している人も多いでしょう。一方、自分で野菜を冷凍保存しようとする場合、「ゆでるひと手間が面倒だからできない」と思っている人も多いかも。ここでは、そのまま冷凍可能な野菜と冷凍保存するとおいしくなる野菜をご紹介します。○足の早いニラは切って冷凍保存ニラはあまり日持ちがしません。買ってきて冷蔵庫に入れておいても2~3日で使い切るのが理想ですが、すぐに使う予定がない場合は冷凍保存をオススメします。洗って使いやすい長さに切り、よく水を切ってからチャック付きの保存袋やタッパーに入れて冷凍庫へ。○スープや炒め物などの重要な脇役、モヤシもそのまま冷凍にスープや炒め物の具材がちょっと足りない……という時に便利なのが、お財布にも優しいモヤシ。さっと洗って水を切り、保存袋に入れて冷凍保存できます。モヤシのシャキシャキ感が必要な料理には不向きですが、スープやナムルなどを作る場合は、解凍せずにそのまま使うことができます。○きのこ類は冷凍保存で旨みアップ!きのこ類は、冷凍すると水分が凍って体積が膨張します。すると細胞が壊れて旨み成分の元がたくさんでき、その量は生のまま加熱した場合の3倍になるという研究結果もあるぐらいです。エノキなど、冷凍保存に向かない種類もありますが、シイタケやマイタケ、シメジなどは冷凍保存しても食感にあまり差が出ないので、冷凍に向いています。石突 (いしづき) を切り落とし、すぐに使える大きさに分けて保存袋に入れて冷凍庫へ。きのこが多数出回って安くなる時期に試してみてはいかがでしょうか?執筆:山猫軒 (imago)東京都在住。独身。ドラマと読書と食べ飲みが大好き。晩酌は、まず飲みたい酒から肴を決め、1食でも疎かにしたくない食いしん坊です。本稿の内容を実行したことによる損害や障害などのトラブルについて、執筆者および編集部は責任を負うことができません。記載内容を行う場合は、その有効性、安全性など十分に考慮いただくようお願い致します。記載内容は記事掲載日時点の法令や情報に基づいたものです。また紹介されている商品やサービスは、すでに提供が終了していることもあるほか、入手先など記事に掲載されている情報のみとなり、お問い合わせに応じることができません。記載内容を参考にしていただき、ご自身の暮らしにお役立ていただけますと幸いです。
2015年09月24日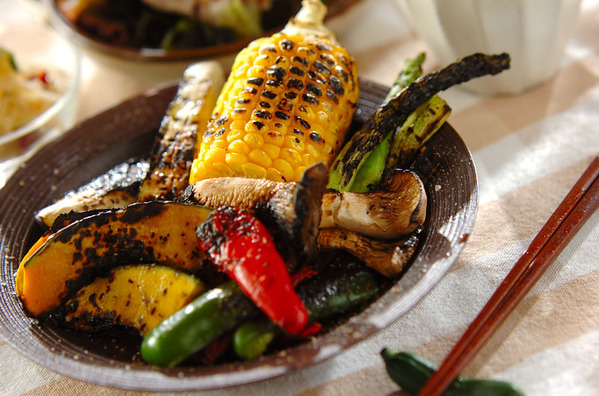
プロの料理レシピサイト「E・レシピ」がご紹介する『今日の献立』は、旬の食材を使った栄養バランスのよい献立メニュー。今夜の夕食にオススメの献立はこちら。今日の献立は「いろいろ網焼き野菜」を含めた全4品。野菜をメインに副菜にはゆでた豚肉と糸寒天を! とってもヘルシーな献立です。 >>今日の献立はこちら いろいろ網焼き野菜野菜が持っているおいしさをシンプルに味わえる一皿です。調理時間:30分カロリー:220Kcal主材料:ナス カボチャ ピーマン 赤ピーマン グリーンアスパラ エリンギ トウモロコシ >>「いろいろ網焼き野菜」のレシピを見る ゆで豚のネギソースサラダ豚肉の甘みとネギソースがよく合います。野菜と一緒に召し上がれ!調理時間:20分カロリー:230Kcal主材料:豚肉 酒 サニーレタス ワカメ 白ネギ 酒 ショウガ >>「ゆで豚のネギソースサラダ」のレシピを見る 寒天とクラゲの酢みそ和え糸寒天とクラゲの食感が楽しい一品。調理時間:15分カロリー:88Kcal主材料:寒天 塩クラゲ キュウリ 油揚げ クコの実 >>「寒天とクラゲの酢みそ和え」のレシピを見る 湯葉とエノキのお吸い物巻き湯葉や折り湯葉……お好みのものでどうぞ!調理時間:15分カロリー:65Kcal主材料:湯葉 エノキ ネギ だし汁 酒 >>「湯葉とエノキのお吸い物」のレシピを見る
2015年08月30日
こんにちは!離乳食インストラクターの中田馨です。「旬のお野菜」ってよく聞きますよね。夏だからこそ美味しい夏野菜を食べてみませんか?今日は、夏野菜の離乳食レシピを紹介します。 旬とは?食材が新鮮に採れて、もっとも食材が食べごろで美味しい時期のことを言います。 旬の野菜のいいところ旬の野菜は、その野菜の一番成長する環境の中で育つので、その野菜が一番成熟している時期と言われています。ですので、旬の野菜は美味しく、栄養たっぷりで、経済的なのです。 離乳食におすすめの夏野菜は?夏が旬の「夏野菜」。その中でも離乳食に使える野菜の一例はこちらです! ■5〜6カ月ごろから食べられるおすすめ夏野菜かぼちゃ、トマト、とうもろこし(トマトは皮を取る) ■7〜8カ月ごろから食べられるおすすめ夏野菜きゅうり、なす、オクラ ■9〜11カ月から食べられるおすすめ夏野菜ピーマン ■1歳〜1歳半ごろから食べられるおすすめ夏野菜枝豆(刻むもしくはつぶして) 夏野菜離乳食レシピ夏の太陽をサンサン浴びた野菜を使った離乳食レシピを紹介しますね。 離乳食後期納豆とオクラのトロトロ和え離乳食後期のメニューです。トロトロ同士を合わせて♡ 離乳食完了期豚肉と夏野菜蒸し離乳食後期におススメなレシピです。夏野菜と豚肉を蒸しただけ、簡単レシピです! 今、スーパーには、年中いろいろな野菜が並んでいるため、旬を感じることが少なくなりましたが、赤ちゃんと一緒に旬を感じながら食べることは素敵なことですね。 著者:離乳食インストラクター協会代表理事中田馨保育士で家庭的保育所経営。一般社団法人離乳食インストラクター協会代表。関東と関西中心に、離乳食インストラクター養成講座やママ向けに離乳食講義・料理教室を開催中。「かおりの“和の離乳食レシピ”blog」では1500以上の離乳食レシピを掲載中。
2015年08月27日
明治はこのほど、野菜をおいしく手軽にとれる「まるごと野菜スープ」シリーズから、「まるごと野菜 韓国風春雨キムチスープ」を発売した。「まるごと野菜スープ」シリーズは、野菜のおいしさが詰まったスープとして、同社が1990年から販売しているロングセラー商品。新商品は、キムチと野菜を魚介のうまみで煮込んだスープで、ピリッとした辛さと、春雨のツルツルとした食感が楽しめるという。ご飯を入れてクッパ風アレンジにして食べるのもおすすめとのこと。袋のまま電子レンジで温めるだけで、簡単に調理できる。カロリーは1食75kcal。価格はオープン。
2015年08月11日
今回はファイル処理をメインに取り扱います。実際の業務で使うアプリケーションやサービスは、なんらかの形でファイルを利用する場合が多いです。たとえばCSV(カンマ区切りの表)を読み込んだり、書き出したり……。また、アプリケーションの状態(設定など)やログを残すためにファイルを利用することもあります。ファイルにはバイナリ(01)で構成される画像ファイルや、テキストで構成されるテキストファイルがあります。バイナリのファイルがどのようなものかについても軽く触れますが、初心者はあまり操作しないと思うので、テキストファイルが話の中心となります。そのため、テキストファイルを扱うために必要なテキスト処理についても扱います。なお、日本語テキストの処理などについては別途扱います。○テキストを生成する方法テキスト処理は要するに、文字列型の処理です。第5回で簡単に扱ったのですが、テキストファイルの処理では文字列型の処理が必須となるので少し発展させて復習します。まず、文字列は以下のように定義するのでした。text1 = ’hello python’text2 = ’’’helloworldpython’’’ひとつめに関しては今さらいうこともないですが、2つめに関しては複数行でテキストをプログラム中で定義する方法でしたね。記号「’」の代わりに記号「"」を使うことも可能ですが、文字列の前後で統一されている必要があります。文字列の結合に関しては「+」記号でできますが、数字などを結合するときは「文字列に変換」してから結合するのでした。ほかの型から文字列型への変換にはstr関数を使います。print(’hello ’ + ’world’)# hello worldprint(’hello ’ + str(5)) # hello 5結合の代わりに、文字列にテキストや数字を埋め込むという手法で文字列を生成することも可能です。>>> ’hello {} {}’.format(’python’, 5)’hello python 5’文字列のformat関数(メソッド)の引数に {} に対応する文字列なり数値なりを与えています。このformat関数の使い方を詳細に伝えるとそれだけで連載2~3回分になってしまいますので、詳しくはこちらのドキュメントをご参照ください。結合より埋め込みのほうがコードがきれいになる場合が多いので、積極的に活用してもらいたいです。文字列のフォーマットに関わるところでは、ほかには数値の整形をしたいことがよくあります。たとえば、1,2……というように連番でテキストを表示なり書き込みする場合、なにも配慮しないと次のように桁数が違うとガタガタになってしまいます。1: some text2: some text……9: some text10: some text11: some text……次のように0で揃えられているときれいですね。01: some text02: some text……09: some text10: some text11: some text……このような場合には以下の方法で文字列の数字に「0詰め」をすると便利です。zfillで桁数を指定したり、先のformat関数に出力の細かい指定をしたりしています。