
マクドナルドの王道メニュー「ビッグマック」は、単品で何kcalかご存知でしょうか?正解は530kcal。Mサイズのポテト(454kcal)とコカ・コーラ(140kcal)をセットで注文した場合、1,124kcalにもなります。一般的な成人の摂取カロリー目安は1,800~2,200kcalとされていますから、ビッグマックセット1食分で1,124kcalというのは気になる数字ではないでしょうか。そこで今回は、他の米やパンなどの炭水化物メニューと比較して、「ビッグマック1個分のカロリーならばどれくらいの量を食べられるか」を、お伝えしたいと思います。それだけの量を食べられるなら「今日のビックマックをやめておこう」と思うのか、それとも「いいや、それでも私の気分はビッグマックだ!」となるのか、そこはご自身の判断次第ですが、納得できる結果が出ていますよ。■10位:焼きそば(1皿)ビッグマック1個と、豚肉やにんじん、キャベツなど一般的な具が入ったソース焼きそば1人前がほぼ同じカロリーです(527kcal)。少し豪華な五目焼きそばや、あんかけ焼きそばだとビックマックより高カロリーになります。■10位:スパゲッティーミートソース(1皿)料理方法やお店によって変わってきますが、イタリアンレストラン・サイゼリヤの「ミートソースボロニア風」のカロリーは538kcalで、ビッグマックとほぼ同じ。■8位:そうめん、ひやむぎ(1.5人前)食欲のない暑い夏でも、そうめんであれば1人で2束はペロリと食べられるかもしれません。でも、2束食べると約360kcalになります。■7位:赤飯(2膳)1膳(140g)で265kcalなので、ちょうどお茶碗2膳分がビッグマックと同じカロリーです。もち米を使ったおこわでも、おかわりできちゃう程なんですね。■7位:うどん(2人前)うどんチェーン店のはなまるうどんで提供されている「かけうどん」は、273kcal。ここにたまごや肉などの具がのるとカロリーも上乗せされます。■5位:そば(2.5人前)ゆでたそば100gが132kcalなので、1人前(160g)になると約215kcal。2人分食べたとしても、まだビッグマックの方が高カロリーです。■4位:白米ごはんのおにぎり(3個)おにぎりは、握る人によってサイズが違います。ここではコンビニで売っているサイズ(約100g)のカロリー、168kcalで計算して約3個という結果になりました。おにぎりを3個食べると、多くの人が満腹になるはず。■4位:食パン(3枚)もちろんメーカーや種類、8枚切りか6枚切りかによって大幅にカロリーも変わってきます。今回はパスコの「超熟6枚切り」(1枚あたり163kcal)で計算しています。食パンにジャムもバターも塗らずそのまま食べる人は少ないと思いますので、なにかを足せばもちろんその分カロリーが増えます。■2位:モチ(4個半)四角い切りモチ1個が約120kcalですので、ビッグマックと同じカロリーなら4個以上は食べられるということ。しかし、これも食パン同様、食べるときにはなにかしら加えると思います。砂糖の混ざったきなこなら大さじ1で21kcal、つぶあんなら大さじ1で49kcalが加算されます。■1位: おかゆ(5膳)当然といえば当然の結果ですが、白米の量を減らしお湯でかさ増しをしているおかゆは、炭水化物のなかでも低カロリーの代表選手。梅干しや鮭などで味もつけずにお茶碗5膳の量を食べるのは大変ですが、ビッグマックと同じカロリーであるという驚きは感じていただけたのではないでしょうか。*これだけの量が、ビッグマック1個分のカロリーで食べることができるのです。ビッグマックを食べることで体に起きる変化についても、衝撃的な話ばかり。どんな食事でも同じことがいえますが、高カロリーのジャンクフードを食べ続けるのは控えた方が賢明かもしれませんね。(文/中田蜜柑)
2015年11月03日
NECは11月2日、ビッグデータ分析を高度化する人工知能技術の1つとして、予測に基づいた判断や計画をソフトウェアが最適に行う「予測型意思決定最適化技術」を開発したと発表した。「予測型意思決定最適化技術」は、同社が開発したビッグデータに混在する多数の規則性を発見する「異種混合学習技術」などを用いた予測結果に基づいて、従来は人間が行っていた戦略や計画の立案といったより高度な判断をソフトウェアで実現するもの。同技術を実際のデータに適用したところ、水需要予測に基づく配水計画では、浄水・配水電力を20%削減する高精度な配水計画を生成でき、商品需要予測に基づく価格最適化では店舗の売上を11%向上する商品価格戦略を1秒未満で瞬時かつ自動的に生成できたという。新技術の特徴の1つは「予測誤差に対してリスクが低く効果の高い計画を生成」する点。予測の「典型的な外れ方」(予測誤差)のパターンを独自のアルゴリズムで分析し、その結果を数理最適化技術と融合することで、「外れ方」を勘案したうえで最適化することで、予測が外れても損失が発生するリスクが低く、安定して高い効果がでる計画を算出できる。もう1つの特徴は「大量の予測式の関係を考慮した最適な計画を超高速に生成」できる点。独自の組合せ最適化アルゴリズムによって、予測式の関係を考慮した大規模な組み合わせを効率的に探索し、超高速に最適な戦略・計画を導出することができる。
2015年11月03日
エクスペリアンジャパンはこのたび、消費者セグメンテーション・データ「Experian Mosaic Japan (以下、Mosaic)」が、Nearの「Allspark」に第三者データとして実装したされたことを発表した。Allsparkとは、スマートフォンアプリから利用者の許諾を得て取得した位置情報のデータとそのほかの第三者データなどを掛け合わせ、モバイル・オーディエンスを構築できるというプラットフォーム。一方Mosaicは、郵便番号などの居住地情報から、家族構成や年収レベル、居住状況、オンライン・リテラシー、車所有状況など各種のライフスタイル情報を可視化できるというセグメンテーション・データだ。AllsparkにMosaicを第三者データとして組み込むことにより、Allspark上にてオーディエンス構築を行う際に、位置情報に加えライフスタイル情報を利用できるようになる。これにより、より消費者の気持ちに寄り添ったターゲティングと広告出稿、メッセージ設定、コンテンツの配信を実現するほか、Mosaicの利用によりLook-Alikeモデリング(オーディエンス拡張)が実現できるため、潜在顧客へのアプローチなども可能となる。同社によると、たとえば、カー用品の販促施策として、行楽シーズンに合わせたタイヤのディスカウント・キャンペーンを展開する場合、店舗の半径1km以内のターゲット・オーディエンスに対しキャンペーン告知バナーを表示するという条件に、ライフスタイル情報による推計を加えると、所有車種や家族構成による推定ターゲットの絞り込みや、メッセージの変更ができるという。
2015年10月30日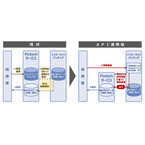
エヌ・ティ・ティ・データ(以下、NTTデータ)は22日、家計簿アプリなどの個人資産管理(PFM)サービスやクラウド会計サービスなどのFintechサービスと、NTTデータが金融機関に提供する共同利用型の個人向けインターネットバンキングサービス「AnserParaSOL」を接続するAPI連携サービスを2015年度中に提供開始すると発表した。○ネットバンキング利用者の拡大を期待同サービスは、利用者がインターネットバンキングのIDとパスワードをFintechサービスに登録することなく、銀行取引データ等の連携を可能とするもの。これにより、利用者はより安全にFintechサービスを利用できるようになる。また、Fintechサービス利用者を新たに取り込むことで、金融機関はインターネットバンキング利用顧客の拡大が期待できるという。第1弾として、個人向けインターネットバンキングサービス「AnserParaSOL」での対応から開始し、第2弾として、法人向けインターネットバンキングサービス「AnserBizSOL」への展開も検討していく。NTTデータ広報は「新サービスではこれまでより安全・便利に活用してもらえるよう、企業や個人をターゲットとして提供していく」と話している。今後は、マネーフォワードとfreeeの両社と共同で2015年中にサービス提供を開始。さらに、NTTコミュニケーションズや弥生が提供するFintechサービスとの連携も予定しているという。
2015年10月23日
日立製作所は、多種多様なビッグデータの統合・分析・可視化を迅速に実現するBI製品「Pentaho」を用いたビッグデータ利活用のシステム導入支援サービス2種を10月21日から販売開始する。Pentahoは、日立の米国子会社であるHitachi Data Systemsが2015年5月末に買収した、米Pentahoが提供するオープンソースのソフトウェア。無償版と有償版がある。今回提供されるのは、ビッグデータ利活用の最適な手法を導き出すための技術支援を行う「データ利活用トライアルサービス」と、Pentahoをインストールしたシステム検証環境をクラウドで利用できる「データ利活用検証支援サービス」。「データ利活用トライアルサービス」は、ビッグデータ利活用に向けたシステムの本格導入に先立ち、顧客のシステム環境の特性やデータ形式・種別などをヒアリングし、それに基づき、分析対象データの仕分け、分析結果の可視化における要点の提示、分析結果に対する適切な評価指標の設定など、最適なデータ利活用の手法を導き出し、具体化するための技術支援を提供する。また、検証結果に関するレポート作成支援や、本格導入の際のシステム要件の提案など、検証結果を踏まえたシステム本格導入に向けての支援も行う。「データ利活用検証支援サービス」は、「データ利活用トライアルサービス」で具体化したビッグデータ利活用手法について、Pentahoをインストールした日立のクラウド上のシステム検証環境で導入効果を実際に検証できるサービス。顧客のPCから遠隔でシステム検証環境を利用できるため、顧客は導入検証用の環境を用意する必要がなく、初期投資を抑えることができ、サンプルデータを使った分析に加え、顧客の実データの持ち込みにも対応するなど、検証環境に対するニーズにも柔軟に対応する。加えて、データ統合機能により、多様なデータを関連させた高度なデータ分析であっても、迅速に検証結果を確認することができる。同社は、本格的なシステム導入・運用に対応した、Pentahoをインストールしたシステム実行環境をクラウドで利用できるサービスも、2015年度末までに提供を開始する予定。
