
相模原で起きた障害者殺傷事件に寄せて出典 : 月26日未明、神奈川県相模原市の障害者施設「津久井やまゆり園」で元職員の男が刃物を持って侵入して入所者らを次々に刺し、19人が死亡、26人が負傷する事件が起こりました。逮捕された容疑者は、「障害者は不幸を作ることしかできません」「安楽死にすればいい」などといった発言を犯行前後にしており、私も、知的障害のある子を持つ母として、非常に悔しい思いで、涙が出てしまいました。テレビやインターネット上でも、この容疑者の言動や人格の異常さを非難する声が多く見られますが、そうした意見を目にするなかで、私にある問題意識が浮かんできました。この犯人を「異常な心理を持つサイコパス」とし、“別世界の人“と見てしまうだけでよいのだろうか?実際にこんな事件を起こさなくても、同じような考え方の根っこを、まだまだ世間や私たちは持っていないだろうか?そしてそのような考え方を子どもたちが持つきっかけを、私たち大人が与えてはいないだろうか?今回の記事では、『1人でできる子に育つテキトー母さん流子育てのコツ』の著者、立石美津子が、障害のある人への排除の問題と、インクルーシブな共生社会に向けた考え方をお話します。世間にまだまだはびこっている、「障害者差別」の考え方出典 : 近年は障害者差別解消法の施行やインクルーシブ教育の浸透によって、以前よりも障害者に対する偏見は改善しているようにも見えます。しかし、障害者に対する差別的な姿勢は、世間からまだまだ消えていないように私は思います。今回の事件の報道のあり方にもそれが表れているでしょう。今回の事件で、殺された被害者の実名や写真が何日経っても報道されないことについて、私は疑問に思っていたところ、以下のような記述を発見しました。県警は26日の事件発生以降、被害者名を「A子さん19歳」「S男さん43歳」などと記号化して公表している。非公表の理由は「(現場が)障害者施設で障害者という条件のため。遺族による強い希望もあり、そのような判断をした」という。私はここで、「何がなんでも被害者名を報道すべきである」ということを言いたいわけではありません。被害者名が公開されれば、自宅に報道陣が押し寄せ、その友人や近所の人にも取材が行き、出身の学校まで報道陣が押し寄せます。ご遺族の方が公表を拒否したというのも、無理はないことでしょう。ですが、今回の神奈川県警の発表で気になるのは、事件が”障害者施設で障害者という条件”で起こったため、実名を非公表にしたという、その理由付けです。障害者施設での事件だからということを理由として、通常とは異なる「例外対応」をすることそれ自体が、障害者を特別扱い、あるいは差別しているように思います。本来なら、事件報道における実名・写真の公表が、被害者の障害のある無しに関わらずどうであるべきかを考えた上で、犠牲者一般に対して同様の原則を適用すべきでしょう。こうした報道姿勢にも、「障害者の生きる世界は、自分たちとは違う特殊な世界」という差別の考えが、無意識下に働いてはいないだろうかと、懸念を覚えます。大人の無意識な言動が、子どもの考えの根っこをつくる出典 : こうした私たち大人がつくりだす障害者に対する差別的な姿勢は、子どもの考え方にも大きく影響していると思います。私は、知的障害のある自閉症の息子を育てる母として、また学校や塾の教師として、さまざまな先生、保護者の方々と関わってきました。子どもたちが最初に障害のある人とかかわる場面は、多くの場合学校だと思います。残念なことに、「障害のある子どもが一人でもいると通学、通園させたくない」と望んだり、特別支援学級が併設されていない小学校をあえて選ぶ保護者の方がおられる現状を、私は見てきました。「我が子を勉強させるために通わせているクラスに障害のある子がいて、学習環境を妨害されたら困る」とその方が思うのは、親心としてはある種自然なことかもしれません。事実、障害のない子が授業中に迷惑をこうむってしまう場面はあると思います。しかしだからといって、障害児の存在そのものを否定する言動や、「障害児は絶対排除」という姿勢を親が子どもの前で見せてしまうと、今回の犯人と同じ考え方の種を植え付けてしまうのではないでしょうか。「障害者は絶対排除」とまではいかなくとも、障害者に対する差別的な考えを、親も無意識のうちに子どもに植え付けてしまう可能性は十分あります。たとえば、我が子を褒めようとするときも、出来ていない友達と比較して「あの子は努力しなかったから○○になったのね。その点あなたは頑張っているから○○できたね」などと言えば、“弱者を馬鹿にする考え”がついてしまうのです。相模原で起きた事件の容疑者も、26年前は人の子として生まれ、可愛い天使のような赤ちゃんだったのでしょう。容疑者がどのような環境で幼少期を過ごしたのかは定かではありませんが、少なくとも私たち大人の考え方は、純粋な子どものその後の価値観に大きく影響しているのです。人間は全員が健常者として生まれ育つわけではない出典 : 私が特別支援学校の教員免許をとるとき、授業でこんな話を教授から聞いたことがあります。「鉢植えに100個の種をまいたら全部同じようには成長はしない。種のまま芽が出ないこともあるし、途中から成長スピードが変わるもの、曲がってしまうものがある。人間も生物だから同じこと。全員が健常者として生まれ成長するわけではない。」これは「1人ひとり成長の凸凹はあって当然」というメッセージなのだと解釈しています。私は一人の親として、また教師として、いつもこの言葉を胸に留めています。学校という教育の現場で、障害のある子どもとない子どもが一緒に過ごすことで、「世の中には色んな人が存在するんだ」ということを子どもたちは身をもって体験することができると私は思っています。そのような環境で、「背が高い子、低い子、眼鏡をかけている子、かけていない子、色んな人がいるよね。走るのが早い子、遅い子、給食をおかわりする子、しない子。人間はみんな一人一人違っていて、得意なこと苦手なことがあります。○○君はじっと座っていることが苦手で、歩くことが得意なのよ。」というように、大人が子どもに働きかけていけば、子ども同士が関わりあうなかで、「多様な人が共に生きること」「鉢植えの中には色々な種があること」を学んでいくのです。誰だって障害者になりうる。だから、社会でもっと支えあおう出典 : できれば我が子には障害のない方が良い、と願うのは親として自然なことかもしれません。新型出生前診断でダウン症児だと分かると、90%の妊婦が中絶をしているという現実もあります。しかし、新型出生前診断で分かる障害は一部の障害だけで、視覚障害や聴覚障害、自閉症などの発達障害はわかりません。さらに、出産時の事故で子どもが脳性まひになることもあれば、障害なく生まれてきても、交通事故に遭ったり病気で脳にダメージを受けたりして、障害児になる可能性もあるわけです。また、親を含めた大人自身が、事故や病気、鬱病や統合失調症などの精神疾患によって、障害者になる可能性だってあります。そんなとき「あなた(の子ども)の存在は大変な税金がかかり迷惑をかけている。最初から生まれていなければよかった」と言われたら、どのように感じるでしょうか?生きている限り、誰がいつ障害者になってもおかしくはありません。だからこそ、同じ鉢植えの中の者同士、互いの存在を認め合い、支え合って生きていく必要があります。障害者を“自分とは関係のない人”として、そして今回の事件を“異常な人がやったこと”と他人ごとにせず、私たち自身の障害者に対する考え方を、もう一度見直す必要があると思います。Upload By 立石美津子一人でできる子になるテキトー母さん流子育てのコツ
2016年08月08日