print(’5’.zfill(5)) # 00005print(str(101).zfill(5)) # 00101print(’hello {0:05d} world’.format(5)) # hello 00005 world最後に文字列で使われる特殊記号についてお話します。特殊記号はプログラム中で意味を持ってしまう特別な記号のことです。たとえば「’」という記号は文字列を作成する際に利用する特別な記号です。そのほかにはビープ音なども記号に分類されます。これらは文法的な理由やそもそもそれを表現する記号がキーボードのキーにないことから、「これは XX ですよ」という特別なルールにもとづいて文字列に表記します。そのルールに利用されるのがエスケープ記号と呼ばれるもので半角のバックスラッシュ「\」(英語キーボード)か、半角の円記号「\」(日本語キーボード)を利用します。このエスケープ記号の後に特別な文字を続けることで、それが特別な意味を持つのです。たとえば「’」とビープ音は以下の用に記載できます。print(’escape sample1 \’.’)print(’escape sample2 \a.’)ほかには改行とエスケープ記号自身あたりをよく使います。print(’escape sample1 \n.’)print(’escape sample1 \\.’)エスケープ記号一覧はこちらのページの中央付近に記載されています。なお、記事掲載時から時間が経ってリンク切れしている場合は、適当に検索するなどして調べてみてください。○テキストを加工する方法テキストの生成について取り扱ったので、次はそのテキストを加工する方法について扱います。基礎的な機能を順に紹介していきます。これ以外にも多数の機能がありますが、必要になった時点で調べて覚えていけばよいでしょう。まず、文字列中の「文字」の取得ですが、以下のように [X] で位置を指定して行います。>>> text = ’hello world python’>>> print(text[4])o>>> print(text[100])Traceback (most recent call last):File "<stdin>", line 1, in <module>IndexError: string index out of range>>> print(text[-4])tこの位置の指定はリストの要素の数え方と同じで0から始まります。先頭から0、1、2……と数えていくと4はoに対応していますね。範囲を超えてしまうとエラーになります。面白いのがこの値をマイナスにできるところです。このように指定すると後ろ側から取得してきます。この際、0からではなく-1、-2、-3……とカウントすることに注意してください。文字列から「文字列」を取得するには、以下のように行います。>>> text = ’hello world python’>>> print(text[6:11])world>>> print(text[-12:-7])worldこれは「スライシング」と呼ばれるテクニックで、[X:Y]とあるとXからYまで取得という意味になります。[X:Y] と指定する際はX < Yとなるようにしてください。先ほどと同じように、範囲指定にもマイナス値を利用できます。前と後ろを指定するのではなく、Xより前、Xより後という指定の仕方も可能です。>>> print(text[6:])world python>>> print(text[:11])hello world>>> print(text[:])hello world python見ていただくとわかるように [X:Y] の片方を省略しています。そうすると先頭から、もしくは末尾までという意味になります。あまり使いどころはありませんが、両方とも省略すると、文字列のすべてが取得されます。次に文字列の置き換えです。テキストエディタなどである特定のキーワードを別のキーワードに置き換えることがあるかと思いますが、それと同じ要領です。>>> text = ’hello world python’>>> print(text.replace(’o’, ’0’))hell0 w0rld pyth0n>>> print(text.replace(’world’, ’WORLD’))hello WORLD python>>> print(text)hello world python文字列.replace(置き換える文字列, 置き換えられる文字列)とすると、変換された文字列が返されます。例にもあるように、元の文字列自体は変化していないので注意してください。文字列の検索もそれほど難しくはありません。検索には「存在の確認」と「位置の確認」の2つの使い方があり、それぞれ次のようになります。>>> text = ’hello world python’>>> ’wor’ in textTrue>>> ’w0r’ in textFalse>>> text.find(’wor’)6>>> text.find(’w0r’)-1>>> text.find(’o’)4inについてはlistでの使い方とほぼ同じですね。find については最も左側にあるマッチした位置を返します。そのため、’o’は何個もありますが、一番左の位置となっています。マッチしない場合は-1が返ってきます。それほど使う場面は多くないのですが、前側を指定した数だけ飛ばして途中から検索したり、右側から探索をすることも可能です。>>> text.find(’o’, 10)16>>> text = ’hello world python’>>> text.rfind(’o’)16次に文字列の前後からの特定の文字の削除です。よく利用するのは、前後の空白や改行コード、タブなどを取り除く場合などでしょう。>>> text = ’ hello world \n’>>> text.strip()’hello world’>>> text.strip(’ hell’)’o world \n’strip関数に引数を指定しないと、文字列の前後の空白とタブ、改行が取り除かれます。引数に文字列を指定すると、その文字列が取り除かれます。また、特定の区切りで文字列を分割して文字列のリストにすることも可能です。「,」記号で要素が区切られたCSV(Excel出力)やログの解析あたりでよく使うテクニックです。>>> text = ’1, taro, 35, male’>>> text.split(’,’)[’1’, ’ taro’, ’ 35’, ’ male’]text = ’’’1, taro, 35, male2, jiro, 29, male3, hanako, 23, female’’’for line in text.split(’\n’):elems = line.split(’,’)print(’{} {}’.format(elems[1].strip(), elems[2].strip()))# taro 35# jiro 29# hanako 23分割の逆で文字列を「特定の文字列」で結合していくことも可能です。2次元配列(リストにリストが入っている)に格納された情報をCSV形式でファイルに書き出したりする際に便利な手法です。書式は「結合に使う文字列.join(文字列のリスト)」となります。>>> l = [’1’, ’taro’, ’35’, ’male’]>>> ’, ’.join(l)’1, taro, 35, male’○ファイル処理の概念ファイル処理については、プログラミングというよりも「OSのファイル処理の方式」をまず理解しておく必要があります。そのため、最初にファイル処理の概念について説明します。これがわかってしまえば、その利用はさほど難しくありません。なお、プログラムがどのようにファイルを扱うかは、OSの仕組みにもとづいているため、多くのプログラミング言語でさほど変わりません。ファイル処理がOSにおいてどう実現されているかを抽象化すると以下のようになります。実際はもっと複雑ですが、通常のプログラミングではそこまで意識する必要はないので詳細は割愛します。まずご存知のようにOSにはディレクトリがあり、それが階層構造を作っています。ファイルはそのディレクトリのなかに保存されています。OSはこの階層構造を管理しています。ディレクトリやファイルは、サイズなどの情報と共にポインタのようなものを持っていて、それがファイルの実体を指しています。構造についての話はこれぐらいにして、実際にファイルをどのように処理するか話をしましょう。OSにおけるファイル処理は主に以下のような流れとなります。まず絶対パス(ルートやCドライブなどからのパス)や相対パス(現在いるディレクトリから指し示すパス)を使ってファイルを指定します。それに対して読み、書き、読み書きなどのモードを指定してファイルをオープンします。そして読み書きなどの必要な処理を繰り返し、処理がすべて完了したらファイルをクローズして終わりです。クローズし忘れないようにしてくださいね。読み書きなどの具体的な処理はそれほど難しくありません。一言でいってしまえば、「テキストファイルは行ごとに処理する」「バイナリファイルは先頭から何バイトめか(位置)を指定して処理する」ことです。たとえば、テキストファイルで以下のものがあるとします。worldpythonjavaこの内容にすべて"hello "を加えて画面に表示するというプログラムを書く場合、ループ処理を利用してということを繰り返して処理するのが一般的です。