2015年10月21日
ビッグデータ分析とマーケティング・アプリケーションを扱う、米テラデータ・コーポレーション(テラデータ)は10月7日(現地時間)、データウェアハウジングおよび分析ソリューションであるTeradata DatabaseをAWS上でクラウド配備で提供し、本番環境のワークロードをサポートすることを発表した。Teradata Database on AWSの最初のバージョンは、数テラバイトに対応する多様な個々の仮想サーバーであるAmazon Elastic Compute Cloud(EC2)インスタンス上で、AWSがサポートされている国・地域において、AWS Marketplaceより提供される予定だ。Teradata Database on AWSは、テスト/開発、品質保証、データ・マート、障害回復、本番分析などで利用できる。テラデータのデータウェアハウスおよび分析ソリューションの利用用途の拡大や、クラウド上のデータ・ソースおよびクラウド内で提供されているパートナー・ソフトウェアに近い位置でのデータベースの利用、システム規模の変更が容易で、セルフサービスによるプロビジョニングと時間単位の従量制課金での利用といったことが、顧客企業の主なメリットとなる。さらに、Teradata Production and Advisory Servicesというサービスも提供される。これは、同社のプロフェッショナル・サービス部門が、新規および既存の顧客企業を対象に、Teradataデータベースのプロビジョニング、統合、管理、微調整などを、あらゆる配備オプションを通じて提供するもの。Teradata Database on AWSの最初のバージョンは、2016年第1四半期に全世界で、数テラバイトに対応する多様な個々のAmazon EC2インスタンス・タイプにおいて、AWS Marketplaceから提供される予定だ。EC2はWebベースのサービスなのでビジネス用途で利用する顧客は、Amazonのコンピューティング環境内で、従量制課金でアプリケーション・プログラムを実行可能だ。利用環境は、AWS上での単独展開、もしくはオンプレミスまたはTeradata Cloudの環境の3つから選ぶことができる。
2015年10月16日
マクロミルは10月13日、早稲田大学データサイエンス研究所と共同研究を開始することを発表した。同研究は、「統計学及びマーケティングにおける非集計データの高次利用」がテーマとなっており、マクロミル保有の購買データならびに意識調査データをもとに「データ・サイエンスに関する教材の開発」「数理統計学・機械学習の理論並び実証研究」「消費者行動のモデル化に関する実証研究」「マーケティング実務における意思決定支援のためのデータ活用に関する研究」といった項目が実施される。一部の研究においては、マクロミルのアナリストやリサーチャーが関わり、知見を活かすことで可能性の拡大を目指していくとしている。
2015年10月14日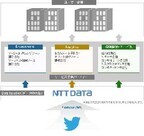
NTTデータは10月8日、「Twitterデータ提供サービス」をすべての言語に対応させたと発表した。同社は、2012年9月に米TwitterとTwitterデータ再販契約を締結し、2012年12月より「Twitterデータ提供サービス」を提供することと並行し、企業などでのソーシャルデータの利活用の推進を検討してきた。これまでは、提供データの対象言語を「日本語のみ」としていたが、Twitterとの新たなパートナーシップ契約を締結することで、日本語以外の言語を含むすべてのデータを使った分析活用とシステム開発が可能となり、顧客からの要望の高い訪日外国人動態調査でのデータ利用や、ブランドモニタリングのためのグローバルBIでの活用など、Twitterデータのさらなる利用用途拡大が可能となった。なお、価格は、提供データの対象範囲や分析の方法などによって、個別の見積もりとなる。今後、同社ではTwitterデータの提供と、ソーシャルデータを含む顧客社外の情報を活用することで、顧客企業活動に貢献できるシステムやソリューションの開発を推進し、関連ソリューション含めて、2020年度までに50億円の売り上げを目指すとしている。
2015年10月09日
トランスコスモスは10月7日、データフィードサービス「t-eams for Data Feed Bid Manage (チィームス・フォー・データフィード・ビッドマネ ジャー)」の提供を開始し、運用型広告サービスの拡充を図ることを発表した。同サービスでは、広告媒体の特徴に合わせ「ブランド名」「色」「サイズ」「説明文」などの商品情報を追加・置換・削除し、最適な入稿データを自動生成。媒体および商品ごとに入札調整を行い、季節のトレンド商品や販売強化商品の広告効果を向上させるほか、商品単位の効果検証により、広告対象商品を絞り込むことで、無駄な配信コストを削減できる。同社によると、ECや不動産、旅行などの業界を筆頭に、Webサイト上で多数の商品・サービスを取り扱う企業が増加するに伴い、商品リスト広告やアフィリエイト広告、レコメンド広告など、広告の種類も急増。広告効果を最大化するため、データフィードを用いた広告運用ニーズが高まっているという。
2015年10月07日
データアーティストは10月1日、ワイヤーアクションが収集するテレビのメタデータを用いた新しいマーケティングツール「コトモノ」の無償版をリリースした。有料版は近日中に提供開始を予定している。同ツールは、テレビで取り上げられる事柄(コト)と関連度の高い商品(モノ)を結び付けて潜在的なニーズを喚起させ新しい市場の創出を実現するもの。「テレビに取り上げられるキーワードの出現傾向の分析機能」と「テレビに取り上げられるキーワードの詳細な文脈分析機能」を提供する。「テレビに取り上げられるキーワードの出現傾向の分析」では、検索対象キーワードのテレビでの出現回数の時間変化を週別に、過去3年にわたって閲覧することが可能。これにより、キーワードがテレビに登場する傾向(季節性・増減)や新たな流行ワードの登場を把握し、製品とタイアップすべき事柄を特定できる。「テレビに取り上げられるキーワードの詳細な文脈分析」では、検索対象キーワードが登場した番組の詳細な情報(番組名・番組内の放送内容・一緒に登場したキーワード)を把握できる。これによりもっとも適切な文脈で製品と事柄のタイアップを実現する。
2015年10月02日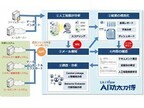
人工知能を駆使したビッグデータ解析事業を手がけるUBICは10月1日、業務上のメールや日報などの電子データを解析し、潜在的なチャンスやリスクを人工知能が知らせる、ビジネスデータ分析支援システム「Lit i View AI助太刀侍(AI助太刀侍)」の提供を開始すると発表した。「AI助太刀侍」は、ビジネス上の膨大なデジタルコミュニケーションの中から、たとえば「最近お忙しそうですね?」と営業担当者の来訪を緩やかに期待する顧客からのメールのような、まだ顕在化していない「予兆」をいち早く人工知能が捉えることでビジネスチャンスの獲得と機会損失の防止、リスクの回避など行うもの。まず、顧客の経験や暗黙知に基づいて、検知が必要か不要かに仕分けられた一定数のデータを「教師データ」として「AI助太刀侍」に学習させ、次に同社のクラウド環境「Intelligence Cloud」上の「AI助太刀侍」に、顧客のメールサーバーやファイルサーバーからメール、日報などの調べたい電子データをインポートする。その電子データを「AI助太刀侍」で解析し、検知したい教師データとの関連性が高い順にスコアリングして、上位から順に表示。一定のスコアを超えたデータが発生した場合は、「AI助太刀侍」からその顧客の管理者に自動でアラートを出したり、高スコアのデータの詳細を表示させる。さらに、検知状況の統計レポートや、今後の発生を予測する分析レポートも作成する。再学習による人工知能の強化も可能で、「AI助太刀侍」の「Central Linkage(セントラルリンケージ)」の機能では、より深く調査したい対象者について、「誰から誰に宛ててメールが送られ、誰にCC:されているか?」などを相関図で表示することができ、情報が渡る経路や、送られるべき人に情報が出ていなかったり共有すべき情報が共有されていないケースなどを把握できる。今後、APIの提供による、外部のシステムと「AI助太刀侍」との連携を行う予定があり、販売代理店が独自に開発したレポートの出力、分析機能との連携も可能になるという。
2015年10月02日
米Splunkはこのほど、企業向けビッグデータ分析ソフトウェア「Splunk Enterprise」の最新版となる「Splunk Enterprise 6.3」の一般提供を開始したと発表した。「Splunk Enterprise 6.3」では性能の引き上げが実現されており、Splunk Enterprise 6.0と比較して要求されるハードウェアのコストが半分まで削減されている。「Splunk Enterprise 6.3」の主な注目ポイントは次のとおり。検索、レポート、データオンボーディングの速度が2倍に高速化ハードウェアに必要な費用を従来のバージョンと比較して50%削減さまざまな可視化機能の提供HTTP/JSON APIによる操作の提供新しいモニタリングおよび可視化機能による運用の簡素化Splunkはさまざまなテキストデータをリアルタイムに分析することを得意とする企業。テラバイトやペタバイトといったビッグデータをインタラクティブに解析することで、システムモニタリングや調査、経営判断材料の抽出といったさまざまなシーンで活用できるが、近年はセキュリティに関する解析で業績を伸ばしている。