Hobby’sはこのほど、クラウドファンディングプラットフォーム「READYFOR?」にて、神奈川県相模原市・東林間に4月オープン予定の「大人が子供に戻れる秘密基地! ミニ四駆Cafeドラゴンバック」のプロジェクトを開始した。同社によると、現在、ミニ四駆の"第3次ブーム"が到来しているという。2012年にはミニ四駆メーカー・タミヤ主催の大会「ジャパンカップ」が13年ぶりに再開され、2014年時点では全国で開かれた公式大会の来場者数も延べ3万人を超えた。同社が企画した「ミニ四駆Cafeドラゴンバック」では、"大人が子供に戻れる空間を目指す"という。店内にはタミヤの公式大会の模擬コースを用意し、月2回ほどのコース変更も予定している。タミヤ公式施設である"ミニ四駆ステーション"への登録も申請中とのこと。コース設備の内訳としては、「ミニ四駆 ジャパンカップ ジュニアサーキット」「ミニ四駆 ジュニアサーキット スロープセクション」「ミニ四駆 ジャパンカップジュニアサーキット バンクアプローチ20」「EXDT01 デジタルターン」の設置を予定している。今回のクラウドファンディングで募集した資金は、カフェ店内の改装費用およびミニ四駆コースの購入費用として利用するという。目標金額は50万円で、支援額としては、3,500円、1万円、5万円、10万円のプランを用意。支援者には、カフェの無料券やミニ四駆キットの進呈、店舗の貸切権、額装した感謝状などのリターンを用意している。クラウドファンディングは、3月18日の23時まで実施予定。店内では、本体キットやパーツの販売、工具無料貸し出し、充電サービス電源を完備。また、フリードリンクバーを用意する。初心者も楽しめるような料金パックも用意する予定とのこと。営業時間は11時から23時までで、席数は30となる。
2016年02月05日
SC15の展示場で、建築の足場のような鉄パイプで3階建ての櫓を作っていた会社があった。「Tezzaron」という会社で、 3階に上がると、展示場全体が見渡せるとブースの前を通る人を呼び込んでいた。きわものかと思ったのであるが、なかなか技術的に面白いものを作っていた。TSVを使った3D実装はHBMやHMCで実用化されつつあるという状況であるが、Tezzaronの技術はTSVよりもずっと高密度の接続ができ、性能的により良いものが作れるという。また、最大18枚のチップを積み重ねることができるとのことである。次の図のようにメモリチップとコントロールチップを積層する点は、HBMなどと似ているが、Tezzaronのスタックのメモリチップはメモリアレイだけを搭載し、デコーダやセンスアンプなどのメモリの周辺回路はコントロールチップに置かれている。このように周辺回路を含まないことでメモリチップを小さくする、あるいは、より多くのビットをメモリチップに詰め込める。周辺回路を別チップにすると、一般に、メモリチップとの接続本数が増えたり、配線が長くなったりするという問題がでるが、Tezzaronのチップ間の接続はTSVよりずっと小さく、チップ内の接続とあまり変わらず、問題にならないという。このように要素別に分解した形でRAMを作るので、Tezzaronは、Dis IntegratedなRAMということで、「DiRAM4アーキテクチャ」と呼んでいる。通常のTSVは、ウェハを貫通する接続に銅を使い、アグレッシブなものでも、直径が5μm、長さが50μm程度である。これに対してTezzaronの接続はタングステンを使い、直径が1μm以下で長さも10μm以下と短い。タングステンによる接続はLSIチップのシリコン層に作ったMOSトランジスタと第1層のメタル配線を接続するのに広く用いられており、微細な接続ができる確立した技術である。しかし、10μm以下(6μm程度という話も聞いた)の接続しかできないので、ウェハをそれ以下の厚みにすることが必要となるという。平面方向で見ると、通常のTSVでは40μm×50μmの面積に1本の接続であるが、Tezzaronのやり方では3μm×3μmに1本と200倍以上(図では66倍以上と書かれている)の密度の接続ができる。TSVの場合はウェハに大きな穴を空けてTSVを作ることによる機械的なストレスがピッチを決めるが、Tezzaronの方法はストレスはなく、位置合わせの精度でピッチが決まっているという。通常のTSVの場合は、ウェハを製造し、プローブテストで検査し、良品のチップの位置を覚えて置く。そして、ウェハを50μm程度の厚みまで研磨して、それを切断してチップにする。良品のチップを選んで積層を行ってパッケージに入れ、バーンインやテストを行うという手順で製造される。10μm以下という薄いウェハを実現するため、Tezzaronの場合は、ある程度の厚みのベースウェハ(Supporting Substrate)からスタートし、次のウェハの接合を行なったら、一番上のウェハを薄く研磨するという手順を繰り返す。このようにすれば、研磨する対象はベースウェハより厚いものとなり、10μm以下という極薄の壊れやすいウェハを研磨するという必要は無くなる。ただし、ウェハ1枚ごとに、積層、研磨を繰り返すことが必要になる。なお、接合にははんだなどは使わず、位置を合わせて200℃程度に加熱すると接合されるという。そして、必要な枚数のウェハの積層が終わったら、プローブテストを行い、ウェハを切断して良品のスタックを選別してパッケージに入れ、バーンインやテストを行う。TSVのプロセスでは、メモリウェハは1枚ずつ検査されて、最後のスタックを作る段階では不良のチップはスタック組み立てから除外される。しかし、Tezzaronの場合は、メモリウェハ間を接続する直径1μmの電極は小さすぎてプローブを接触させてテストすることはできない。また、ウェハ同士を接合するので、不良チップがあってもそれを除外することができない。したがって、このようなやり方では良品のスタックの歩留まりは非常に低く、実用にはならないというのが一般的な見方であった。これに対してTezzaronは「BiSTAR(Built in Self Test and Repair)」というやり方を考案した。BiSTARは、ウェハ間の接続が高密度で短い接続で行えることを利用して、メモリチップの中の不良があるサブアレイを切り離して、良品のサブアレイで置き換える。この置き換え回路は、あらかじめチップに組み込んで置く。ウェハ間の接続が短いので、このスペアのサブアレイは同じチップ内にある必要はなく、他のウェハに有っても良い。このため、スタックするウェハの枚数が増えるにしたがってスペアのサブアレイの数も増えるので、次の図に示すように、良品のスタックが得られる確率はスタックのウェハ枚数が増えるにしたがって高くなるという。Tezzaronの1ウェハごとの接合と研磨によるウェハの薄型化は、確かに製造工程を複雑にしコストアップの要因となるが、TSV接続に比べて100倍以上の高密度の接続が実現できるこのテクノロジを使えば、10nmテクノロジを使わないと実現できない程度の高密度のメモリを45nmテクノロジで実現できるという。したがって、組み立て工程がある程度コストアップになっても、メモリ容量の点で差別化した製品が作れるので、全体としてはメリットがある。また、性能が上がることによるメリットもある。ネットワークプロセサは高速のメモリアクセスを必要とし、400Gbit/sのパケット通信の処理を行うためには、パケットバッファとして4GbitのDRAMで1TB/sのアクセスを必要とし、576Mbitで12BT/sのテーブルアクセスと576Mbit/sで5TB/sのアクセスができるSigmaQuad IIIeメモリが必要であるという。このためには30個のDDR3 DRAMと12個のRLDRAM3チップと4個のSRAMを必要とするが、Tezzaronの3D積層DiRAM4を使えば1個のスタックで済んでしまい、26mm×32mmのインタポーザに載ってしまう。このため、装置全体では、Tezzaronの3D積層のコストアップを上回るコストダウンが実現できるという。