「テキストファイルは行ごとに処理する」のが基本であることを覚えておいてください。次にバイナリファイルです。バイナリファイルは中身が01から構成されているファイルで、一般的には画像ファイルや音声ファイル、それに加えてアプリケーション特有のファイル(たとえば word など)があります。こちらはテキストと違うのでそもそも行という概念がありません。正直なことをいうと、テキスト処理よりもバイナリファイルの処理は骨が折れます(笑)。ただ、ファイルを読み書きできないかというと、そんなことはありません。そのバイナリファイルの構造を知ってさえいれば操作は可能です。著者はビットマップ形式の画像ファイルの合成とWAV形式の音声データの加工の経験があるので、それをベースにしてバイナリファイルの処理についてお話をします。ビットマップは以下の図のように、ピクセルから構成されている画像ファイルです。それぞれのピクセルはRGB(赤緑青)で表現されています。それぞれの色は1バイト(0~255)の容量があるので、ようするに1ピクセルは3バイトです。つまりファイルサイズは「縦のピクセル数×横のピクセル数×3」バイトになります。ここまでわかってしまえば、あとは簡単です。たとえば画像Aに画像Bをオーバーレイ(一部上書き)するとします。この際、Bの画像の黒(RGBが0, 0, 0)は透過させます。すると、以下の図のようにして合成が可能です。Bの左上は黒なのでAのものを合成画像に利用。その右隣は黒ではないのでBのものを利用。その右隣はA……といった感じでどんどん処理をしていくと、最終的に右の図のようになります。これをファイルに書き込めば、自分でバイナリファイルを作ったことになります。次にWAV音声ファイルです。これも比較的わかりやすい形式ですが、先ほどのビットファイルと違って「ヘッダ」と「データ」に分かれています。データは先程のビットマップと同じく音声のデータ(波形)を含んでいるだけなので簡単ですが、ヘッダにはデータをどのように表現するかといった情報が含まれています。後ろのデータを変えれば当然再生される音も変わりますが、その際に必要に応じてヘッダを変更する必要があります。最後にバイナリデータの処理のコツを伝えます。それは「プログラムで処理しやすい生(raw)の形式に一旦戻す」ということです。たとえばビットマップであれば編集は簡単ですが、JPEGやPNGを編集するのは非常に難しいです。そのためまずはJPEG → ビットマップに変換してやり、ビットマップで編集を行った後に再度、ビットマップ → JPEGに変換すればよいのです。音声も同じでmp3を直接編集するのではなく、mp3 → wav → 編集 → new wav → mp3とすればよいです。これらの変換には組み込みもしくは外部のライブラリを使用してかまいません。○実際にファイル処理をしてみよう長くなりましたが、実際に pythonでテキストファイルの処理をどのようにするか紹介します。先ほどの概念さえわかってしまえば非常に簡単です。worldpythonjavaと書かれたテキストファイルtext.txtの各行にhelloを加えて表示するサンプルを書いてみます。f = open(’text.txt’, ’r’)print(type(f))for line in f:print(’hello ’ + line)f.close()まずファイル ’txt.txt’ をモード ’r(読み)’ でオープンしています。オープンしたファイルオブジェクトに対してfor文を使うと1行1行取得できるので、行ごとにprintする処理をしています。これを実行すると以下のような出力となります。<type ’file’>hello worldhello pythonhello javaprint文の改行に加えて、もとのテキストの改行も表示されるので1行スペースがあいてしまっていますね。print文の改行をなくすには以下のようにprint文の後に「,」を書けばよいです。print(’hello\n’),print(’world\n’),ほかにはファイルを丸ごと読む方法もあります。f = open(’text.txt’, ’r’)text = f.read()print(text)lines = text.split(’\n’)print(lines)f.close()ファイルオブジェクトに対してread関数を使うことで、その中身をすべて文字列として取得します。それを行ごとに処理したいのであれば、文字列を先に説明した改行コードで分割することで行ごとのリストになるので、それに対して処理を行うことができます。次に書き込み方法について説明します。書き込みも読み込みと大差ありませんが、ファイルをオープンする際に書き込みモードを指定します。以下のテキストファイルtext.txtに書き込みをするとします。hello書き込みのコードは以下となります。f = open(’text.txt’, ’w’)f.write(’123’)f.write(’456’)f.close()コードを見てもらうと想像がつくとは思いますが、openの第二引数が書き込みモードの ’w’ となっています。そしてファイルオブジェクトにたいしてwriteすることで、実際にファイルに書き込み処理がされています。最後にクローズですね。するとファイル text.txt は以下のようになりました。123456見てもらうとわかるように、もともとのテキストであるhelloが消えていますね。上書きされていることがわかります。ただ、場合によっては「追記(もとの中身を残したまま後ろに加える)」しないといけないこともあります。その場合はモードを ’a’ の「追記」にすれば実現できます。モードのみ修正して以下のコードにしてみます。f = open(’text.txt’, ’a’)f.write(’123’)f.write(’456’)f.close()これを実行すると、123456123456となりました。もとの ’123456’ は残ったままで、その後ろに ’123456’ が新しく追加されていますね。ファイルのオープンごとに以前の内容が消えないので、アプリケーションのログなどを取る際に便利な手法です。なお、書き込みを「次の行」にする場合は「\n」を書き込めばいいです。最後に小ネタを話して終わりたいと思います。ファイル処理をする際に心の片隅においていただきたいのが「バッファリング」という処理です。ご存知かもしれませんが、ハードディスクへのアクセス速度はメモリへのアクセス速度に比べて何桁も遅いです。そのため、ファイルを何度も細かく書くことを繰り返しているとプログラムが非常に低速になってしまいます。この問題を防ぐために、出力があるたびに毎回ディスクに書き込むのではなく、メモリ上の高速な一時領域にデータをおいておき、まとめてそれを書き込むという処理が行われます。こうすることで低速なディスクアクセスの回数が減らせるのでプログラムが高速化されます。これがバッファリングの基本的な概念です。以下にこれを図で示します。このディスクへの書き込みは特定のタイミングで発生するようですが、それを強制的に行いたい場合はflush()関数を使います。f = open(’text.txt’, ’w’)f.write(’123’)f.flush()f.write(’456’)f.close()closeのタイミングで必ず書き込まれるので、今回のようにopenからcloseまで時間が短い場合はflushは不要です。ただ、openしっぱなしで、なかなかcloseしないようなプログラムは適切なタイミングでflush するように心がけてください。でないと、プログラムが強制終了されてしまった場合などに、ファイルに書き込みがされていない可能性があります。以上でファイルに関する基本的な話は終了です。ある特定ディレクトリ配下のすべてのファイルを調べるのに便利なglobや、リソース管理のwith文などもあるのですが今回は割愛します。便利なのである程度レベルがあがったら、ぜひ自分で調べてみてください。○「Pickle」とは最後に「Pickle」についてご紹介します。PickleはPythonのデータをファイルに保存し、それを読み取って復元する目的で使えます。あるアプリケーションで終了時に保持するデータをPicklで保存し、再度開いた際にPickelで読み取れば、前回終了した際の状態に戻すといった使い方ができます。Pickle の使い方はそれほど難しくないので、以下にサンプルを載せます。import picklea = {’hello’:1, ’world’:[1,2,3]}f1 = open(’test.dump’, ’wb’) # WRITEpickle.dump(a, f1)f1.close()f2 = open(’test.dump’, ’rb’)b = pickle.load(f2) # READf2.close()print(b) ## {’world’: [1, 2, 3], ’hello’: 1}まずPickleパッケージをインポートしています。そして書き出すファイルを書き込みモードでオープンし、pickle.dump関数でデータをファイルに書き込んでいます。Pickleで書き込まれるデータはバイナリなので’w’ではなく’wb’でバイナリとしてオープンしています。’w’でもおそらく問題はないと思います。次に Pickleのデータが書き込まれたファイルから中身をロードしてきています。これには pickle.load 関数を使っています。’wb’と同様に、こちらもバイナリの読み込みなので’rb’でファイルをオープンしています。簡単ですね。演習1以下のCSV形式のテキストデータから教科ごとの生徒の平均点を算出してください。text = ’’’lecture\students, 1, 2, 3, 4math, 80, 70, 75, 54english, 60, 80, 90, 80’’’可能なら生徒や教科が増えても対応可能なプログラムにしてください。演習2あるテキストファイルAの内容を読み取り、まったく同じ内容をファイルBに書き出すプログラムを書いてください。演習3演習2で作ったプログラムを改良し、ファイルBに行番号を書き出すようにしてください。ただし、行番号は最後の行の桁数にあるように0詰めしてください。たとえば以下のようになります。abc……ijk……z01 a02 b03 c……09 i10 j11 k……26 z演習4標準入力で入力されたテキストをpickleでファイルに保存してください。そしてそれをロードして、画面に表示してください。さまざまなデータをPickleで保存して、そのファイルを開いて中身を確認してみてください。※解答はこちらをご覧ください。次回は正規表現と日本語の扱いについて解説します。