2015年09月30日
電通ブルーは10月1日、写真・動画共有SNS「Instagram」のビッグデータを活用した「#ハッシュタグコンサルティング」のサービスを提供開始したと発表した。9月7日より無料トライアルキャンペーンが実施されていた。同サービスは、Instagramの日本語ハッシュタグランキングデータを統計的に調査・解析するFBrankとの独占提携によるもので、ユーザーの多くがInstagram内で「ハッシュタグ」を使って目指す画像を検索する行動に着目し、Instagramのビッグデータから、統計的手法により、投稿するコンテンツに付記する最適な「ハッシュタグ」を推薦するというもの。また、ビューティー、フード、ファッションなど、ジャンル別の企業と個人のアカウントランキング(フォロワー数、フォロワー増加数、投稿写真のいいね数、投稿写真のエンゲージメント率)およびハッシュタグのランキング(総使用回数、前日からの使用回数増加率)が提供されるほか、レポート機能も実装されている。利用料金は、平日朝10時までにメールで申し込みを受けた場合に、15時までにハッシュタグ推薦機能のレポートをメールで受け取ることができる「ワンタイムコース」が、2万9,800円(税込)。会員サイト「Tokyo Trend Photo PRO」を自由に閲覧できるコースで、使用回数上昇中のハッシュタグや同時使用タグなどを利用者自身が検索でき、月間100回までのハッシュタグ推薦機能を利用できる「マンスリーコース」が9万9,800円(税込)となっている。
2015年09月30日
さくらインターネットは、北海道石狩市にある郊外型大規模データセンターである石狩データセンターを拡張し、新しいコンセプトをもつ3号棟の建設を決定したと発表した。竣工時期は2016年冬を予定している。3号棟では、既存棟の直接外気冷房方式から空調コンセプトを変更し、室外機と空調機の間を循環する冷媒を外気で冷やしてサーバルームを冷却する、間接外気冷房方式を導入。外気を室内に導入しないため湿度変動がなく、除湿器・加湿器、加湿のための給水などが不要となり、ランニングコストをさらに削減できるという。また、サーバルーム内の空調には、新たに上部壁吹き出し方式を採用し、送風ロスの低減と作業空間の快適性を両立する。設備面では、将来的な大型機器の導入や大量搬入に対応するために、搬入口からサーバルームまで電動フォークリフトでの走行を可能とし、あらかじめラックにサーバを搭載した状態で納品を受ける、セットアップラックへの対応も可能。配電設備においては、従来のケーブル方式ではなくプラグイン分岐機構をもつバスダクト方式を全面的に採用し、ラック増設、供給電力変更時などの電気工事を不要とする。さらに、3号棟の収容ラック数、スペース効率が大幅に向上し、従来棟比で約1.6倍のラック収容密度を実現、最大収容ラック数は1,900ラックとなり、既存棟をあわせた石狩データセンター全体での最大ラック数は、3,000ラックになるという。
2015年09月30日
富士通は9月24日、ビッグデータの分析サービス「FUJITSU Intelligent Data Service データキュレーションサービス」の分析基盤において、スーパーコンピュータの開発・提供を通じて培ったハイパフォーマンスコンピューティング(HPC)技術を用い、テラバイト以上の超大規模データの分析処理時間を従来比30倍(実測値での速度比較。同社調べ)に高速化したと発表した。同データキュレーションサービスを同日から新基盤に移行し、活用を開始する。販売価格は個別見積(税別)。同社は顧客のデータをキュレーター(データサイエンティスト)が分析し、標準8週間でデータ活用のモデル作成を行うサービスであるデータキュレーションサービスを2012年4月から提供している。同サービスにより、ビッグデータ分析を始める際の設備投資やデータサイエンティストの準備などのコストを抑えつつ、本格的なデータ活用の可能性を検証することができる。また、データキュレーションサービスはデータそのものに着目し、業種・業態に制限されないため、多様な顧客の様々な課題に対してサービスの提供が可能となっている。今回、データキュレーションサービス用に、自社データセンター内にビッグデータ分析専用のHPCクラスタを構築。HPCクラスタは、複数のPCサーバ「FUJITSU Server PRIMERGY(プライマジー)」を高速なインターコネクトで接続したもので、専用の並列処理ライブラリを適用することにより1000コアを越えるCPUの並列処理ができる。ハードウェアとソフトウェア両面の強化により、従来と比較し約30倍の超大規模データ高速処理を可能とした。また、既存の豊富なオープンソースソフトウェア(RやPythonで書かれたアプリケーション、Hadoop、Spark、DeepLearning系フレームワークなど)の変更なしに運用が可能な高い汎用性を有している。高速処理技術を搭載した分析基盤を用いることで、従来1週間を要していた数千個の属性データを持つ数百万人分の顧客データなどの超大規模データに対する分析を数時間に短縮。これにより、ビッグデータ活用が実用・商用フェーズに入り、より膨大なデータの分析を必要する顧客においても、分析結果をビジネスへいち早く反映することが可能となる。
2015年09月24日
ヤフーとグループ会社のIDCフロンティア(IDCF)は9月17日、福島県白河市の環境対応型大規模データセンター「白河データセンター」に新しく3号棟を建設すると発表した。1棟50ラック・全6棟で構成される計300ラック規模で、10月1日着工、2016年2月末の竣工を予定している。白河データセンター3号棟は、増加するデータの格納や、Yahoo! JAPANが保有するマルチビッグデータを活用するための処理基盤強化を目的として、Yahoo! JAPAN向けに提供する。データセンターで、さまざまな企業が各種のIT機器を利用する場合と比べ、1社専用とすることで、設置する機器の画一化と動作環境を絞り込むことが可能となり、建物の工期短縮と効率の高いサーバーの収容を実現するという。ネットワークの伝送路を直線距離に極力近づける最短経路で設計し、中継ノードも可能な限り少なくすることにより、東京-白河間のレイテンシは、東京近郊に位置するデータセンターと同等の3.5ミリ秒前後の応答速度を実現。物理的な距離に比例しない高速なネットワーク環境を提供する。また、サーバーから出る排熱を冷やすための空調ユニットには、外気を導入して空調効率を高める間接外気空調方式を採用。空調ユニットはサーバールームのモジュールに直接接続され、白河の冷涼な気候を最大限活用して年間のPUEは設計値で約1.2を見込む。
2015年09月18日
データの増加とどこからでもアクセスしたいというニーズを受けて、データセキュリティ戦略の第一歩としての暗号化に注目が集まっている。セキュリティベンダーのソフォスが、選ぶためのポイントを同社ブログでアドバイスしている。暗号化というと実装が複雑すぎる、管理が面倒などの共通認識があるようだが、正しい暗号化ソリューションを利用すればそのような問題はないはずだ。以下に、自社にとって正しい暗号化ソリューションを選択する際のポイントを挙げたい。○使い勝手複雑すぎて使用できないセキュリティ製品は、しかるべきセキュリティ機能を提供しない。暗号化ソリューションは包括的かつシンプルである必要性がある。データがどこにあってもそれを保護し、実装や管理にあたってITのリソースを必要としないものがよい。○マルチプラットフォームWindows、Mac、Android、iOSなどさまざまなOSをサポートし、かつさまざまな種類の暗号化技術に対応するものを。○ワークフローに合う日常の作業の支障にならない形でデータを保護できるというのが理想的だ。暗号化ソリューションは自社のワークフローにあったものを選択すべきだ。暗号化ソリューションにワークフローを合わせると決してうまくいかない。○評判をチェック意思決定を下す前に、その製品についての評判や評価をチェックしたい。業界アナリストやレビュー専門家、そして顧客の声は参考になるはずだ。○拡張性組織の成長に合わせて拡張できる暗号化ソリューションを。○規制遵守データが漏洩するという最悪の事態が起きたとき、暗号化対策を講じておくことでデータ窃盗者の手に渡ったとしてもデータは読むことができず、何の利用価値もないものとなる。垂直業界や固有のデータ保護法や規制のある地域にいる場合、監査担当はデータが暗号化されていたという証拠が必要だ。
2015年09月17日