2016年01月06日
SC15の論文の採択率は20%強で、SCで論文を通すのは、なかなか、大変である。その関門を通って、今回のSC15で発表された日本の大学の論文発表は2件である。なお、論文の著者は全員が1つの機関の人だけという方が珍しく、世界中のあちこちの機関の人が1つの論文の共著者となっているという論文の方が多い。このため、何が日本の大学の論文かという明確な基準はなく、多分に筆者の恣意的な判断に依っている。SC15で採択された2件の論文の内の1件は、電気通信大学(電通大)の三輪准教授と東京大学(東大)の中村教授の共著の「Profile-Based Power Shifting in Interconnection Networks with On/Off Links」という論文で、もう1件は、九州大学(九大)の稲富准教授が第1著者で、同大、アリゾナ大学、ローレンスリバモア研究所、東大、京都大学(京大)、富士通の人たちが共著者に加わっている「Analyzing and Mitigating the Impact of Manufacturing Variability in Power-Constrained Supercomputing」という論文である。主に若い研究者の研究発表の場として設けられているポスター発表は、RIST(高度情報科学技術研究機構)と北海道大学(北大):GPU Acceleration of a Non-Hydrostatic Ocean Model Using a Mixed Precision Multigrid Preconditioned Conjugate Gradient Method東北大:An Approach to the Highest Efficiency of the HPCG Benchmark on the SX-ACE SupercomputerA Real-Time Tsunami Inundation Forecast System for Tsunami Disaster Prevention and Mitigation会津大学:Parallelization of Tsunami Simulation on CPU, GPU and FPGAs筑波大学:Large-Scale MO Calculation with GPU-accelerated FMO Program東大:Scalable and Highly SIMD-Vectorized Molecular Dynamics Simulation Involving Multiple Bubble NucleiDevelopment of Explicit Moving Particle Simulation Framework and Zoom-Up Tsunami Analysis System東工大:Out-of-Core Sorting Acceleration using GPU and Flash NVMDesign and Modelling of Cloud-Based Burst BuffersMulti-Level Blocking Optimization for Fast Sparse Matrix Vector Multiplication on GPUsDesign of a NVRAM Specialized Degree Aware Dynamic Graph Data Structure電通大:Memory Hotplug for Energy Savings of HPC systems大学ではないが、「JAEA Optimization of Stencil-Based Fusion Kernels on Tera-Flops Many-Core Architectures」を含めると、全体では日本の発表は13ポスターであった。中では4件のポスター発表を行った東工大が最多で、すべてのポスター発表に松岡先生の名前が載っている。SC15での日本の大学のブースは15(ただし、東京大学は3つのグループがそれぞれブースを出展)であった。なお、埼玉大学のブースは会場中央に近い良い場所にあり、会場の端に押し込められた他の日本の大学のブースと離れた場所であったために見逃してしまった。埼玉大学の皆様、申し訳ない。また、SC15では埼玉大学の隣にVR Study Meetingのブースがあった。前回の展示では、VR Study Meetingは埼玉工大、埼玉大、女子美大、東海大、中央大のチームと書かれており、日本の大学の展示に含めるべきであったが見落とした。大部分の大学は前回もブースを構えた常連であるが、前述のように、1件のポスター発表を行っている会津大学も過去に3回展示を行っている。初出時に、新たに参加と記述してしまったが、前回、展示がなかったので、勘違いしてしまった。○各大学の展示ブース今回から初参加の会津大学は平成5年に創立された県立の4年制大学で、コンピュータ理工学専門でその他の学科はないという珍しい大学である。当初は学部だけであったが、その後、平成9年に修士課程、平成11年に博士課程を開設している。日本の大学では最大の600平方フィートのブースを構えるOakleaf Kashiwaアライアンス。東大の平木研究室も毎年ブースを構える常連である。平木研はData Reservoirというプロジェクトで、遠距離の超高速通信を可能にする技術を研究している。今回は、SC15の会場に2台のPCを設置し、テキサス州オースチンから東京までの100Gbit/sの回線を使い、東京折り返しで2台のPC間でのデータ伝送実験を行った。通常のTCPを用いると、データ伝送速度は29Gbit/s(理論値の97.7%)であったが、超高速通信のために開発したLong Fat TCPを使うと73Gbit/sのデータ伝送が行えることを実証した。これは単一のTCP通信によるデータ伝送速度としては世界記録だそうである。日本の大学で発表ポスター数最大、TSUBAME-KFCのK80 GPUへのアップグレードでGreen500 2位を獲得した東工大は、Oakleaf Kashiwa Allianceと並ぶ600平方フィートのブースを構えていた。SC15で論文が採択された九州大学のブースである。椅子に座っている黒い服の人物が、論文の第1著者の稲富准教授。
2015年12月30日
SC15において、将来のメモリに関するパネルディスカッションが行われた。モデレータはMicron TechnologyのRichard Murphy氏、パネリストはIntelのSekhar Borkar氏、NVIDIAのBill Dally氏、ARMのWendy Elasser氏、AMDのMike Ignatowski氏、IBMのDoug Joseph氏、ノートルダム大学のPeter Kogge教授、そしてMicronのSteve Wallach氏という顔ぶれである。モデレータからは以下のような質問が出されていて、パネリストは、自分のポジションを述べるという形式でパネルディスカッションが行われた。Exascaleとそれ以降にはどのようなメモリが良いか?コアあたりのメモリ量が減っているが、どうすれば良いか?メモリのインタフェースとして、HMCのような高速シリアルとHBMのような低速ワイドのどちらが良いか?PIM(Processing-In-Memory)アプローチの影響は?○MicronのSteve Wallach氏のポジションWallach氏はConvexの創立者の1人でCシリーズスパコンやExemplarスパコンを開発した。同社はHPに買収され、Exemplarの設計はHPのSuperdomeサーバに受け継がれた。