2015年08月10日
具材たっぷり「まるごと野菜」シリーズに新商品株式会社明治は、野菜をおいしく手軽に摂れる「まるごと野菜スープ」シリーズより、秋冬シーズンに最適な「まるごと野菜韓国風春雨キムチスープ」を、2015年8月10日から全国で発売する。この度、新たに登場する「まるごと野菜韓国風春雨キムチスープ」は、キムチと野菜を魚介の旨みで煮込んだスープで、その野菜の量と種類にこだわり、しっかり野菜が摂れるよう人参や白菜、もやしやワカメが約35g分たっぷり入っている。キムチの辛さと、野菜や春雨のつるつるとした食感の具材に、ご飯を入れればクッパ風とアレンジでき、立派な主食として食べることもできる。エネルギーも1袋75kcalとヘルシーであるため、ダイエット中でも食べ応えのあるメインの食事にすることも可能。充実のラインアップ同シリーズは、野菜のおいしさがぎゅっとつまったスープとして1990年に発売し、20年以上の歴史をもつ“野菜をもっとおいしく、もっと手軽に”をコンセプトにしている商品。「韓国風春雨キムチスープ」が加わり、従来品の「完熟トマトのミネストローネ」、「じっくり煮込んだポトフ」、「チキンと野菜のクリームスープ」、「香ばしきのこの濃厚ポタージュ」、「ゆず胡椒風味和風スープ」の計6品のラインアップで展開する。電子レンジで温めるだけで、手軽に食べることができるため、職場でのランチタイムや、家庭でのプラス1品として、または夜食などにも、最適の商品だ。(画像はプレスリリースより)【参考】・株式会社明治プレスリリース
2015年08月07日
ニフティは8月5日、定期処理の自動実行を指示するサービス「ニフティクラウド タイマー」を提供開始したと発表した。同サービスは、あらかじめ指定した時間に、処理の自動実行を指示するサービス。料金は月2,000円(税抜)から。HTTPリクエストを用いて、任意の処理の自動実行を指示し、数分おきに監視処理を実行したり、毎日決まった時間にログをバックアップするなどのバッチ処理に活用できる。また、ニフティクラウドのサーバーと連携していて、サーバーの起動、停止、再起動、削除、スペック変更、および「カスタマイズイメージ」と「ワンデイスナップショット」の自動実行が可能。指定した時間帯だけサーバーを稼働させたり、定期的にイメージを取得してサーバーをバックアップするといった用途に利用することができる。さらに、IoT/M2Mに最適化された軽量な通信プロトコル「MQTT」に対応し、2015年5月からβ版を提供している「ニフティクラウドMQTT」と組み合わせて利用すれば、IoT化されたデバイスへの定期的なメッセージ発行も可能となる。これまで、サーバー構築などの一連の手順を自動化できる機能「ニフティクラウド Automation」や各種APIの提供を通して、システム担当者の負担軽減と利便性向上に取り組んでおり、今後は、ニフティクラウド タイマーの提供により、システム運用のさらなる自動化を実現するとともに、企業のIoT活用を促進していく。
2015年08月06日
「シャキシャキの美味しいサラダが食べた~い!」と思っても、夏は野菜が傷みやすい季節。すぐにシャキシャキ感がなくなってしまうのが悩みどころですよね。また、生野菜は酵素の力によってアンチエイジング効果が期待できるので、夏は積極的に摂りたいもの。そこで今回は、野菜の鮮度や甘みがアップする「50℃洗い」のテクニックをご紹介したいと思います!「50℃洗い」とは?野菜を50℃で洗うと「ヒートショック」という現象により表面の気孔が開きます。そこに水分が取り込まれることで、しおれて元気がなくなった野菜もみずみずしく蘇るのです。また、酸味が強いものほど甘味が増し、まろやかな味に。お湯で洗うことで、殺菌効果も期待できるというメリットもあります。50℃で洗う方法まず、みなさんに試して欲しいのは、夏野菜を代表するトマト。抗酸化作用が期待できるので、アンチエイジングや生活習慣病の予防にいいそうです。トマトと同じ夏野菜のキュウリ、ピーマン、オクラ、ズッキーニもおすすめですよ!<夏野菜の50℃洗い>野菜がたっぷり浸かるサイズのボールにお湯を入れ、温度を測ります。50℃を確認したら野菜をボールの中に入れましょう。この時に注意したいのが、野菜の表面が空気に触れないようにすること。野菜が浮かばないよう軽く押さえてあげてください。時間は2~3分で大丈夫です。浸けている間に温度が下がることがあるので、温度計を常にチェックするようにしましょう。また、お湯は多めに用意しておくと温度の調整もしやすいので便利です。<葉野菜の50℃洗い>次におすすめしたいのがレタス、キャベツ、ベビーリーフ、白菜などの葉野菜です。葉を一枚づつ丁寧にはがしてから、お湯が入ったボールに入れてあげてください。ベビーリーフは、ネットやザルを使ってあげると便利です。時間は15~30秒が目安。葉の色がワントーン明るくなるのがはっきり見えてきます。<フルーツの50℃洗い>バナナやリンゴ、アボガドは皮のついたまま丸ごとお湯が入ったボールの中に浸けます。イチゴは、表面が傷つかないようにボールの中に入れてください。時間は2~3分が目安。50℃洗いが終わったら、冷水に入れ替えて冷やしてあげると、より甘みが増します。<保存ポイント>50℃洗いした後は、水分をしっかり取ってから冷蔵庫で保存しましょう。生野菜の栄養を丸ごと摂れる!野菜に多く含まれるビタミンやミネラルの中には、加熱に弱いもの、水に溶けやすいものがあります。加熱しないで食べることで、ビタミンや酵素など野菜の大切な栄養素を壊さずに摂り入れることができます。生野菜の酵素を体内にしっかり吸収してあげることは、美容のために欠かせません。また、野菜選びも重要なポイント。殺菌&洗浄を繰り返されたカット野菜や、農薬を使った有害な野菜は控え、栄養価の高い無農薬の野菜を選ぶようにしてくださいね。Photo by 文藝春秋BOOKS50℃洗いの詳しいやり方については『50℃洗い 人も野菜も若返る』という本も出ていますのでぜひ参考にしてみてください。アンチエイジングに役立つ生野菜を美味しく食べる裏技。ぜひこの機会に試してみてくださいね。※参考:『50℃洗い 人も野菜も若返る』平山一政著・文藝春秋刊
2015年08月05日
LINEは30日、同社の子会社であるLINE Payが運営するモバイル送金・決済サービス「LINE Pay」において、一部の決済代行企業における請求処理に不具合が発生していたことが判明したと発表した。決済取引において正しくは「JPY(円)」のところ「USD(アメリカドル)」で請求されていたという。今回の不具合では、2015年7月15日から2015年7月22日の間、一部の決済代行企業を経由する決済取引において、正しくは「JPY(円)」であるものを「USD(アメリカドル)」で請求していた。同期間中にKEB Hana Cardの決済システムを経由し、「LINE Pay」で決済を利用した372名(460件)が該当するとしている。LINEとLINE Payではすでに、該当するユーザーの特定を完了し、30日16時半頃にメールでの一時連絡を実施。該当する可能性があるユーザーにメールの確認を呼びかけている。また、登録した電話番号への連絡もあわせて行い、今後の対応説明を順次していく。「LINE Pay」は、2014年12月より提供開始した「LINE」アプリ上で利用できるモバイル送金・決済サービス。提携する店舗やWebサービス・アプリ内における支払いを「LINE」アプリ上で行うことができる。そのほか、「LINE」アプリでつながっている友人に送金できる機能や、送金依頼をする機能、均等に按分された金額をグループのメンバーに請求できる「割り勘」機能などを搭載している。
2015年07月31日
インテルとマイクロン・テクノロジー(マイクロン)は7月28日、従来のNAND型フラッシュメモリーの1000倍の処理速度を持つ新型半導体メモリーを開発したと発表した。新型メモリーには「3D Xpoint」という技術が使われており、NAND型フラッシュメモリーの1000倍の処理速度に加え、DRAMに比べて10倍のデータ容量を実現したという。年内には一部の顧客向けにサンプル出荷を開始する予定。両社は、新型メモリーによって大量のデータへのアクセスおよびその処理が高速化されることで、金融詐欺の早期発見や、医療分野におけるリアルタイムでの疾病追跡などが可能になるとしている。