さて、第3回まででデータを入力するテーブルが完成したので、今回は実際にデータを入力/変更/追加して第1回の表1を再現していきましょう。○データの入力(INSERT文)まずは、1人目の佐藤一郎君のデータを挿入します。直接端末に命令を打ち込むよりも、ご利用のテキストエディタに入力してコピー&ペーストすると見通しがよくなります。mysql> insert into first>(name, jpn, math, eng, created, modified) values>(’佐藤一郎’, 94, 87, 60, now(), now());Query OK, 1 row affected (0.00 sec)データの挿入にはINSERT文を使います。「insert into first」という命令を和訳すると、「テーブルfirstに以下の情報を挿入せよ」となります。2行目以降を見ると、テーブルfirstの各フィールドであるname, jpn, math……などを指定した上で、個別の値を入力していることがわかると思います。valuesの前後で各データが対応していないと正しく入力されませんので、エラーが生じた場合には、「nameと佐藤一郎、jpnと94、……」というように、各フィールドと各データの1対1対応をチェックしてみてください。それでは残りのメンバーのデータも入力していきましょう。以下のように一気に入力することができます。各メンバーの情報を区切るときには「, (カンマ)」を、最後のメンバーの情報の後に「; (セミコロン)」を付けることを忘れないようにしてください。mysql> insert into first>(name, jpn, math, eng, created, modified) values>(’鈴木二郎’, 62, 80, 49, now(), now()),>(’高橋三郎’, 40, 77, 90, now(), now()),>(’田中四郎’, 78, 59, 42, now(), now()),>(’伊藤五郎’, 45, 87, 56, now(), now());Query OK, 4 rows affected (0.01 sec)Records: 4 Duplicates: 0 Warnings: 0ここに「id」が書かれていないことに気付かれた方もいるのではないかと思います。オプションで自動連番(auto_increment)を設定したため、各フィールドが追加される度に自動でidが割り振られています。また、now()は現在時刻を入力する関数です。○データの選択(SELECT文)果たして、無事にデータは挿入できたのでしょうか。ここではテーブルに入力されたデータを操るためのSELECT文をご紹介します。SELECT文の基本パターン先ほど挿入したデータの内容を確認するためには、「select * from first」を実行します。すると、入力したデータがテーブルの形で表示されます。mysql> select * from first;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 1 | 佐藤一郎| 94 | 87 | 60 | 2015-05-14 04:49:07 | 2015-05-14 04:49:07 || 2 | 鈴木二郎| 62 | 80 | 49 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 3 | 高橋三郎| 40 | 77 | 90 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 4 | 田中四郎| 78 | 59 | 42 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 5 | 伊藤五郎| 42 | 87 | 56 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 |+-------------------------------------------------------------------------------+5 rows in set (0.00 sec)「select * from first;」は「first という名前のテーブルからすべてのデータ(*)を表示しなさい」という意味です。この「*(アスタリスク)」の意味を理解するために、以下の命令を実行してみます。mysql> select name from first;+-------------+| name |+-------------+| 佐藤一郎|| 鈴木二郎|| 高橋三郎|| 田中四郎|| 伊藤五郎|+-------------+5 rows in set (0.00 sec)これは、「firstという名前のテーブルから氏名のデータ(name)を表示しなさい」という意味です。また、氏名と国語の得点を表示したい場合には、以下の命令を実行します。mysql> select name, jpn from first;+-------------+------+| name | jpn |+-------------+------+| 佐藤一郎| 94 || 鈴木二郎| 62 || 高橋三郎| 40 || 田中四郎| 78 || 伊藤五郎| 42 |+-------------+------+5 rows in set (0.00 sec)また、「order by」を利用することでデータを昇順(あるいは降順)に並び替えることができます。mysql> select * from first order by jpn;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 3 | 高橋三郎| 40 | 77 | 90 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 5 | 伊藤五郎| 42 | 87 | 56 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 2 | 鈴木二郎| 62 | 80 | 49 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 4 | 田中四郎| 78 | 59 | 42 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 1 | 佐藤一郎| 94 | 87 | 60 | 2015-05-14 04:49:07 | 2015-05-14 04:49:07 |+-------------------------------------------------------------------------------+5 rows in set (0.00 sec)この場合、「order by jpn」ですので、国語の成績を昇順(小さい値から順番に並べること)で並び替えることになります。「order by jpn desc」とすることで降順(大きい値から順番に並べること)になります。このように、SELECT文を使うことで、テーブル内のデータを自由に取り出したり並び替えたりすることができます。SELECT文の応用パターン(条件付き抽出)今回は、計5名の試験結果のみをテーブルに格納してあるので気になりませんが、たとえば、10,000人の受験者を抱える試験などの場合、全員分のデータを一覧表示しても有益な情報は得られません。そこで重要になるのが、条件付き抽出を行うための「where句」の利用です。たとえば、国語で90点以上の成績を収めた人物のみを呼び出すためには、以下の命令を実行します。mysql> select * from first where jpn >= 90;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 1 | 佐藤一郎| 94 | 87 | 60 | 2015-05-14 04:49:07 | 2015-05-14 04:49:07 |+-------------------------------------------------------------------------------+1 row in set (0.00 sec)「select * from first where jpn >= 90」を和訳すると、「firstという名前のテーブルから国語で90点以上獲得した人物の全データを抽出せよ」ということになります。where以下で「90点以下の人物だけを抽出」という条件を課しているということです。90点以下の人物を呼び出す場合は、不等号を逆にすることで同様に呼び出すことができます。また、国語でちょうど90点を獲得した学生のみを呼び出すための命令は以下のようになります。mysql> select * from first where jpn = 90;Empty set (0.00 sec)該当者がいない場合には、Empty setというメッセージが表示されます。「=(イコール)」の代わりに「!=(ノットイコール)」をすると、90点ではないすべての人物を抽出できます。文字列を呼び出す場合には、必ず「’(シングル・クオテーション)」で囲むようにしてください。たとえば、高橋三郎君の成績を呼び出す場合は、以下のような命令になります。mysql> select * from first where name = ‘高橋三郎’;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 3 | 高橋三郎| 40 | 77 | 90 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 |+-------------------------------------------------------------------------------+1 row in set (0.00 sec)しかし、すべての学生のフルネームを覚えているとは限りません。苗字しか覚えておらず高橋一郎なのか二郎なのか三郎なのか……というように悩んだ場合には、以下のように命令すれば呼び出すことができます。mysql> select * from first where name like ‘高橋%’;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 3 | 高橋三郎| 40 | 77 | 90 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 |+-------------------------------------------------------------------------------+1 row in set (0.00 sec)%は任意の文字列を表しているため、テーブルに高橋六郎君、高橋七郎君の情報が登録されている場合には、この二名も同時に呼び出されることになります。逆に、名前しか覚えていなくて佐藤三郎君なのか山田三郎君なのか高橋三郎君なのか…というように悩んだ場合には、上記の「高橋%」を「%三郎」にすることで呼び出すことができます。ほかにも、さまざまな命令を使いデータを絞り込むことができます。たとえば、国語の得点が40点~70点の範囲の学生を呼び出す場合には「between」を使います。