その後、Conveyという会社を起こし、FPGAベースのスパコンを開発していたが、2015年4月のMicronによるConveyの買収に伴いMicronに移っている。Wallach氏は、2008年にCray賞を受賞している。メモリチップを3D積層するHBMやHMCが出てきて、メモリバンド幅は改善された。また、3D XPointのような高速の不揮発性メモリも出てくる。これを使えばワンレベルの仮想アドレススペースのメモリが作れるようになる。将来的には、計算処理とメモリの集積が可能になるが、どのような形で、どのようなアーキテクチャが良いかは今後の検討課題である。Exaバイトのメモリをアドレスするには60bitを必要とする。大容量の3D XPointのようなメモリが出てくると、記憶容量が増大し、Exaバイトを超えるメモリを搭載するシステムが出てくる。そうなるとPGASのアドレススペースとしては64bitでは不足で、128bitアドレスが必要になってくる。そうなると上位64bitをオブジェクトIDとし、下位64bitをバイトオフセットとするような形になると考えられる。○IntelのSekhar Borkar氏のポジション次の各グラフの8本の棒グラフは、左からSRAM、DRAM、Flash、PCM、STT、FeRAM、MRAM、RRAMを表している。そして、左上のグラフは、各メモリが作られているテクノロジノードのハーフピッチを示しており、より微細なプロセスで作られているSRAM、DRAMとFlashが成熟度が高い。その右のグラフはメモリのセルサイズを示したもので、面積の小さいDRAM、Flash、PCMが良い。右端のフラフはビット密度を示すもので、DRAM、Flash、PCMが良い。下の段の左端はReadとWriteのサイクルタイムを示すグラフで、SRAMとDRAMが高速である。その右は、ビット当たりのReadとWriteのエネルギーを示すグラフで、メモリで必要とされる大容量が実現でき、エネルギーが小さいのはDRAMとFlashである。その右は寿命のグラフで、FlashやPCMは寿命に問題がある。これらの特性をスコアカードにまとめたものが次の図で、容量、速度、エネルギーの点でバランスが取れているのはDRAMである。FlashとPCMはアクティビティが低いところでは大容量のメモリとして使えるという評価となっている。STT、FeRAM、MRAM、RRAMは、まだ、実用には疑問があるという評価である。Exascaleとそれ以降のメモリテクノロジとして使えるものはというモデレータからの事前の質問の回答はDRAM、NAND、PCM。3D XPointなどを指すと思われる飛躍的な進化の兆候は見られるがExascaleには間に合わない。また、DRAMは、エラーに関してはNANDのように管理することが必要という。これはRow Hammerのようなエラーが顕著になってきており、それを防ぐにはNANDのような管理が必要と言う指摘と思われる。プロセサチップに搭載されるコア数の増大から、1コアあたりのメモリ量が減ってきているという問題に対しては、DRAM+Flash+PCMのような階層的なヘテロのメモリで対応するしかない。銀の弾丸のような解決方法はない。メモリインタフェースを(HMCのような)高速シリアルにするか、(HBMのような)低速、ワイドにするかについては、性能的にはどちらでも良いが、エネルギー的には低速、ワイドが有利。コストの点では高速シリアルの方が僅かに良いといったところである。PIM(Processing in Memory)アプローチに関しては、処理用のテクノロジとメモリ用のテクノロジは優先度の付け方が違うので、長期的に見ると問題があるという見解である。ただし、これは3DスタックでロジックとRAMを異なるテクノロジで作る場合は含んでいないと思われる。
2015年12月15日
SC15において、ムーアの法則が終わった後の時代のコンピューティングがどうなるかについてのパネルディスカッションが行われた。モデレータはローレンスバークレイ国立研究所のGeorge Michelogiannakis氏。登壇したパネルメンバーは、(右から順に)同じくローレンスバークレイ国立研究所のチーフテクノロジオフィサーのJohn Shalf氏、南カリフォルニア大のBob Lucas教授、ローレンスバークレイ国立研究所のDavid Donofrio氏、IBMのJun Sawada氏、チューリッヒのETHのMattias Troyer教授、 IntelのShekhar Borkar氏という豪華メンバーである。南カリフォルニア大のLucas教授は、D-Wave Systemsの量子コンピュータを使った研究を行っていることで有名で、Troyer教授は、D-Waveは通常のコンピュータの性能を大きくは超えない、本当に量子効果で動いているのかどうかは疑問という論文を出している反D-Wave派の中心人物である。IntelのBorkar氏は、Extreme-scale Technology開発のディレクタで、Intelのテクノロジ部隊を代表する人物である。IBMのSawada氏は、IBMのニューロチップ「TrueNorth」の開発者で、日本で開催されたCool Chipsでも講演している。Michelogiannakis氏は、「これは、どのテクノロジが勝つのかというバトルではなく、それぞれのテクノロジはどのような問題を解くのに適しており、どこがテクノロジ間の境界線になるのか、各テクノロジはどのような可能性を持っているのかに関して理解を深めることが目的」と述べてパネルディスカッションを開始した。○IntelのSekhar Borkar氏のポジションモデレータの指名で、最初にポジショントークを行ったのは、IntelのBorkar氏である。ムーアの法則の時代のデバイスはMOSトランジスタであり、これは熱励起された電子(または正孔)を使うデバイスで、増幅作用があり高い信号/ノイズ比をもつ回路が作れる。そして、性能、エネルギー効率、コストが何10年にもわたってスケールしてきた。また、製造性も何10年にわたって維持されてきた。コンピューティングは、(数100年の歴史のある)ブール代数を使い、トランジスタを使ってメモリとロジックを作ってきた。計算の論理としてはチューリングマシンを数10年にわたって使っている。そしてコンピューティングの実装としてはノイマンアーキテクチャを使ってきている。これに対して、今後のデバイスの候補とされるものとそれを使うコンピューティングについてまとめると次の表のようになる。CNT(カーボンナノチューブ)やグラフェンのようなカーボン系の素子は、基本的な動作原理は、シリコンと同じMOSトランジスタで、熱イオン素子である。10-20年にわたって研究されてきたが、まだ、成熟していない。問題点としては、ソースドレインのコンタクトの形成、CNTの成長の方向などを揃えること、直径を一定に制御すること、メタリックなCNTを除去することなどが解決されていない。ということで、大量生産の見通しが立たない。TFET(Tunnel FET)はMOSデバイスであるが、熱イオン素子ではなく、トンネル現象を使う。10年以上にわたって研究されているが、まだ、成熟していない。性能が低く、当初、想定されたほど、サブスレッショルドの漏れ電流も小さくならない。量子コンピューティング素子は、増幅作用が無い。このため、ノイズの中から信号を探すような動作になってしまう。また、超電導が維持できる低温に冷やすことが必要である。10年以上にわたって研究されているが、まだ、成熟していない。用途が限られるし、大量生産の見通しもない。ニューロ素子は、コンピューティングの理論が無く、なぜ、どうやって動作するのかが分からない。何10年も研究されているが、依然、先行きが見えない。用途も限られる。ということで、ポストムーアの候補と目される素子の研究は続けて行くべきであるが、本当に実用になるかどうかの見通しがあるものは無い。従って、Post MooreはMore of Mooreで行くしかない。というのがBorkar氏の主張であった。