2015年07月29日
日本電気(NEC)は21日、従来比で約1/2のデータ処理量を実現した認証暗号技術「OTR」を発表した。データ処理性能に制約がある機器をIoTでつなげる際、データ送受信時の処理量を約1/2に低減しながら、セキュリティの高い認証暗号を行えるとする。通常、「暗号化」と「認証」のデータ処理は別々に行う必要があり、「認証」には「暗号化」と同程度のデータ処理量が必要となる。このため、認証暗号のデータ処理量は「暗号化」のみの場合と比べほぼ2倍で、対応機器の処理性能も2倍必要となり、認証暗号の利用が困難となっていた。OTRは、固定長のデータで暗号化を行う既存の暗号化方式「ブロック暗号」を用い、暗号化と認証を効率良く行なう独自の認証暗号技術。ブロック暗号の適用法を工夫して暗号化と認証用タグ生成の処理を共通化し、データ量を従来から約2分の1程度に低減した。また、並列処理によるデータ処理の高速化も可能で、受信時の復号処理ではブロック暗号の「暗号化関数」を用い「復号関数」が不要となるため、小型センサや機器への実装性を向上させている。同社は今回発表したOTRと、米国政府の標準暗号化方式としても採用されている暗号方式AESを組み合わせた「AES-OTR」で、次世代認証暗号が決定される技術審査会「コンペティションCAESAR」の第1次選考を通過したことも、合わせて発表した。
2015年07月21日
今、何かと注目されている「野菜氷」って知っていますか?健康や美容のためにもたっぷり採りたい野菜。でも、火を通して料理するよりももっと簡単に野菜を採れるのが、「野菜氷」なのです!野菜氷とは、野菜をミキサーでくだいてピューレ状にして氷にさせたもの。これは、料理研究科の村上祥子さんが考案したものなんです!村上さんがとくにオススメしている野菜は、たまねぎ氷。血管年齢が若くなり、1日2個のたまねぎ氷で若さと健康を維持する効果が得られるんだとか。糖尿病歴が長く、毎日血糖値を計れる方数名に試験的に食べ続けていただきました。その結果、考案者の私が驚くほど、血糖値が下がり、数値も安定しました。こうして効果が裏づけられ、「たまねぎ氷」が誕生したのです。きっかけは糖尿病でしたが、たまねぎは血圧を下げる、ガンを予防するなど効果は多岐に渡ります。まさに食べる万能薬です。出典:空飛ぶ料理研究科村上祥子のホームページよりその他にも、リコピンがたくさん含まれているトマトや、食物繊維が多いだいこん、腸内環境を整えてくれるしいたけなどなど…何で作っても美味しそうですね。野菜氷なら、夏バテで食欲がないときでも気軽に口に入れる事ができますし、時間がないときもすぐに栄養を採ることができます。つくり方はとっても簡単!●野菜を適当な大きさにカットする●レンジで加熱する●水を加えてミキサーにかける●容器に移して冷凍庫で凍らせるストックが一気に作れて、保存期間が長いのも嬉しいポイントですね。健康にも美容にも良い野菜氷。この夏、試さないわけにはいきません!
2015年07月21日
ドイツのフランクフルトで開催中のISC 2015において、ビッグデータ処理の性能を測定するGraph500ベンチマークで、理化学研究所 計算科学研究機構(理研AICS)の京コンピュータが1位となったことが発表された。これは、科学技術振興機構(JST)の戦略的創造研究推進事業CRESTの九州大学(九大)の藤澤克樹教授の率いるグループの成果である。このグループには、九大の他に、東京工業大学(東工大)、京コンピュータを運用している理研AICS、京コンピュータを開発した富士通などが含まれている。京コンピュータは、2014年6月のGraph500で1位となったが、2014年11月のGraph500では米国ローレンスリバモア研究所のSequoiaに抜かれて2位に後退していた。それを今回、アルゴリズムの改良で処理データ量を減らして約2倍という性能向上を達成し、1位に返り咲いたものである。Graph500では、例えば、1億2000万人の日本人が、1日平均16回通話したとする。そして、誰から誰に通話したかという1億2000万×16=19億2000万件の通話記録を入力データとして受け取る。そして、1人の人から、通話のあった人をすべて見つけ、次に、それらの人と通話のあった人をすべて見つけ、さらに、それらの人と通話のあった人全員を見つけるということを繰り返して、通話記録に含まれるすべての人を出来るだけ短い繰り返し回数で見つけるというビッグデータの問題を解く。また、Twitterの個々のフォローの集合を入力として、1人の元となる発言者から、第1次のフォロワー、第2次のフォロワーというようにたどって行って、何ステップで何人にたどり着けるかという解析も同様の処理である。このような解析から通話やフォローの多い人のグループを見つけ出すというように、関係性の高いものを見つけ出すことができる。しかし、入力データが膨大なので、京コンピュータの場合は82,944台の計算ノードに分散してデータを配置する。このため、計算ノード間で多くの通信が必要となり、高い処理性能を実現するのが難しい問題である。このデータは、人間と人間を通話という関係でつないだ形になっており、グラフの世界では、人間をノード、1回の通話をエッジとして表す。今回、京コンピュータが解いた問題は、2の40乗ノード(約1.1兆ノード、前の1億2000万人の通話の例のおおよそ1万倍のデータ)、17.6兆エッジのグラフを調べるものであり、38621.4GTEPS(Giga Traversed Edge Per Second)、毎秒38兆6214億エッジの接続を調べるという処理速度を達成して1位となった。なお、2014年11月には、Sequoiaが23751GTEPSで1位、京コンピュータは19585.2GTEPSで2位となっていたが、今回は、京コンピュータが38621.4GTEPSと性能を伸ばしたのに対してSequoiaは前回のスコアに留まっており、京コンピュータが再びトップに立った。
2015年07月14日
情報処理推進機構(IPA)の情報処理技術者試験センターは7月13日、「平成27年度秋期情報処理技術者試験」の受験申込みの受付を同日より開始したと発表した。情報処理技術者試験は、経済産業省所轄の国家試験で、情報処理技術者としての知識・技能が一定以上の水準であることを認定するもの。情報システムを構築・運用する技術者から、情報システムの利用者まで、ITに関わるすべての人を対象としている。試験は、春期・秋期の年2回実施されており、平成27年度秋期試験は2015年10月18日に実施される。申込み受付期間は、インターネット申込みの場合が7月13日10時~8月21日20時で、願書郵送申込みの場合は7月13日~ 8月10日(消印有効)。受験手数料は各区分の試験のいずれも5,100円(税込)となっている。
2015年07月13日
プログラムの基本的な流れは上から下へ一行ずつ実行していくというものです。単純なプログラムですと、テキストファイルに実施する処理を順番に羅列するだけで実現できます。いわゆる「バッチ処理」と呼ばれているやつです。ただ、複雑なプログラムだと、このような「上から下に順番に実行していく」というスタイルだけでは処理を実現できなくなってきます。たとえば、天気予報を確認するアプリケーションでは、「今日が晴れなら晴れマークを表示、雨なら雨マークを表示」といった具合に「あるものがAならBをする。そうでないならCをする」という処理が必要になってきます。「条件」に応じて処理が「分岐」しているので、こういった処理のことを「条件分岐」といいます。ほかには、同じ処理を何度も繰り返す「ループ処理」があります。たとえば、「クラス全員のテストの平均点を求め、その平均点と各生徒の点数の差分をチェックする」といった場合を考えてみましょう。平均を求めるには「生徒の点数の合計/人数」とする必要がありますが、この合計を求めるために「先頭の生徒から最後の生徒まで順番に点数を足していく」という「繰り返し(ループ)」が必要となります。平均との差分の算出も同様です。今回はこのような条件分岐やループ処理といった「プログラムの制御構造」について取り扱います。これらの処理を使うこと自体はそれほど難しくないので、何度も書いて慣れてしまえば、簡単に使いこなせるようになるはずです。なお、今までの記事ではプロンプトベースで説明を進めてきましたが、コードが長くなりはじめたのでプログラムファイルで実行することを前提に解説します。IDLEのエディタで書いてF5(MacはFn + F5)で実行するなり、pythonコマンドで実行するなりしてください。○条件分岐さっそく、最も使われる制御構造のひとつである「条件分岐」について学んでいきましょう。条件分岐は、条件分岐の式を満たすか満たさないかで実行される処理が変わるという制御構造です。型について取り扱った際に紹介した「Bool型」が条件判定に利用され、その値がTrueかFalseかで実行するプログラムが変わります。以下に条件分岐の仕組みを図で記します。上記の図のうち、「elif」は任意の数(0も含む)繰り返すことができ、「else」も省略することができます。elseがないときは、どの条件にも合致しない場合は何もしないということです。Pythonのプログラムでは以下のように書きます。