mysql> select * from first where jpn between 40 and 70;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 2 | 鈴木二郎| 62 | 80 | 49 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 3 | 高橋三郎| 40 | 77 | 90 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 5 | 伊藤五郎| 42 | 87 | 56 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 |+-------------------------------------------------------------------------------+3 rows in set (0.00 sec)また、「or」を使うと、国語あるいは英語の得点が90点以上の人物を呼び出したりすることもできます。mysql> select * from first where jpn >= 90 or eng >= 90;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 1 | 佐藤一郎| 94 | 87 | 60 | 2015-05-14 04:49:07 | 2015-05-14 04:49:07 || 3 | 高橋三郎| 40 | 77 | 90 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 |+-------------------------------------------------------------------------------+2 rows in set (0.00 sec)上記の「or」を「and」に変えれば、国語と英語の両方の得点が90点以上の人物を呼び出せます。以上は一例ではありますが、where句を利用することで、自分の思いどおりのデータを引き出せるようになるイメージは湧いたのではないかと思います。○データの修正(UPDATE文)データベースに修正を加える場合には、UPDATE文を利用します。たとえば、高橋三郎君の国語の得点を40点から80点に変更する場合、以下のような命令になります。mysql> update first set jpn = 80 where id = 3;Query OK, 1 row affected (0.01 sec)Rows matched: 1 Changed: 1 Warnings: 0ここで使われた命令「update first set jpn = 80 where id = 3」を和訳すると、「firstという名前のテーブルのid=3(高橋三郎君)の国語の得点を80点に更新せよ」ということになります。この場合、英語や数学の得点などほかのデータは特に変更することはありません。もし、2つ以上のデータを更新したい場合には、以下のように「, (カンマ)」でつなぐと正しく変更することができます。国語の得点を降順で表示すると、修正事項が反映されていることがわかります。mysql> select * from first order by jpn desc;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 1 | 佐藤一郎| 94 | 87 | 60 | 2015-05-14 04:49:07 | 2015-05-14 04:49:07 || 3 | 高橋三郎| 80 | 90 | 70 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 4 | 田中四郎| 78 | 59 | 42 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 2 | 鈴木二郎| 62 | 80 | 49 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 5 | 伊藤五郎| 42 | 87 | 56 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 |+-------------------------------------------------------------------------------+5 rows in set (0.00 sec)○データの削除(DELETE文)データを削除する場合には、DELETE文を使います。mysql> delete from first where id = 3;Query OK, 1 row affected (0.00 sec)「delete from first where id = 3」を和訳すると、「firstという名前のテーブルのid=3(高橋三郎君)のデータを削除せよ」となります。where句以下を書かないとテーブル内のすべてのデータが消えることになるので、気をつけてください。降順で表示すると、修正事項が反映されていることがわかります。mysql> select * from first order by jpn desc;+-------------------------------------------------------------------------------+| id | name | jpn | math | eng | created | modified |+-------------------------------------------------------------------------------+| 1 | 佐藤一郎| 94 | 87 | 60 | 2015-05-14 04:49:07 | 2015-05-14 04:49:07 || 4 | 田中四郎| 78 | 59 | 42 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 2 | 鈴木二郎| 62 | 80 | 49 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 || 5 | 伊藤五郎| 42 | 87 | 56 | 2015-05-14 04:56:38 | 2015-05-14 04:56:38 |+-------------------------------------------------------------------------------+4 rows in set (0.00 sec)○フィールドの追加(ALTER文)最後に、新しいフィールドを追加する場合を考えます。例えば、国語、数学、英語に加えて、理科の得点を加えたい場合の命令は、以下のようになります。mysql> alter table first add sci int after eng;Query OK, 4 row affected (0.04 sec)Records; 4 Duplicates: 0 Warnings: 0「alter table first add sci int after eng」を和訳すると、「firstという名前のテーブルのフィールドengの後ろにデータ型intのフィールドsciを追加せよ」となります。テーブルの構造を「desc first」で確認してみると、たしかに追加されていることがわかります。mysql> desc first;+-----------------------------------------------------------------+| Field | Type | Null | Key | Default | Extra |+-----------------------------------------------------------------+| id | int | NO | PRI | NULL | auto_increment || name | varchar(255) | YES | | NULL | || jpn | int | YES | | NULL | || math | int | YES | | NULL | || eng | int | YES | | NULL | || sci | int | YES | | NULL | || created | datetime | YES | | NULL | || modified | datetime | YES | | NULL | |+-----------------------------------------------------------------+7 rows in set (0.00 sec)また、テーブル内のフィールド名やデータ型を変更したい場合には、以下のような命令を使います。mysql> alter table first change jpn phys int;Query OK, 0 row affected (0.01 sec)Records; 0 Duplicates: 0 Warnings: 0フィールド名「jpn」をデータ型intのフィールド名「phys」に変更したということです。
2015年09月09日