2015年12月09日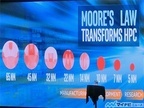
スパコンによるHPC(High Performance Computing)といっても、それが何の役に立つのか専門家以外には分かり難いということから、SCでは、「HPC Matters」という標語でHPCの重要性を理解してもらうという活動を行っている。そのHPC Mattersの基調講演が、SC15の本会議の開催に先立って前日の夕方に行われた。この基調講演が終わると展示フロアが開場して前夜祭であるGalaになるので、一番多くの参加者が集まるという良いタイミングである。今年のHPC Mattersの基調講演を行ったのは、IntelのシニアVPでData Center Groupを率いるDianne Bryant氏である。ガリレオが望遠鏡を発明して、見える範囲が大きく広がったのと同様に、HPCは数値シミュレーションで、これまで見えなかったことを可視化して見えるようにしている。その点でHPCは科学をトランスフォームしているという。そして、Gordon Moore氏のスピーチを見せ、その中で、Moore氏はコンピュータが高性能化するにつれて扱える問題が広がると指摘していた。1997年にIntelが作ったASCI Redは、当時Top500の1位であった。しかし、2015年現在の1位はIntelのXeonとXeon Phiを使う「Tianhe-2(天河2号)」であり、その間に性能は2万5000倍になったが、消費電力は20倍にしかなっていない。このようにテクノロジがHPCをトランスフォームしている。そして、Intelの半導体技術開発のディレクタであるMark Bohr氏が登壇し、ムーアの法則がHPCをトランスフォームさせ、さらにHPCがムーアの法則をトランスフォームしていることを説明した。ムーアの法則による微細化で、使用できるトランジスタ数が増えトランジスタの性能もあがるので、ムーアの法則がHPCをトランスフォームするのは当然であるが、実はHPCがムーアの法則をトランスフォームするという面もあるという。ちょっと見難いが、左の写真は微細な配線パターンで、正方形のパッドや長方形の配線のパターンが並んでいる。しかし、露光に使う光の波長より、これらのパターンの方がずっと小さいので干渉が起こり、このパターンをマスクにしても所望のパターンは露光できない。このため、Intelはどのようなマスクパターンを作れば、干渉の結果、所望のパターンがウェハに焼き付けられるかを計算してマスクを作る。その結果が右の写真のような変なマスクパターンとなっている。この計算には100万CPU時間が必要とのことであり、1万個のCPUを使うスパコンで100時間の計算を必要とする。また、半導体の内部での電子の振る舞いや、製造プロセスをシミュレートして、どのような半導体ができるのかを求めたり、配線の製造プロセスをシミュレートしたりすることは、半導体プロセスの開発には不可欠で、これらの計算には1万~100万CPU時間が必要であるという。この点で、HPCがムーアの法則をトランスフォームしていると言っても過言ではない。そして、BaiduのチーフサイエンティストのAndrew Ng氏をスライドで登場させた。Ng氏は、最近のMachine Learningの急速な進歩は、学習に使うデータのサイズが大きくなったことの貢献が大きく、将来的に、人工知能のすべての分野においてHPCを使う科学者の貢献が大きくなっていくと述べた。また、インドでスパコン環境の整備を行っているHemant Darbari氏も登壇させた。同氏は、HPCを使ってシミュレーションを行うモノづくりによる効率化や気象シミュレーションによる天気予報が、農業をはじめとする色々な分野の効率を上げていることをあげ、HPCはコミュニティをトランスフォームすると述べた。そして、IntelはHPCの重要性に鑑み、ACMのSIGHPCとタイアップして、年間30万ドルのComputational & Science Fellowshipという奨学金を2016年から創設すると発表した。これはAndrew Grobe元社長の発案であるという。そして、Exascaleの実現には消費電力をはじめとして、まだ解決すべき問題があるが、一方、世界には食糧問題、水不足の問題などExaのスパコンが貢献できると考えられる問題がたくさんあり、開発を推進する必要があると述べ、開発をけん引する6人のキーマンを紹介して基調講演を締めくくった。
2015年12月01日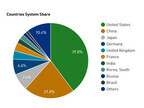
今回のSC15で発表された第46回 TOP500では、中国の「天河2号」が1位を維持し、Top5には変動が無かった。また、Top10で見ても、新顔は6位の米国の「Trinity」と前回の23位から増設でランクアップして今回8位となったドイツの「Hazel Hen(前回の名称はHornet)」の2システムだけである。これを見ると、今回もTOP500には大きな変動は無かったとも言える。しかし、実は大きな変化がある。TOP500にランクインした中国のシステム数が大幅に増加したのである。今年6月の第45回のリストでは37システムであった中国のシステム数が、今回は109システムに激増している。これにより、前回は40システムで米国に次いで2位だった日本は39システムで3位に後退している。また、メーカー別では、49システムをランクインさせたSugon(曙光)が、HP、Crayに次ぐ3位となった。これを受けて、Sugonの展示ブースでは、アジアの第1位のスパコンベンダーと書かれていた。この中国のシステムの急増は驚きで、多額の予算をつぎ込んで、スパコンを増強したのかと思ったのであるが、その中身を詳しく見て行くと、どうもそうではないようである。前回までのTp500リストに載ったことがなく、今回のリストで初登場した中国のシステムは87システムある。しかし、その中には、2013年に設置されたと申告されているシステムが2システム、2014年に設置されたと書かれているシステムが3システム含まれている。これらは以前から存在したスパコンであるが、これまではLINPACK性能の測定を行わず、TOP500に参加していなかったシステムである。これらの5システムのうちGovernmentのシステムが1システムあるが、4システムはIndustryとなっている。私企業が所有しているスパコンについては、TOP500に参加するものもあるが、どの程度の規模のスパコンを持っているかをライバル企業に知られたくないので、TOP500などのベンチマークには参加しないという企業も多い。今回、新顔として登場した中国のスパコンは、Government、Research、Academicというものはごく少数で、大部分はIndustryのスパコンである。また、設置年は2015年となっているが、使っているCPUを見ると、最新のXeon E5-2600のv3ではなく、1世代前のv2を使っているシステムも多い。このため、これらのシステムは、申告上は2015年設置となっているが、それ以前に設置されたものもかなりあるのではないかと推測される。設置企業であるが、Internet Company Bのように業種以外は匿名のエントリも多いが、AlibabaとかChina Mobileというものや、Agricultural Bank of China (ABC) Shandongなどというものもあり、いわゆる科学技術計算向けの計算センターではないものが多く含まれているのではないかと思われる。