if(条件A):処理1-1 # 条件 A が True の時に実行される処理処理1-2elif(条件B):処理2 # 条件 A が False で条件 B が True の時に実行される処理elif(条件C):処理3 # 条件 A,B が False で条件 C が True の時に実行される処理else:処理4 # 全ての条件が False の時に実行される処理上記のifからelseの次の行までがひとつの「if文のカバー範囲」であり、そのなかにあるifやelif、elseが細かい処理の単位だと思っていただければ大丈夫です。上記のプログラムには「if、else、elifのあとの処理が字下げ(インデント)されている」という規則性が見えますね。このインデントされている場所は「コードブロック」と呼ばれるもので、同じインデントのレベル(深さ)で揃えると同じコードブロックに属しているとみなされます。なんだか難しいようですが、ようするに上記のif文でいうと「処理1-1、1-2はif(条件A)のカバー範囲」であるということです。同様に処理2は「elif(条件B)」の範囲であり、処理3は「elif(条件C)」、処理4は「else」の範囲です。実際に条件分岐を行うプログラムを書くことで、条件分岐の使い方をイメージしてみましょう。プログラムは非常に簡単で、変数xの値が0より大きければ「+」と出力し、ピッタリ0なら「0」と「Zero」、0未満なら「-」と出力するというものです。これは以下のようになります。x = 5if(x > 0):print(’+’)elif(x == 0):print(’0’)print(’Zero’)else:print(’-’)繰り返しになりますが「print(’0’)」と「print(’Zero’)」は同じコードブロックです。上記プログラムをIDLEのエディタに書いて実行してみてください。xに5が代入されているので、「+」と出力されたはずです。これはx < 0の条件式が満たされ(Trueとなり)、「print(’+’)」が実行されたからです。このxに代入する値をいろいろ変えて動かしてみると、どの条件式がチェックされ、「if、elif、else」のどの処理が実行されたのかイメージできるはずです。○コードブロック条件分岐の話が終わったので、インデント(字下げ)についてもう少し詳しくお話しましょう。先ほどのプログラムは最初から最後までif文でしたが、実際には、if文は多くの処理のなかに埋もれるかたちで処理します。すると、ifなどの制御構造が「どこからどこまでをカバーしているか」をどのような形で表現するかが問題になってきます。たとえば、処理1、2、3、4、5とあるなかで条件Aを満たす場合のみ処理2、3を実行し、満たさない場合は4を実行するとした場合、どのように表現すればよいでしょうか。勘のいいかたなら気が付かれたかもしれませんが、インデント(字下げ)をすることでこれを実現しています。処理1if(条件A):# ここから処理2処理3# ここまでがコードブロックelse:# ここから処理4# ここまでがコードブロック処理5字下げをすることでコードブロックを表現する。簡単ですね。なお、CやJavaにもコードブロックはありますが、その書き方は異なっています。たとえばJavaだと上記のサンプルコードは以下のようなものとなります。処理1if(条件A){// ここから処理2 // 字下げは必須ではない処理3// ここまでがコードブロック}else{// ここから処理4// ここまでがコードブロック}処理5{}で囲むことでコードブロックを表しています。たいていは読みやすいように上記のようにインデントをしますが、プログラムとしてはインデントをする必要性はありません。コードブロックはifやループなどの制御構造だけではなく、関数やクラスでも利用されます。なお、Pythonのインデントの仕方は「半角空白を2つまたは4つ」が普通だと思います。自分や属するプロジェクトのコーディング規約次第があればそれに従ってください。○コードブロックのネスト(入れ子)コードブロックの中にコードブロックを作ることも可能です。たとえば条件分岐の中に、さらに条件分岐を作ったりすることもできます。書き方は簡単で、コードブロックの内側にさらにコードブロックを作るというものです。その際、内側のコードブロックは外側のコードブロックに属しています。サンプルコードをあげてみます。if(条件A):処理1 # "if(条件1)"のコードブロックに属するif(条件B):処理2 # "if(条件1)" と "if(条件2)" の両方法のコードブロックに属する処理3else:処理4処理1、2、3はすべて「if(条件1)」のコードブロックに属していますが、処理2だけではそれに加えて 「if(条件B):」にも属しています。そのため、処理2が実行されるのは条件A、Bが共にTrueのときのみです。たとえ条件BがTrueであっても、条件AがFalseなら処理2は実行されません。なお、コードブロックに限らず、プログラミングで「入れ子」構造にすることを一般的に「ネストする」と言いますので覚えておいてください。ネストすること自体には問題はありませんが、その深さが増えてくるとプログラムが非常に読みにくくなります。深いレベルのネストが必要な状況になってきたら、アルゴリズムそのものを見直すか、後の連載で扱う「関数」に処理を分割することで読みやすくすることが多いです。○ループ処理次に、別の制御構造であるループ処理について扱います。ループ処理はその名前からわかるように「同じ処理を何度も繰り返す」という処理です。ループ処理の制御構造にはforとwhileの2つがあり、両者の使うべきポイントは若干異なっています。そのため、それぞれ別に説明します。for「for」は「グループにある要素すべてを処理する」といったときに使われるループ構造です。一番よく使われるのが、前回お話したリスト(配列)に格納されている要素すべてをチェックするような処理です。JavaやCで使われるfor文と書き方はかなり異なるものの、ほとんど同じような場面で使います。Pythonのfor文のイメージを以下の図に書きます。難しい用語でいうと「イテレーター」と呼ばれる処理方式なのですが、ようするに「たくさんある集合の先頭ひとつを取り出して、それを処理する。それが終わったら、次を取り出して処理をする」ということを、集合が空になるまで繰り返すというイメージです。それほど難しくないので例で示しましょう。1、2、3、4、5という数字が格納されているリストの中身を一つひとつすべてprint出力する処理をforで書くと以下のようになります。a = [1,2,3,4,5]for i in a:print(i)1、2、3、4、5という集合から、リスト a から 1 を取り出して i に格納。それをprint出力リスト a から 2 を取り出して i に格納。それをprint出力…(中略)…リスト a から 5 を取り出して i に格納。それをprint出力リスト a からすべてを取り出したのでforのコードブロックを終了という動きをします。すでに想像はついているかと思いますが、出力は以下のようになります。12345イテレーターを使っているので、Javaのfor文で使うような「インデックス(配列の何番目か)による制御」に比べて、間違った要素を指定するリスクが減っています。whilewhileもforと同じくループ処理のための制御構造です。ただ、whileは「ループを何周すればいいかわからない処理」に利用されます。先ほどのforの例を思い出して下さい。forでのループ回数は「リストaに格納されている要素の数」と明確にわかりますよね。このような場合はforで処理すべきです。一方、たとえば「123456789という数字を2進数で表現するのに必要な桁数を求める処理」が必要だとした場合、これをどうfor文で処理すればいいか、想像できますか。私はシンプルでスマートな実装は思いつかないです。解き方はいろいろあると思いますが、一番簡単な解法の一つとして、以下のようなものが考えられます。2 の 1 乗は 123456789 より大きいか-< No2 の 2 乗は 123456789 より大きいか-< No..2 の N 乗は 123456789 より大きいか-< No2 の N+1 乗は 123456789 より大きいか-< YESN+1桁あれば 123456789 を表現可能だとわかるこの処理では2を1乗、2乗とループ処理でどんどん大きくしていきますが、最終的に2の何乗になるかがわかりませんよね。このようなときに「特定の条件をクリアするまでループを回す」ためにwhileを使うと便利です。以下にwhile文の使い方のイメージ図をのせます。上記の図を見てもらうとわかるように、while文はループを回るごとに条件式をチェックして、それがTrueならループを継続して、Falseならループを抜けるという処理をします。これはJavaやCのwhileとまったく同じです。先ほどの2進数の桁数を求めるプログラムをwhileで書いてみます。a = 123456789i = 1while(2**i < a):i+=1print(i)すでに扱った内容ですが、上記のプログラムを補足すると、2**iは「2のi乗」を計算していて、i+=1はiをインクリメント(i = i + 1)しています。2**iが123456789より小さい間はiをインクリメントしていき、2**iが123456789より大きくなったらループを抜けるという動きをします。ループを抜けた際iに入っている値が必要な桁数を表しています。