データアーティスト代表取締役の山本覚です。前回は、マーケターを対象に、データサイエンスの最新トレンド「ディープラーニング」について、その基礎と活用法を紹介しました。今回は、アンケート調査について解説します。○アンケート調査は、今も昔も重要な手法アンケート調査とは、ご存じの通り、古くからあるマーケティング手法の1つ。モニターに一定の選択肢を提示し回答をもらうことで、ノイズを含まない、リサーチャーが知りたい情報をダイレクトに仕入れることが可能です。同手法の起源は、紀元前3,000年頃までさかのぼります。記録によると、古代エジプトではピラミッド建設のために人民の慣習や信条を調査したようです。現代では、たとえば、製品開発前に行う顧客の意識調査や、広告接触後のブランドに対する意識変化の調査などに用いられていますね。本連載のテーマ「想像力を掻き立てる」という視点で見ると、アンケート調査は、データに基づき顧客像を特定したのち、施策の立案などに想像力のリソースを集中するために有効な手法だと言えます。2014年12月、マクロミルが蘭メトリックスラボを買収する際、同社の小西氏が「マーケティングリサーチ市場は国内で1,800億円、海外ではなんと4兆円にものぼる」と語っています。マーケティングリサーチには、アンケートのほか、グループインタビューやデプスインタビュー(1対1)、覆面調査など数多くの手法があり、その中でもアンケートは、定量的なデータが比較的容易に集められるため、評価指標や次の一手を見出すために実施する企業が多いです。最近ではネット上で簡易にアンケートが実施できるネットリサーチが登場し、市場の約3分の1を占めるなど、まだまだ今後も成長する市場だと感じます。○一方で、課題もあるこのように利点が多いアンケート調査ですが、課題もあります。アンケートの結果はあくまで調査結果で、そこから直接的な施策につながりにくいという点です。例えば、「ある保険サービスの広告メッセージを設計するためにアンケート調査を行った」というケースを思い浮かべてください。アンケートの質問項目として、「申込みを検討中」や「どういうサービスかわからない」というような選択肢を設ければ、商品への興味関心の度合いを知ることができます。ここでは、「申込みを検討中」と回答した人を「顕在層」、「どういうサービスかわからない」と回答した人を「潜在層」と定義します。調査後、顕在層が60%、潜在層が40%だということが明らかになったとします。顕在層には申し込みを後押しするため、類似商品との比較やその優位性を訴求するとよいです。一方、潜在層には商品理解を促すため、コンセプトの説明などが効果的だと判断できます。このように、本来であればアンケート調査の回答を参考に、個人にフォーカスしたメッセージを送るべきですが、実際には多数決のように、調査結果で最も多い「顕在層」にのみメッセージを打ち出しているケースを度々見かけます。これでは、せっかくの調査結果と実際の施策が乖離してしまい、効果が薄くなってしまいます。回答者すべてに効果のある施策を打ち出すため、アンケートの集計時に時期や時間帯、性別、年代別といったセグメントで顧客をグルーピングし、「ある時期は20代顕在層からの相談が多く、ある時期には潜在層女性の相談が増える」というように、施策を打つタイミングを分けるという方法があります。しかし、これは、アンケート結果を集計しながら少しずつ顧客の特徴を揃えていくため、精度を高めることが難しく、どうしても別々の層の顧客が混ざってしまいます。このように、アンケートの結果を顧客の興味関心に合わせて細かく仕分けていく作業は、とても手間がかかります。そのため、集計作業に時間や頭のリソースがとられてしまい、本来行うべき施策の立案、クリエイティブ的な視点で言えば「メッセージコピーの設計」にリソースをさけなくなってしまうわけです。○解決策は、アンケート結果とWebサイトの訪問者を紐づけることしかし、このような課題は、DMP(データマネジメントプラットフォーム)の出現により、急速に解決されることになりました。DMPとは、Webページの閲覧情報や商品の購買履歴といったユーザー情報を、マーケティング活動において利用しやすい形式で蓄積できる情報基盤のことです。2013年以降、マーケティング業界において急速にその認知が拡大しました。DMPは、基本的に、各ベンダーが発行するプログラム(タグ)をWebサイトに設置することで利用できます。これにより、Webサイトに訪れたユーザーのcookieや閲覧コンテンツ、検索キーワードなどから、デモグラフィックスや嗜好情報までを抽出・貯蓄することができるようになります。さて、このユーザーIDですが、DMPのプログラムをネットリサーチサービスのWebサイトに埋め込むことで、アンケートの回答と紐付けることができます。先ほどの例であれば、商品への興味関心がわかる回答をユーザーIDにラベルし、「回答に合わせて適した広告を表示させること」も実現可能です。つまり、アンケート調査の結果と施策を直接関連付けることができるというわけです。○データに基づき、アンケートの回答を拡張するここでもう一つ問題が発生します。「Web上のアンケートを、自社のすべての顧客が行ってくれるわけではない」ということです。実際、アンケートに回答してくれる顧客は一部に留まります。つまり、ターゲットとなる顧客すべてにラベリングを行うことは不可能となるのです。そこで、アンケートを取れなかった顧客に関しては、アンケート結果が取れたユーザーとの類似性をもとに、「この顧客がもしアンケートに答えていれば、きっと顕在層だろう」というようにアンケートの答えを類推していきます。これは、過去のアンケートと比較し、ユーザーごとのビッグデータをWeb上において取得していることから実現する仕組みです。例えば、ユーザーによっては過去の検索キーワードを数万件というレベルでストックしています。その中から、アンケート結果の類推に役立つデータを抽出・分析することで、(アンケート上のデモグラフィックスから推測するより)はるかに高精度に、顧客の嗜好を予測することができます。この技術は、アドテクノロジーの分野においてオーディエンス拡張などのソリューションとして用いられており、そのコア技術として機械学習の分類機を活用しています。本連載の第一回で解説したディープラーニングも、今後はこのようなオーディエンス拡張のなかでどんどん取り込まれていくと考えています。最後に、実際にアンケート結果の拡張を行う際に使用されるデータを紹介します。下の図表は、インティメートマージャーがマーケティングアプリケーションの保険に関するアンケート結果とユーザーIDの連携を行い、アンケートの回答結果ごとに、回答者が普段Web上で検索しているキーワードを集計した結果の一部となります。この図から分かるように、顕在層は「医療」や「貯金」に関するキーワード群を検索しやすい傾向にあり、特に「入院」というキーワードの検索数は潜在層と比較し4倍以上の確率で検索しています。これらのキーワード群の違いから、アンケート結果のないユーザーであっても、アンケート結果を予測することが可能となるわけです。さて今回は、従来から存在するマーケティング手法「アンケート調査」において新たなテクノロジ―「DMP」を活用することで、調査結果と施策が直結しないというこれまでの課題が解決できることを紹介しました。これにより、マーケターは、顧客が商品にどれくらい興味関心を抱いているかを、性別や居住地、年収といったデモグラフィックスに基づきセグメントしていく作業から解放され、各顧客層に対しどのようなメッセージを伝えるかというクリエイティブな部分に集中できるようになるのです。○執筆者紹介山本 覚 (やまもと さとる)東京大学 博士課程 在籍時に松尾豊准教授の研究室で人工知能を専攻。その後、アイオイクス株式会社のLPO事業にプロダクトマネージャーとして参画し、導入者数400社超のLPOツール「DLPO」の全アルゴリズムを開発する。データマイニングを用いたWebページの改善実績は100社以上。「論理化されたものはシステムで処理し、人が人にしかできない営みに集中する環境を作る」ことを理念とし、データアーティスト株式会社 代表取締役社長に就任、現在に至る。
2015年09月08日
ファッションブランド「ANTEPRIMA(アンテプリマ)」では、パンダの形をした人気のワイヤーバッグに超ビッグサイズのGIANT PANDA WIREBAG「ジャイアント・パンダ・ワイヤーバッグ」が登場。9月12日(土)からアンテプリマ表参道ヒルズ店にて期間限定で受注販売される。何とも言えないたれ目具合で愛らしいこの姿に女心をくすぐられ、つい目を奪われてしまうパンダ・ワイヤーバッグ。「欲しい!でもちょっと大きすぎ?」それもそのはず、なんとこのバッグ、170cmという超ビッグなサイズなのだ。一般的な女性の身長を超えてしまうため、普通に携帯するのは無理!?既に発売されているスモールサイズのパンダ・ワイヤーバッグは、入荷しては完売を繰り返す人気商品。アイキャッチになるユーモアたっぷりのパンダ・ワイヤーバッグは、コーディネートのはずしアイテムとしてファッショニスタの間でも話題に。今回登場のビッグサイズも通常サイズのワイヤーバッグ同様に熟練した職人の手で手編みして作られている。ちなみに、販売はオーダーした人のためだけに特別に編み立てる完全受注制となっている。サプライズ・プレゼントや新居、新オフィスのお祝いなどにも使えそう?9月12日には、ジャイアント・パンダ・ワイヤーバッグと一緒に写真を撮ってTwitterまたはInstagramから「#アンテプリマパンダ」タグをつけて投稿すると、 抽選でパンダ・バッグがプレゼントされる企画も展開されるので、併せてチェックをしてみて。(text:Miwa Ogata)
2015年09月07日
ジーニーは9月3日、クロス・マーケティンググループのディーアンドエム(D&M)と共同で、「Geniee DMP」を用いたオーディエンスデータ提供サービスを開始した。同サービスは、リーチしたい生活者をターゲティングするための軸として、属性情報や意識データなどのオーディエンスデータを提供するものとなる。D&Mでは、アンケートを通じて許諾を取った会員のCookie情報に紐づいたさまざまな属性情報や意識データを取得しており、性別、年齢など基本的な属性情報に加え、趣味・嗜好などによるターゲット層の抽出が可能なユーザーデータを利用したオーディエンスデータの提供が可能。また、広告配信時のターゲティングだけでなく、自社で保有しているCRMデータへ結合することで顧客層の可視化にも利用できるという。
2015年09月04日