例えば、Google、Microsoft、Amazonなどが、そのセンターを使ってTOP500のランキング用のベンチマークであるLINPACK性能を測れば、相当に高い値が出せると思われる。また、トヨタや日産、ホンダなどの自動車メーカーも相当規模のスパコンを使って衝突シミュレーションなどを行っていると見られるが、TOP500で高いランクをとっても会社としては何のメリットもないので、TOP500には参加していないと思われる。LINPACK性能の測定には、どの程度のチューニングを行うかにもよるが、1日から1週間程度を必要とし、その間、システムを占有してしまう。商用の運用を行っているInternet Companyでは、通常業務を止めてLINPACK性能を測定するのは容易ではない。中国では、政府の権限が強いので、システムを借り上げて測定するということが出来るのかも知れないが、日本や米国ではインターネットサービスや銀行のオンラインを止めて、LINPACK性能を測定することは出来そうにない。したがって、日本や米国で同じ手法でTOP500にランクされるシステム数を増やすことは難しいが、一方、中国のスパコン資源が急速に増加したということでもなさそうである。
2015年11月25日
オースティンで開催されているSC15において、ExaScalerが液浸のXeonサーバブリックとストレージサーバブリックの発表を行った。これまでExaScaler/PEZYは、PEZYの開発した1024コアのPEZY-SCを搭載したHPC向けのサーバだけを作っていたのであるが、16個のXeonを搭載する「Multi-Xeon Server Brick」と、24台の3.5インチHDDと24台の2.5インチSDDを同時に搭載できる「Storage Node SH Brick」を製品ラインに追加する。これらのBrickに従来のPEZY-SCを搭載しながらもホストCPUのXeonとPEZY-SCモジュールの双方の搭載メモリ容量を倍増したBrickを加え、新たに開発した液浸槽のシステム全体を「ZettaScaler-1.5」として発表したものである。同社のブリックは14cm角で長さが80cmあまりの角柱状であったが、このサイズを今回発表のブリック2種類とPEZY-SCブリック共に20mm程拡幅して14cm×16cmとした。、16本のブリックを収容できるZettaScaler-1.5液浸システムには、これら3種のブリックを任意の組み合わせで搭載できる。したがって、これまでのようにPEZY-SCブリックだけを使うHPC用のシステムもできるし、Xeonブリックを4本にストレージブリックを12本というような構成のシステムを作ることもできる。通常のHDDは液浸すると冷却液が浸み込むおそれがあるので、液浸はできないが、HGSTは液浸が可能なHDDを開発しており、SC15でも展示を行っていた。高性能のHDDはディスクの高速回転時の摩擦を減らすため、空気ではなくヘリウムを充てんするが、ヘリウムは分子が小さく抜けやすいので、密閉度を高くする必要がある。液浸が可能なHDDは、これに加えてモーターなどの回転部分も密閉して液浸を可能にしていると考えられる。ExaScalerは、どこのHDDを使っているかは公表していないが、ブースで展示されていたのはHGST製であった。例えば、前述のXeonブリックが4本、ストレージブリックが12本とすると、Xeonが64個、3.5インチHDDが288本と2.5インチSDDが288本収容できることになり、非常に高密度のサーバを作ることができる。高価なフロリナートを冷媒として使うためのコストアップはあるが、データセンタの床面積の削減、冷却電力の削減、低温動作による消費電力と故障の低減などを考えるとペイするのではないかと思われる。現地でExaScalerの齊藤会長に確認したところ、「ExaScaler」という製品名が米国と日本で他社によって商標登録されてしまったために、ExaScalerの名称を会社名以外に使用することを避ける必要が生じた。そのため、この機会に製品名よりも大きな意味としてZettaScalerを液浸冷却システムのプラットフォーム全体の名称とすることとしたそうである。また、これらの3種のブリックに加えて、8台のフルサイズのGPUを搭載する「GPGPU Node Brick」の開発を進めており、3カ月程度で製品化を行う予定であるという。
2015年11月19日
スーパーコンピュータ(スパコン)分野で最大の学会である「SC15」が、11月14日からテキサス州オースティンのオースチンコンベンションセンターで開催された。オースティンでの開催は2008年以来7年ぶりである。このSC15では78件の論文発表をはじめとして、135件のポスター発表、42のワークショップ、12件のパネルディスカッション、75件のBirds-of-a-Featherと多くの発表が行われる。また、大規模な展示はSCならではの見どころで、今年は、約1万4000m2の会場に、343の展示ブースが作られる。その内の217が企業の展示ブースで、120あまりは政府系の研究機関や大学などの研究、教育機関のブースである。主催者側から国別のブースの数が発表されたが、239ブースと約70%が米国のブースで、それについで日本が39ブースとなっている。興味深いのはRepublic of Koreaが1ブースと書かれていることで、韓国のKoreaは4となっているので、これは北朝鮮のはずである。この北朝鮮のブースがどこにあり、何を展示しているのか知りたいと思い、色々な知人に尋ねてみたのであるが、誰も知らなかった。北朝鮮の国籍では米国のビザは取れないので、あるとしても無人のブースではないかという人もいて、謎である。もし、見つけたら教えてと皆様に頼んでおいた。11月21日追記:上記で、北朝鮮のブースがあると書いておりましたが、これは、他の韓国のブースはKoreaと書かれていましたが,1つのブースだけがRepublic of Koreaと書かれていたのを,北朝鮮と勘違いしたものであることが分かりました。Republic of Koreaは韓国(大韓民国)であり,北朝鮮は「Democratic People’s Republic of Korea」であり、実際には北朝鮮のブースは存在しておりませんでしたことを追記させていただきます。今年のSC15の参加登録者は1万2157人と発表された。事前の登録を行わず、会場で参加登録をする人もいるので、実際の参加者数は、この数を多少上回ると見られる。この中で論文発表などのテクニカルプログラムに出席する人は4809人と発表された。
2015年11月17日
メディア・インテグレーションMI事業部は、EVE Audio社の最新デスクトップ・モニター・システム「SC203」を発表した。発売時期は2015年11月上旬。価格は6万9,800(1ペア)。同製品では、極小サイズのコンパクトボディーに、駆動範囲の大きい1インチのボイスコイルを採用した3インチ・ウーファーを搭載。2-wayのマスターとスレーブのシステムで構成された各チャンネルのウーファーとツィーターは、各々が専用の30W PWMアンプによって駆動する。また、ステレオRCAアナログ入力、光TOSLinkデジタル入力、RCAサブウーファー出力などを装備。Mac/PCに接続すれば、96kHzまでのデジタル信号をダイレクトに再生できる。FlexiPadと呼ばれるくさび型のオレンジ色のラバーパットが付属しており、正確に角度を付けて、場所に応じて最適な角度(0度/7.5度/15度)で設置することができる。さらに、オプションのアクセサリーとして、3/8インチ径のマイクスタンドとスピーカースタンドに取り付け可能なSC203専用のマウント・アダプターも用意される。
2015年10月23日