○break と continue制御そのものの打ち切りや「ループのその回だけ」の打ち切りが必要な場面があります。たとえば以下のようなプログラムがあるとします。a = [1,3,5,7,9,10,11,13,15]has_even = Falsefor i in a:if(i%2 == 0):has_even = Trueprint("List has even: " + str(has_even))偶数がリストの中にあるかどうかをチェックしていますね。リストの中に10があるので、当然Trueとなります。ただ、よく考えてみてください。なにか無駄な処理があると思いませんか。そう、ループが10になった回で偶数があることがわかったのに、さらにチェックを繰り返しています。10が現れた時点で偶数があることはわかりきっているので、ループを回し続けるのは無駄なのです。「break」を使って処理を打ち切ることで、この問題を解決できます。a = [1,3,5,7,9,10,11,13,15]has_even = Falsefor i in a:print(i) # NEW CODEif(i%2 == 0):has_even = Truebreak # NEW CODEprint("List has even: " + str(has_even))確認のためにbreakだけでなく、print文も追加しています。これを実行すると以下のようになります。1357910List has even: Trueどうです、11以降のチェックをしなくなりましたよね。このようにbreakはかなり使える処理なので覚えておく必要があります。一方「continue」ですが、正直こちらはbreakほど頻繁に利用されない気がします。ただ、ループで「特定の条件の場合だけ処理をしたい」というときに利用されることが多いです。たとえば、数値1から99のリストのうち、3でも5でも割り切れるものだけを画面出力する必要があるとします。リストを使わないで愚直な書き方をすると以下のようになります(実際はcontinueを使わなくとも、もっとスマートに書けます)。a = []for i in range(1,100):if(i%3 == 0):if(i%5 == 0):print(i)range関数は第一引数(1)から第二引数(100)のひとつ前までの数値のリストを作成する関数です。もし、iが3で割り切れたら、もしiが5で割り切れたら……などというように条件分岐がどんどん深くなってしまいます。これをcontinueを使って書き直すと、次のようになります。a = []for i in range(1,100):if(i%3 != 0):continueif(i%5 != 0):continueprint(i)行数は増えてしまいましたが、プログラムの見渡しはよくなりましたね。このように使いようによっては、breakとcontinueは便利です。個人的に私がよく使うのは「whileの条件判定にTrueをいれた無限ループ」をbreakで抜けるというものです。たとえば以下のような構造です。while(True):処理if(条件):処理break処理気をつけないと無限ループから抜けられなくなりますが、適切に使えば、きれいなコードが書けます。演習1[[1,5,3], [2,6,4]] は、リストにリストが入っています。内側のリストの最大値をそれぞれ求めるプログラムを書いて下さい。演習21から100までの整数で3の倍数の時は Fizz5の倍数の時はBuzz3の倍数でもあり5の倍数でもあるときは FizzBuzzと表示するプログラムを書いて下さい。※解答はこちらをご覧ください。次回はモジュールや関数について扱います。よろしくお願いします。
2015年06月29日
薄着必須のこれらからの季節、ムダ毛処理は避けて通れません。みなさんは腕や脚、わきなどのムダ毛、どうやって処理していますか?今回はムダ毛処理でよくおこなう「抜く」と「剃る」どちらのほうが肌に優しいのかを、美容ライターの大野えりかが紹介いたします。■ムダ毛処理が与える肌ダメージまず知っておいてほしいのは、むだ毛処理はどうしたって肌に負担をかけてしまうのだということ。肌に負担がかかることで日々ケアしている自慢の腕や脚が炎症を起こしやすくなり、見た目や触り心地まで変えてしまうことにもつながります。「抜く」と「剃る」の場合、実は「抜く」ほうが肌へのダメージが大きくなります。というのも、「抜く」という行為は肌の一部をちぎっていることになるからです。■抜く痛みは細胞が切り裂かれておこる!毛を抜くときチクッとした痛みを伴いますが、この痛みは細胞が切り裂かれる痛みだと言われています。毛根にある毛母細胞は周囲の血管から酸素や栄養をもらって成長しているため、「生きた細胞」ということになります。生きた細胞を傷つけるのですから、痛みを伴うのは当然のこと。そして、毛穴の奥ではちょっとした出血もしているのです。毛を抜いたあとに炎症を起こしたり、場合によっては膿んだりシミになったりするのはそのためです。■剃るならT字型のカミソリでオススメしたいのはT字型のボディ用カミソリです。電気カミソリは深くカットできる分、一見キレイに剃れたように感じるのですが、毛穴の中の毛を巻き込みながらカットするため、どうしても皮膚表面まで一緒にカットしてしまいます。それに比べ、T字のカミソリであれば自分で力加減ができるため、毛穴を傷つけることもありません。■ムダ毛処理によるダメージを減らすには?ムダ毛処理はどうしたって肌に負担をかけてしまうとお話しましたが、その負担をできるだけ軽くする方法があります。1.ムダ毛処理はお風呂あがりに皮膚は温度が下がると毛穴が閉じ、硬くなってしまいます。そこで、お風呂上りで肌が柔らかくなっている状態で行うのがおすすめ。また、ムダ毛処理をする際は肌を清潔にし、傷口から雑菌が入るのを防ぐ必要があります。処理する部分はボディソープで丁寧に洗っておきましょう2.ムダ毛処理後はクールダウン処理後は肌に負担がかかっていますし、除毛方法によっては内部で出血が起こっていることも。そのため、水で冷やしたタオルをあてるなどして、ムダ毛処理による炎症をおさえましょう。3.生理中、体調不良のときはやらない体調がわるいときは肌の免疫力が下がり、肌トラブルがおこりやすい状態になっています。こうしたタイミングで起こる肌トラブルはを治りが悪く、いつまでも炎症によるブツブツやシミが残ってしまうことにもつながります。これは「剃る」に限らず、抜いたり、除毛クリームを使う場合にも共通するムダ毛処理時のお約束です。■おわりに肌をきれいに見せるためにおこなっているムダ毛処理なのですから、肌になるべく負担をかけない方法を選びたいですよね。彼と腕が触れ合ったとき、「スベスベだね」と言われる肌を目指して、ムダ毛処理を行ってみてはいかがでしょうか。(大野えりか/ハウコレ)
2015年06月25日
料理の基本のひとつとも言える、野菜炒め。これが上手だと、格段に料理上手に見えるはず。今回はキャベツを使った、いつもよりもちょっとハイグレードな?野菜炒めレシピをご紹介します。教えてくれたのは、瀬尾幸子さんです。和洋中どんな味付けにも合って、じっくりと火を通すことで甘みとうまみが増すキャベツは、まさに炒め物にぴったりの野菜。「1/4個で2人分が目安。一番外側、真ん中のあたり、芯の部分と3層くらいに分けると切り揃えやすいですよ。芯の堅い部分はそぎ切りに。炒める時は芯も葉もすべて一度にフライパンに入れてOKです」(料理人の瀬尾幸子さん)手軽なのに技ありな、キャベツ炒めレシピはこちら!■チーズでコクをプラスキャベツのペペロンチーノ風【材料】(2人分)キャベツ…小さめ1/4個ベーコン…2枚オリーブオイル…大さじ2にんにくのみじん切り…1かけ分赤唐辛子輪切り…少々塩…小さじ1/2こしょう…少々粉チーズ…大さじ3【作り方】(1)キャベツは4cm角に、ベーコンは1cm幅に切る。(2)フライパンにオリーブオイルとベーコン、にんにく、唐辛子を入れて中火にかけ、香りが立ったらキャベツを入れる。(3)絶えず全体を混ぜながらキャベツが柔らかくなるまで3分ほど炒め、キャベツに火が通って食べられるくらいの状態になったら、塩、こしょうを加える。(4)器に盛り、粉チーズと、好みでオリーブオイル(分量外)をかける。■キャベツがフランス風に?シュークルート風キャベツ炒め【材料】(2人分)キャベツ…小さめ1/4個ウインナソーセージ…4本オリーブオイル…大さじ2塩…小さじ1/2こしょう…少々粒マスタード…大さじ1パセリみじん切り(あれば)…少々【作り方】(1)キャベツは2cm幅の短冊に切る。ウインナソーセージは斜めに薄切りにする。(2)フライパンを熱してオリーブオイルをひき、(1)を中火で炒める。キャベツの水分を飛ばすように、ゆっくり3分ほど炒める。(3)塩、こしょう、粒マスタードを入れて炒め、器に盛って、あればパセリをふる。◇フランスの郷土料理、シュークルート風のキャベツ炒め。◇チーズでコクをプラスキャベツのペペロンチーノ風◇瀬尾幸子さん料理人。コツをわかりやすく解説したレシピが好評。本誌の連載「Cooking」では「やさしい和食」を担当。著書に『ラクうまごはんのコツ』(新星出版社)。※『anan』2015年6月17日号より。写真・津留崎徹花スタイリスト・矢口紀子取材、文・新田草子
2015年06月12日