データアーティストは9月2日、同社の提供するLPOツール「DLPO」とPtmindが提供するデータアナリティクス「Ptengine」を連携したことを発表した。Ptengineは、PCやスマートフォン、タブレットなど訪問者が利用するデバイスを問わず、クリックや視線集中度、スクロール到着度といったデータを取得しサーモグラフィー表示する分析ツール。一方、DLPOは、A/Bテストや多変量テスト、ターゲッティングを行うことによりCVR向上を実現するLPOツールとなる。今回の連携により、訪問者の動線・目線の動きをより細かく把握し、デバイスや目的にとらわれることなく効果の高いWebサイトの構築と企画提案が可能になるという。具体的には、広告のリンク先としてDLPO タグを設置したリダイレクト元ページを用意し、A/Bテストを設定。ユーザーが広告をクリックし、リダイレクト元ページを訪問すると設置されたDLPO タグが読み込まれ、DLPO が各パターンページへのリダイレクトスクリプトを出力する。その際、Ptengine 解析用にURLへパターンを識別するためのパラメーターを付与。Ptengineが同パラメーターをもとに解析を実行する仕組みだ。
2015年09月03日
データ・アプリケーションは、統合EDI(電子データ交換)製品「ACMS(エーシーエムエス)シリーズ」の最新版(バージョン4.3)を販売開始した。発売するのは、企業内外のシステムおよびアプリケーションを連携するB2Bインテグレーション・サーバ「ACMS E2X(イーツーエックス)」、および、企業間のデータ交換を行う環境を構築するB2Bサーバ「ACMS B2B」の2製品。最新バージョンでは、プロセスや稼働記録、データ送受信要求などを監視し、プロセス障害やデータ送受信の遅延や滞留などを運用担当者にメール通知し、安定的なEDI業務を支援する「ACMS運用監視機能」を提供。また、2GB以上の大容量ファイル送受信を可能にするなど、通信機能や運用機能を強化しているという。「ACMS運用監視機能」は、監視や障害検知機能を強化するためオープンソースの運用管理ソフトウェア「Hinemos」を採用。ACMSの稼働記録やプロセス、データ送受信要求の滞留などを監視し、障害が発生した場合やしきい値を超えた際、運用担当者にメール通知する。また、Webベースの運用画面上で時間帯別の利用回線数やデータ送受信要求の滞留数などをグラフで確認できる。さらに、指定期間のデータ送受信の一覧や通信記録の集計しCSV出力できる。販売価格(税別)は、ACMS E2X 150万円 (基本機能)~、ACMS B2B 50万円 (基本機能)~、 ACMS運用監視機能(オプション)50万円~。
2015年09月03日
日本ティーマックスソフトは9月1日、ビッグデータ時代の大容量データに対応した高速化アーキテクチャと新機能を搭載したというRDBMSソフトウェアである「Tibero 6」を提供開始した。価格は40万9,700円(税別)から。同社は同製品の関連事業において、2~3年で2,500社への導入を目指すとのこと。新製品は、同社独自という「ハイパースレッド・アーキテクチュア」を用い、従来ボトルネックとなっていたプロセス、特に入出力制御プロセスを多重化したスレッド構造を持つとのこと。これにより、セッションが増加するほど安定した性能を発揮するといい、ビッグデータ時代の大容量データに対応できるものと同社はいう。また、処理の遅延を招く共有プールの断片化を最小限にするという「階層共有プール機能(方式)」により高速化を加速し、さらに「暗号データアクセス機能」によりってTDE(Transparent Data Encryption)列でも範囲検索をサポート、安全性と高速性の両立を実現したとしている。同製品の高速化共有プロセス構造では従来の他製品と比べ、“ハイパースレッド・アーキテクチュア”によるボトルネックの解消、大規模なリクエスト処理時の大幅な性能の向上、複数のワーキング・スレッドで同時に数千のリクエストの処理が可能といった利点があるという。なお同社は同製品の管理ソフトとして、「Tibero Manager」を2015年内に提供する予定だ。同ソフトは、トランザクション処理とリソース状況をリアルタイムで監視するパフォーマンス管理機能とTibero DBMS Admin機能を、Tiberoに組み込んだGUIの統合ツールとして提供するもの。Tibero 6のエディションとプロセッサあたりのライセンス価格は、「Standard Edition Lite」が40万9,700円(税別)から、「Standard Edition」が123万6,400円(同)から、「Enterprise Edition」が335万5,900円(同)から。年間サポート料は、ライセンス価格の15%。対応OSは、HP-UX 11i v3/11i v2、Oracle Solaris 11/10/Solaris9、IBM AIX 7.1/6.1/5.3、Red Hat Enterprise 7/6/5/4、Windows 7、Windows Server 2008/2012。同社は同製品の提供において、大規模システムにおける安定性や高速性から、特にクラウド・サービス事業者やクラウド・インテグレータといったクラウド・サービスを普及させている企業との連携を強めていくという。この事業展開においては、2015年4月に発表したTibero事業拡張のための新たなパートナー制度である「Japan Partner Program(ジャパン・パートナー・プログラム)」)を利用しながら、全国で研修やサポートの拡充・パートナー企業の増加・販売チャネルの拡大を進めていくとのこと。他にも、クラウド・サービス事業者や各種インテグレータとのOEM提供による事業展開も検討していく意向だ。
2015年09月02日
伊藤忠テクノソリューションズ(CTC)は8月31日、アサヒビールと共同で飲食店向けのビッグデータ分析についての協業を開始したと発表した。同サービスでは、米Applied Predictive Technologies(APT)のクラウド型予測分析ソフトウェア「Test & Learn」を使用。飲食店が導入を検討している施策について、POSデータやAPTが独自に調査する地域特性に関連するデータから、施策に適切な実験店舗を割り出し、売上や利益、来店客数、客単価などへの施策の貢献度を実験を通して算出する。これにより、新商品の導入から割引キャンペーン、広告展開、店舗のレイアウト変更、従業員の研修など、さまざまな施策で活用できる。今後アサヒビールは、飲食店の収益改善や経営効率の向上に向けてビッグデータ分析による店舗支援サービスを拡充していくという。また、CTCでは小売業者や消費財メーカなどに向けてサービスを展開していく予定だ。
2015年08月31日
アクシバルは8月28日、意識・購買・メディア接触データを統合した同社独自のデータベース「3Dデータベース」の意識データを用いてユーザーを分類した新しいDMP「MindDMP」を開発したと発表した。これまでデジタルメディアを使ったターゲティングは、サイトに登録された性年代情報を使った「デモグラフィックターゲティング」、過去のサイト訪問履歴などの行動データを使った「行動ターゲティング」、自社サイトへの訪問履歴を使った「リターゲティング」が使われてきた。これに対し、MindDMPはターゲティングの方法に、ユーザーがどのような価値観を持っているかという“人となり”の視点を加えた。リターゲティングでは、顕在化した顧客をターゲティングするが、MindDMPはまだ需要が顕在化していない見込み顧客を判別する視点として利用できる。「何を購入しているのか(購入履歴)」がログで分析できる「3Dデータベース」を使って、自社商品のユーザーの意識・価値観の特徴から見込み顧客の意識・価値観を特定。特定した意識・価値観を持った人に広告配信を可能にするのがもっとも大きな特徴となっている。3Dデータベースでは、生活者が「何を見ているか(メディア接触)」ということもわかるため、これまで分断されがちだったマスメディアとデジタルメディアのプランニングを統合することも可能になるという。
2015年08月31日
オプティムは8月27日、ドローン、IoT、ウェアラブルのデジタルビッグデータを統合管理し、「ビッグデータ解析」、「画像解析」、「遠隔制御」を行うドローン対応ビッグデータ解析プラットフォーム「SkySight」を発表した。同プラットフォームは、スキャニングデータ、センシングデータ、デジタル作業ログデータを組み合わせて、複合的な情報による判断や新たな発見をすることが可能。また、過去データをさかのぼって解析を行うことも可能であり、経過比較による情報の判断や新たな発見を行うことを可能とする。また、ビッグデータとして蓄積したデジタルデータに対して、各産業の専門的な知見(アルゴリズム)を組み込むことで、自動解析を実施することも可能。さらに、同社の有するリモートテクノロジーにより、ウェアラブルデバイスを遠隔地から制御を行うことも可能としている。具体的な機能としては、「ドローンによるスキャニングデータのマッピング」、「ウェアラブルデバイスによるデジタルデータのマッピング」、「各種センサデータのマッピング」、「ドローンによるスキャニングデータの画像解析と異常検知」などが挙げられるという。なお、同社は同日、佐賀大学農学部ならびに佐賀県生産振興部と、佐賀県が世界1位のIT農業県となることを目指し、連携協定を締結。この取り組みの中で、デジタルスキャニングビッグデータを活用した、農業ITの研究・実践を行っていくとしている。
2015年08月28日