NTTドコモは25日、Androidスマートフォン「GALAXY S5 SC-04F」のソフトウェアアップデートを実施した。ソフト更新により、電池持ちを改善する。今回のソフト更新の対象は、6月4日に実施したOSバージョンアップを実行した端末。使用状況により、電池持ちが悪くなる事象が確認され、今回のソフト更新で改善する。ソフト更新は端末本体による方法とパソコンを使った方法の2種類。端末本体による方法では、設定/端末情報/ソフトウェア更新の順に選択する必要がある。更新時間の目安は約7分。パソコンを利用した方法では、「Samsung Kies3」を利用して、更新を行う。更新時間の目安は約29分。
2015年09月25日
オンキヨー&パイオニアは9月10日、パイオニアブランドのAVアンプ「SC-LX89」「SC-LX79」「SC-LX59」を発表した。発売は10月中旬で、希望小売価格は、SC-LX89が395,000円、SC-LX79が295,000円、SC-LX59が210,000円(いずれも税別)。SC-LX89とSC-LX79は2014年8月に発売された「SC-LX88」と「SC-LX78」の後継モデル。SC-LX59は、2014年7月に発売された「SC-LX58」の後継モデルだ。SC-LX89、SC-LX79、SC-LX59は、マルチチャンネル同時ハイパワー出力が可能なClass D「ダイレクト エナジーHDアンプ」を内蔵。同時駆動出力はSC-LX89が810W、SC-LX79は770W、SC-LX59は720Wとなっている。DACにはESSの「ES9016S」を2基搭載する。Dolby Atmosを利用できるほか、今後のファームウェアアップデートでDTS:Xをサポート予定。Dolby AtmosとDTS:Xの7.1.4デコードが可能で、パワーアンプ2chを接続することで多彩なスピーカーシステムに対応する。自動音場補正技術「MCACC Pro」を採用。周波数と音圧レベル、さらに時間軸の要素を加えた補正を行う。低域と高域のズレやチャンネル間の位相をそろえる「フルバンド・フェイズコントロール」、ソースに由来する低域のずれを補正する「オートフェイズコントロールプラス」、2本のサブウーファーを接続した環境で低域表現を向上させる「デュアルサブウーファーEQ」も利用可能だ。HDMI端子は8入力/3出力を装備。HDRコンテンツや4K/60p、4:4:4、24bit映像信号の伝送に対応するほか、BT.2020、HDCP 2.2など、最新の規格にも対応している。このほか、HD画質のコンテンツを4Kへアップスケールする「Super Resolution」を搭載している。ハイレゾ音源の再生にも対応。192kHz/24bitまでのFLAC / WAV / AIFF / Apple losslessに加えて、DSD 5.6MHzを再生可能だ。WAVとFLACは、マルチチャンネルコンテンツにも対応している。このほか、従来モデルではオプションとなっていたWi-Fi機能(IEEE802.11/b/g/n/a)を標準搭載し、Bluetoothも利用できる。
2015年09月10日
NTTドコモは28日、「GALAXY Tab S 8.4 SC-03G」(Samsung製)のAndroid 5.0へのOSバージョンアップを開始した。OSアップデートにより、画面デザインが刷新されるほか、ロック画面に任意のアプリの通知が表示されるようになる。アップデート後は、OSのバージョンがAndroid 4.4から5.0となる。画面がカラフルなデザインに刷新され、任意のアプリの最新の通知をロック画面に表示できるようになる。通知は、表示する優先順位の設定も可能。そのほか、連絡先アプリで別人の「よみがな」が表示される、緊急長持ちモード設定時にdocomo IDを設定しようとするエラーが表示される場合がある不具合も修正される。OSアップデートは、「設定」から「端末情報」、「ソフトウェア更新」とタップし、画面の案内に従って操作することで可能。更新時間は、Wi-Fi/Xi/FOMA接続時で約48分。更新後のビルド番号は「LRX22G.SC03GOMU1BOH7」。「設定」、「端末情報」、「ビルド番号」と進むことで確認できる。
2015年09月07日
エプソンは1日、ハイアマチュアやプロ写真家向けのインクジェットプリンタ「プロセレクション」シリーズの新製品として、A3ノビ対応の「SC-PX7V II」を発表した。10月上旬から発売し、価格はオープン、店頭予想価格は50,000円台後半の見込み。SC-PX7V IIは、2011年9月発売「PX-7V」の後継機。プロセレクションシリーズではエントリークラスとなるが、上位モデルと同系統のデザインとなり、高級感とシリーズ一体感がアップした。高い光沢感の8色顔料インクを採用しており、構成はフォトブラック、マットブラック(またはブルー)、シアン、マゼンタ、イエロー、レッド、オレンジ、グロスオプティマイザとなる。PX-7Vの「高彩モード」を引き継ぎ(ブルーインク使用時)、ポジフィルム風の高彩度な写真表現を可能とした。また、画像処理技術「オートフォトファイン!EX」の強化によって、暗部階調性が向上している。スマートフォンやタブレット向けアプリとの対応も高まり、印刷アプリ「Epson iPrint」では設定可能な用紙種類が増え、スマートフォン内の写真を利用して多彩な印刷を楽しむアプリ「Epson Creative Print」にも対応した。前者のEpson iPrintでは、オンラインストレージサービスに保存した写真や文書も、ワイヤレスで印刷可能だ。最大プリント解像度は5,760×1,440dpi、ノズル数は黒系が360ノズル(180×2色)、カラーが1,080ノズル(180×6色)。給紙はオーソドックスな背面給紙で、A4普通紙で最大120枚、ハガキで最大50枚をセットしておける。厚紙やファインアート紙といった用紙は、背面からの手差し給紙を使う。CD/DVD/BDレーベル印刷にも対応している。印刷速度の目安は、L判写真(光沢紙)が約36秒、A3ノビ写真(光沢紙)が約2分30秒だ。印刷コストの目安は、L判写真(光沢紙)で約21.7円となっている。インタフェースとしては、USB 2.0、10BASE-T/100BASE-TX対応有線LAN、IEEE802.11b/g/n対応無線LAN(Wi-Fi)を装備。本体サイズは使用時がW622×D797×H418mm、トレイなど収納時がW622×D324×H219mm、重量は約12.3kg。
2015年09月01日
アミューズメントパーク「さがみ湖リゾートプレジャーフォレスト」(神奈川県相模原市)は11月7日、同園にてランニングイベント「サバラン」を開催する。○仲間とミッションをクリア同イベントは、今回が2回目の開催。雄大な自然を肌で感じながら楽しめるランニングイベントとなる。サバランの"サバ"には、アウトドアからイメージする"サバイバル"体験や、フランス語の挨拶"サヴァ"(参加者同士が声をかけ合ったり応援したりする)などの意味が込められているとのこと。参加者は、約4kmのコースをランニングしながら、途中にいくつかあるミッションをクリアしていく。ミッションは決してハードなものではなく、タイムの計測や順位もないため、女性や子供、普段運動をしない人でも十分に楽しめる内容だという。ランの後には、フェスティバル会場で同時開催するフードフェスや手ぶらで楽しめるバーベキュー、特設ステージでの音楽などが1日中楽しめる。また、遊園地内のアトラクションや温浴施設「うるり」を利用できるほか、日没後にはイルミネーションのイベント「さがみ湖イルミリオン」も楽しめるとのこと。参加資格は、小学生以上の健康な男女。定員は5,000人。参加料は、一般が5,000円、保護者+小学生~高校生が2人1組となるファミリー割が7,000円、4人以上7人までのグループ割が1人4,000円、学割が1人4,500円(いずれも税・入園料込)となる。