キリンビバレッジは「おいしく地産全笑。プロジェクト」を指導し、第1弾商品として「キリン おいしく地産全笑。世界一の九州・沖縄をつくろう。野菜 100/野菜と果物」を、7月7日より全国で発売する。希望小売価格は150円(税抜)。ちなみに同社の「おいしく地産全笑。プロジェクト」は、「地域のおいしいを見つけてニッポン中で楽しむ、おいしい地産全消」がコンセプト。地産品を商品化し、地域経済・農業経営に貢献していくことを目指しているという。また両商品とも、にんじん汁をベースに、九州・沖縄各県の野菜をブレンドしており、「野菜100」は九州・沖縄の野菜汁を100%使用した野菜ジュース、「野菜と果物」は柑橘が香る野菜と果物のジュースとなっている。
2015年06月01日
みなさん、野菜の下ごしらえ、どうしてますか? 筆者は、料理を作るのも食べるのも大好きです。レシピ本やレシピサイトを活用して、日々レパートリーを増やすことにいそしんでおります。「時短」や「簡単」は、大好きなワードです。基本的に筆者の料理は、母や祖母が教えてくれた「感覚」や「味」が頼りなのですが、最近のレシピ本を見ながら不思議に思うことがあるんです。それは、野菜の下ゆでの過程が書かれていないこと。基本的なことだから、わざわざ書く必要がないのかもしれないのですけど。○手間を惜しむか、時間を惜しむか野菜の下ゆでをするのは、苦味やえぐみなどの灰汁 (あく) を取るためです。この苦味やえぐみ、野菜が動物などから身を守るための成分。野菜の灰汁が美味しくないのは当然。おいしさを求めるなら、多少手間でも下ゆでしましょう!今回は大根をおいしくするための、筆者ならではの下ゆで方法です。大根を下ゆですると、大根に含まれるアミラーゼ (ジアスターゼ) という成分と、米のとぎ汁に含まれるでんぷん質の相互作用によって糖になり、おいしさが増すのだそうです。また、より白くなり、味も染み込みやすくなります。大根の下ゆでは、大根をコメのとぎ汁で柔らかくなるまで行います。時間があれば粗熱を取ってから調理に入ります。下ゆでのプロセスは簡単なのですが、少し時間がかかります。下ゆでした大根は、出汁 (だし) の味がよく染み込み、大根の風味や甘みを感じられとてもおいしくなります。一方、下ゆでしていない大根は、やはり苦味やえぐみが気になります。まず、お鍋にお米のとぎ汁と大根を入れ、火にかけて沸騰させます。続いて、流行の真空保存鍋で保存します。保存時間の目安は、「竹串がスッと入るようになるまで」(15~20分くらい) です。火のそばにいなくていいから、とっても便利。竹串がスッと入るようになったら真空保存鍋から大根を取り出して、粗熱をとります。粗熱がとれたら大根をザルにあけ、サッと洗います。確かに、白く透き通っていてキレイです。そして、ここから調理を始めます。下ゆでした大根を冷凍保存する時は、軽く水気を拭きとり、保存袋に入れて冷凍庫へ。冷凍すると、次回煮物を作る時に一層味が染み込みやすくなります。口の中でとろけますよ。やっぱり下ゆでは大事です!執筆:きゅう趣味はドライブと映画鑑賞。女子力が低めなアラフォー。遊びに全力を傾けるも、時間が足りないのが悩み。現在は人間観察にハマっている。本稿の内容を実行したことによる損害や障害などのトラブルについて、執筆者および編集部は責任を負うことができません。記載内容を行う場合は、その有効性、安全性など十分に考慮いただくようお願い致します。記載内容は記事掲載日時点の法令や情報に基づいたものです。また紹介されている商品やサービスは、すでに提供が終了していることもあるほか、入手先など記事に掲載されている情報のみとなり、お問い合わせに応じることができません。記載内容を参考にしていただき、ご自身の暮らしにお役立ていただけますと幸いです。
2015年05月23日
日本オラクルは5月11日、東京電力がスマートメーターから取得するデータの高速処理IT基盤に、オラクルのデータベース・マシン「Oracle Exadata Database Machine」を導入し、稼働開始したと発表した。東京電力は、2014年4月よりスマートメーターの導入を開始し、2020年には2700万台に達する見込みだという。また、2015年2月1日より東京電力多摩支店サービスエリアのスマートメーター約14万台を対象に新システムの稼働を開始しており、段階的に拡大している。今回、これらスマートメーターから取得する検針値などのデータを収集管理するIT基盤として、スマートメーター運用管理システムを構築することが決定。東京電力はハードウェアとソフトウェアが最適に稼働するよう設計されたエンジニアドシステムズの活用により、導入作業開始から1年未満でシステムの稼働開始を実現したという。東京電力は、信頼性と拡張性の高いスマートメーター基盤の実現により、今後、顧客の使用形態に応じた多様な料金メニューの設定、よりきめ細かな省エネ支援などに取り組んでいく。
2015年05月11日
ON Semiconductorとオーディオ技術企業のAfterMaster HD Audio Labsは、共同でオーディオ向けデジタル信号処理(DSP)チップ「BelaSigna 300R AM」を開発し、発売を開始したと発表した。同製品は、1.8V電源で4mA動作が可能なほか、リアルタイムのマスタリング/リマスタリング処理技術、独自のAdaptive Intuitive Responseメカニズムを使用して原音の品質を維持するとともに、あらゆるリスニング体験にこれまで以上に奥深く明瞭で豊かな音質を提供するAfterMaster HDのアルゴリズムを実行することで、テレビ、ヘッドフォン、スピーカー、携帯端末、ストリーミングサービスなどをはじめとするオーディオ機能を備えた機器やサービスに対して高音質のハイファイサウンドを提供する。また、小型のWLCSPパッケージを採用しているほか、低消費電力であるため、ヘッドフォンやスマートフォンなどの小型のエレクトロニクス製品でもAfterMaster HD処理技術を活用することが可能になるという。なお、同製品はON Semiconductorのグローバルな販売チャネルおよび流通ネットワークを通じて入手することが可能だという。
2015年05月08日
モスバーガーを展開するモスフードサービスは5月19日、全国のモスバーガー店舗(一部店舗除く)にて、モスライスバーガー「彩り野菜のきんぴら 国産野菜使用」を発売する。○より旨みと醤油の味わいをアップさせリニューアル同商品は、現行のモスライスバーガー「彩り野菜のきんぴら」をリニューアルし、新たに販売するもの。今回きんぴらに使用する食材は、現行の人参、椎茸、高野豆腐、唐辛子に加え、ごぼう、こんにゃく、昆布、枝豆の8種。具材の野菜、焼きのりと米は国産食材を使用している。また、これまで濃口醤油と白醤油(色の淡いしょうゆ)を使用していたが、風味の異なる2種類の濃口醤油に変更し、より旨みと醤油の味わいをアップさせたという。有明産の焼きのりの上に、京都のおばんざいをイメージした具だくさんのきんぴらをのせ、ライスプレートではさんだ。きんぴらにはごぼう、人参、こんにゃく、昆布、枝豆、椎茸、高野豆腐、唐辛子を使用。味付けには風味の異なる2種類の濃口醤油のほか、昆布の戻し汁を加えており、醤油のコクや深み、昆布だしの旨みを感じる仕上がりになっているという。価格は340円(税込)。
2015年04月25日
ファミリーマートはこのほど、「FamilyMart collection 下ゆで野菜 汁もの料理用」「FamilyMart collection 下ゆで野菜 煮込み料理用」を発売した。○野菜ごとに下ゆでして1パックに同商品は、同社と全国農業協同組合連合会(JA全農)との包括提携契約にもとづき共同開発された商品。国産野菜を使用し、「FamilyMart collection」ブランドにて、北海道、宮崎県、鹿児島県、沖縄県を除く全国のファミリーマート店舗で販売する。汁もの料理や煮込み料理など、素材の下ごしらえに時間や手間のかかる料理を手軽に作れる商品として開発され、それぞれの料理に合わせ食べやすくカットするとともに、野菜ごとに下ゆですることで、素材そのものの美味しさを引出したという。「下ゆで野菜 汁もの料理用」は、国産野菜(大根、にんじん、ごぼう、里いも)を薄切りにして、それぞれに適した時間で下ゆでした。豚汁などの汁もの料理の素材を想定。価格は318円(税込)。「下ゆで野菜 煮込み料理用」は、国産野菜(じゃがいも、にんじん、玉ねぎ)を一口大に切って、それぞれに適した時間で下ゆでした。カレーやシチューなどの煮込み料理の素材を想定しているという。価格は318円(税込)。
2015年04月19日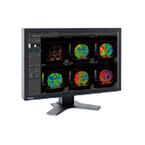
東芝メディカルシステムズは、複数のモダリティに対応する医用画像処理ワークステーション「Vitrea V7」の国内販売活動を開始したと発表した。Vitreaは、これまでCT専用ワークステーションとして国内外に向けて販売されてきた。新製品となるVitrea V7では、CT、MR、ガンマカメラ、PET-CTなど複数のモダリティで撮影された画像データを統合的に扱うことが可能になり、さまざまな臨床アプリケーションのほか、撮影プロトコルの管理、線量情報管理ツールなどを搭載していることから、撮影から画像処理までトータルに提供し、高度な診断の支援と院内業務の効率化を実現するという。また、新開発のプラットフォームを採用することでさまざまばアプリケーションの搭載を可能としており、他社アプリの搭載により、臨床現場の多彩なニーズに応えることを可能としている。
2015年04月16日


