オプティムは8月27日、ドローン対応ビッグデータ解析プラットフォーム「SkySight」を発表した。Skysightは、ドローンによる空撮だけでなく、ドローン、IoT、ウェアラブルのデジタルビッグデータを統合管理し、「ビッグデータ解析」「画像解析」「遠隔制御」を行うプラットフォーム。スキャニングデータ、センシングデータ、デジタル作業ログデータを組み合わせることで、複合的な情報による判断や新たな発見を可能とし、過去データをさかのぼって解析できるため、経過比較による情報の判断なども行える。また、ビッグデータとして蓄積したデジタルデータに対して、各産業の専門的な知見(アルゴリズム)を組み込んで自動解析できるほか、同社のリモートテクノロジーにより、ウェアラブルデバイスを遠隔地からも制御することができる。なお、同社と佐賀大学農学部、および佐賀県生産振興部は8月27日に連携協定を締結し、デジタルスキャニングビッグデータを活用した、農業ITの研究・実践を行っていくという。具体的には、佐賀県が保有する農業試験研究機関の圃場および、佐賀大学が保有する圃場のすべてに、ドローンを活用したデジタルスキャニングを実施する。スキャンしたビッグデータを解析し、病害虫の早期発見や生育管理を手軽に行えるようになることで、人材不足の解決と効率的な農作業(施肥、雑草・害虫・鳥獣害防除、収穫)を目指すとしている。
2015年08月28日
はじめまして、データアーティスト 代表取締役の山本覚です。ここ10年ほど、ビジネスにおけるデータサイエンスに携わっています。今回から、「想像力を掻き立てるデータサイエンス」と題して、マーケターに役立つようなデータ分析・データ活用についてお話をさせていただきます。さて、読者のみなさんは「データサイエンス」と聞いて、どのようなイメージを持つでしょうか。一般的には、「ロジカルでちょっと堅苦しくて、"想像力"や"クリエイティブ"とは縁がないもの」と想像する方が多いのではないでしょうか。しかし実際は、「煩雑な業務を自動化し、アイディアを生み出すなど "人間にしか出来ないこと" に集中する時間を作ることができる手段」であると言えます。いわば、想像力を掻き立てるためのツールだと言っても過言ではありません。本連載では、マーケターの皆さんに向け、データサイエンスの新潮流となる「ディープラーニング」を活用することで、施策・戦略の考案やクリエイティブイメージの発案などに注力できるということをお伝えできればと思います。○そもそも、ディープラーニングとはなんだ?!2006年からジェフリー・ヒントン氏らによって研究されている「ディープラーニング」は、2013年ころから「なんかgoogleが、その、猫の顔を、自動的に、あれでしょ?」というような具合で、都市伝説的に有名になりました。そもそも、この「ディープラーニング」とは何でしょう。ネットで調べればすぐ出てくるのですが、端的に言うと「脳の中の神経細胞となる"ニューロン"の繋がりをシミュレートしたもので、ニューロンがつながってできた層をディープに重ねましたというもの」です。「うーん? つまりどういうこと?」と思われるかもしれません。要は、ニューロンのつながりを最適化する計算方法がスマートになったため、ニューロンの層をディープに重ねるということ (ディープラーニング)を実現したということです。それでは、もっと噛み砕いて説明します。○人間の10年分の作業を一瞬で行う?!このディープラーニングの何がすごいのか。それは、「データを見せるだけで、データの特徴を勝手に学習してくれる」という点です。これは、これまでの人工知能ではできないことでした。猫の顔を学習する際のプロセスの違いを例に、具体的に説明したいと思います。従来の人工知能では、猫の画像を直接人工知能にかけることができず、事前に目・鼻・口の位置を認識するプログラムを作成し、人工知能にかける必要があります。つまり、目や鼻、口それぞれ個別に認識させてからでなければ、人工知能の力を発揮できない状態でした。これは猫だけではなく、例えばポストを認識させたい場合には、投函口などポストらしさを表すものを認識させるプログラムを作らねばならない ―― 認識させたいものに合わせた前準備が必要とされたわけです。このように、従来の人工知能は、データの変更に対し、膨大な手間がかかります。加えて、人によって"猫らしい"と考える特徴が異なるため、特徴を考える人の手腕次第で認識の精度に著しく影響が出るという課題がありました。特徴の判断が属人化するため、人工知能の性能が高くても「特徴を抽出する人の限界」を超えられないのです。一方、ディープラーニングの場合は、猫の画像に対し、特徴を抽出する前処理が必要ありません。"猫らしい"特徴の抽出も含め、勝手に学習をしてくれるため、人工知能に直接データを渡すことが可能となります。しかも、人間があれやこれやと考えた場合と比較し、圧倒的に高い精度を出すことが可能です。とある画像認識の大会では、人間がさまざまな特徴を考えて1年に1%ずつ、精度をこつこつ上げて来たのに対し、特段前処理の工夫をせずに最初からディープラーニングを使った場合では、10%も精度が改善したという実績があります。すなわち、10年分の改善が一瞬で行われたというわけです。「人間がデータの特徴を考えなくて良い (前準備なく活用できる)」ということは、マーケターにとって非常にありがたいことではないでしょうか。例えば、ディープラーニングにより、「自社サイトの画像と類似する画像をWebから自動で探し出す」ことが可能となり、マーケターは「ABテストを継続的に行うPDCA自動化ソリューションの考案を行う」というように、マーケティングの話だけに集中することができるようになります。まさにこれこそが、想像力を掻き立てるデータサイエンスです。もし、データの特徴を人間が考えていた場合、そのために多くの時間がとられることになります。「うちのサイトには猫の画像が多いから猫の特徴を調べよう!」「耳のとんがり具合を強調したほうが猫の検出程度が高くなります!」「大変です!! 来週から急きょ犬の特集が始まります!!」「イヌ・・だと・・・?」というようなことになってしまうかもしれません。○順番に関する情報全般に適応できる……かも?!さて、このようにすごい技術であるディープラーニングですが、実際には、どのような領域で活用されているのでしょう。研究が始まった2006年以降の「ディープラーニングに関する論文」2,586本をすべて調べてみました。下の図の左側にある花火のようなものは、内容の似ている論文同士をどんどんつなげていき、つながりが密になっている所をグルーピングした「学術俯瞰マップ」と呼ばれるグラフです。このグラフを用いることで、ある研究領域にどのような詳細なテーマが存在するか、さらにそれぞれのテーマに含まれる論文数や、テーマ同士の近さなどが分かります。このグラフに出てくるグループ(赤は定性データ対応、黄色は時系列データ対応など)は、さまざまな研究テーマに対応しているのですが、今回は青のグループに注目してください。青のグループはディープラーニングが得意とする「特徴の自動抽出」のグループです。さらに、この特徴の自動抽出のグループを同様の手法でグループ分けしたところ、画像認識に関するグループが半分以上の割合を占めました。一方、マーケティングに対する直接的な応用例のグループなどは現状見受けられません。これは、「まだ研究されていない」ということを意味します。このままディープラーニングの行く末は、「猫の顔分析マシーン」となってしまうのでしょうか……?ここで私が注目したのはタンパク質の構造分析です。タンパク質というのは、20種類以上あるアミノ酸が順番につながった紐のようなもので、最後にくるくるっと折りたたまれて機能を発現します。「タンパク質の分析がマーケティングの何の役に立つのだ?」と思われそうですが、マーケターは日々、「サイト内で○のような行動をした人は、××を買いやすい」ということを考えていますよね? これは、「アミノ酸がつながる順番からタンパク質の形がわかる」というシチュエーションと似ていませんか?ユーザーの行動パターンを分析する中で、「最初に見たページが一番大事なのでは?」「いやいや、直近の3ページが大事だ」「待て、このページを見たあとで、あのページを見たのでは印象が違うはずだ」というマーケターそれぞれの意見を、エンジニアが頭を捻って対応することは多いと思います。ディープラーニングは、こうした悩みを解消できます。ゴールとなる「好みの商品 (タンパク質の形)」と、ゴールを決めるWebページの閲覧順序(アミノ酸の順番)をデータ化するだけで、ユーザー行動のパターン分析は格段に楽になります。そのあとは、ディープラーニングがWebページの閲覧順序から、ユーザーの好みの商品を自動でさがしてくれる、かもしれません。○執筆者紹介山本 覚 (やまもと さとる)東京大学 博士課程 在籍時に松尾豊准教授の研究室で人工知能を専攻。その後、アイオイクス株式会社のLPO事業にプロダクトマネージャーとして参画し、導入者数300社超のLPOツール「DLPO」の全アルゴリズムを開発する。データマイニングを用いたWebページの改善実績は100社以上。「論理化されたものはシステムで処理し、人が人にしかできない営みに集中する環境を作る」ことを理念とし、データアーティスト株式会社 代表取締役社長に就任、現在に至る。
2015年08月25日
日本ヒューレット・パッカード(日本HP)は8月24日、SaaS型ITサービス管理ソリューション「HP Service Anywhere」にビッグデータを分析する機能を拡張したと発表した。「HP Service Anywhere」は、オンプレミス型ITサービス管理ソリューション「HP Service Manager software」をベースに、IT運用管理に必要不可欠な機能をSaaS型で提供するもの。今回、同社のビッグデータプラットフォーム「HP Haven」の技術が「HP Service Anywhere」に組み込まれた。これにより、HP Service Anywhereにおいて、自然検索、ユビキタスな知識の提供、トレンド分析機能といった機能が提供可能になり、意思決定にビジネスデータを活用できるようになる。また、ビジネスに関する体系的な洞察をとらえ、企業やエンドユーザーがより良い解答をより迅速に見つけることを可能にする、ソーシャルIT管理機能を提供。そのほか、ビッグデータを活用した調査、強化されたポータル、最適なライブサポート、新たなアイディエーションモジュールを支援し、IT部門とのコラボレーションが可能な作業環境を創出する。「HP Service Anywhere」の価格は、最小構成で268万5000円から(15ユーザー、12カ月から)となっている。
2015年08月24日



