2015年08月24日
トランスワールドジャパンは6月25日~9月2日の期間限定で、レシピ本『アジアン丼本』の発売を記念して、「富士宮やきそば こころ相模大野店」(神奈川県相模原市)にて「アジアン丼フェア」を開催している。同書は、アジア圏の料理を使った丼のレシピ本。今回行われるフェアでは、レシピの中から厳選した全10種類の丼メニューを同店にて週替わりで販売するという。価格は全メニュー500円(税込)となる。タイ、ベトナム、シンガポール、韓国、モンゴル、インド、ブータンなどアジア各国の食堂や屋台で食べられている料理を日本の「丼」スタイルに合うようアレンジして提供するとのこと。また、「野菜たっぷり」「少スパイス」をこだわりとしており、小さな子供でも楽しめるという。6月25日~7月1日には、「バンコク風 しょうが焼き丼」を販売。しょうゆの代わりにナンプラーを使った甘辛いタレにオイスターソースを隠し味として入れ、"香菜"と黒こしょうでスパイスを効かせた。7月2日~7月8日には「ユンさんの牛すね煮丼」を提供する。ベトナムのビーフシチュー「ボー・コー」をアレンジした丼で、混合香辛料の"五香粉"を使った甘辛く濃厚な味つけとなっている。7月9日~7月15日には、東南アジア各地で親しまれているという「海南チキン丼」を販売する。鶏スープで炊いたご飯をバターライスとし、しょうが風味のスイートチリソースをあしらった丼となる。以降も、7月16日~7月22日に「ベトナム角煮とゆで卵丼」、7月23日~7月29日に「シンガポールチキンサラダ丼」、7月30日~8月5日に「屋台ぶっかけ豚煮丼」、8月6日~8月12日に「タンドリーチキン丼」、8月13日~8月19日に「ベトナム式 豚サラダ丼」、8月20日~8月26日に「まぐろのユッケ丼」、8月27日~9月2日に「インド風 冷やしトマト丼」を提供する。
2015年06月25日
エプソンは4月22日、8色顔料インクを採用したA2ノビ対応のインクジェットプリンタ「SC-PX3V」を発表した。5月14日から発売し、価格はオープン、推定市場価格は15万円台の後半となっている。SC-PX3Vは、プロ写真家やアマチュア写真愛好家に向けた「プロセレクション」シリーズの新モデル。2009年10月に発売された「PX-5002」の後継機となる。8色顔料インクの独立型インクカートリッジを搭載し、ブラック系は「Epson UltraChrome K3 INK」だ。フォトブラックまたはマットブラック、グレー、ライトグレーという3種類のブラック系およびグレー系のインクが使える。黒濃度を高めたフォトブラックインクで暗部の微妙な階調を立体的に表現するほか、顔料インクが用紙の表面付近で高濃度定着するマットブラックインクは、多彩な用紙において高い定着性を実現した。カラーの色域も拡大しており、従来よりも滑らかなグラデーション表現を可能にしている。主な仕様は、印刷方式がMACH方式、最高解像度が2,880×1,440dpi、ノズル数がブラック540ノズル(各180ノズル×3色)、カラーが900ノズル(各180ノズル×5色)。対応用紙サイズはA2ノビ縦まで。標準用紙カセットには最大120枚の用紙をセットでき、手差し給紙も備える。本体サイズはW684×D376×H250mm、重量は約19.5kg。インタフェースはUSB 2.0、10BASE-T/100BASE-TX対応有線LAN、IEEE802.11b/g/n対応無線LAN。無線LANは「Wi-Fi Direct」に対応し、スマートフォンなどと無線LANで直結して印刷できる(スマートフォン用プリントアプリ「Epson iPrint」に対応)。本体の操作パネルは、チルト可能な2.7型タッチパネルを採用している。写真作品づくりをサポートするソフトウェア「Epson Print Layout」にも対応しており、「ロール紙長尺印刷」と「ギャラリーラップ」の作成機能が追加された。Epson Print Layoutは、「Adobe Photoshop」や「Adobe Photoshop Lightroom」のプラグインソフトとして利用できる。また、オプションとして、新たに17インチ幅対応のロールペーパーユニット、プレミアムサテンキャンバス / プレミアムマットキャンバスを追加。税別価格は、ロールペーパーユニットが19,980円、プレミアムサテンキャンバスが27,500円、プレミアムマットキャンバスが25,000円だ。
2015年04月23日
NTTドコモは17日、Androidスマートフォン「GALAXY S III α SC-03E」向けの最新ソフトウェアの提供を開始した。ソフト更新より、スリープモード解除後にWi-Fi接続に復帰しない不具合に対処する。ソフト更新は端末本体とパソコン接続の2種類の方法がある。端末本体では、設定/端末情報/ソフトウェア更新の順に選択し、画面の案内にしたがって操作をしていく。パソコンを使った方法では「Samsung Kies」をインストールしたパソコンが必要になる。手順は、端末のホーム画面で、本体設定/開発者向けオプションの順に選択、USBデバッグのチェックが外れていることを確認。パソコンの画面で、Samsung Kiesを起動させ、端末本体をパソコンに接続し、表示されたポップアップ画面にしたがい更新作業を行う。ソフト更新後のビルド番号は「JSS15J.SC03EOMUBNK2」。更新時間の目安は端末本体による方法が約18分、パソコンによる方法が約9分。(記事提供: AndroWire編集部)
2014年12月17日
アークランドサービスは12月19日、からあげ専門店「からやま」を神奈川県相模原市にオープンさせる。開店を記念して12月21日まで、「からやま定食(竹)」などを特別価格で販売するキャンペーンを実施する。同社は、とんかつ専門店「かつや」を運営。同店は、「伝説のからあげ! からあげ 縁 - YUKARI -」等を運営するBAN FAMILYとのコラボレーションから誕生したからあげ専門店で、定食や丼などから、最後まで熱々で食べられる「鉄板」メニューまで、幅広い料理を用意する。開店を記念して12月19日~21日までの3日間限定で、4種類のメニューを特別価格で提供する。通常745円の「からやま定食(竹)」、「鉄板極ダレ定食」は各600円、通常637円の「ネギ極ダレからやま丼」、「ネギ塩極ダレからやま丼」は各500円で販売する。また、テイクアウトコーナーではから揚げ2種類(カリっともも、極ダレ)を、1グラムあたり2円で販売する。該当期間中は上記4品目のみの販売となる。価格はすべて税込。
2014年12月15日
●コールドプレートと液体を組み合わせた冷却技術SC14の展示では、CPUなどの発熱を、空気ではなく液体を使って運び出すシステムの展示が目立った。また、そのための冷却システムを販売している会社の展示も多く見られた。スパコンの高密度実装が進んだために、空気で熱を運ぶ方法では発生する熱を運びきれなくなってきたことが、その背景にある。空気の比熱は1008J/Kg℃(40℃)で、水の比熱は4180J/Kg℃程度であるから、重量あたりでは、水は空気の4倍程度の熱を運べる。しかし、水の密度はおおよそ1000kg/m3であるのに対して空気の密度はおおよそ1.2kg/m3であるから、体積当たりにすると、水は3500倍あまりの熱を運べることになる。CPUのヒートシンクの高さが2cm、幅が10cmとすると、空気の流れる断面積は0.002m2で、流速1mとすると10℃の温度上昇で運べる熱は22J/s(=22W)である。これではCPUの発熱を運びきれない。CPU 1個だけなら20℃上昇を許容して流速を3m/sにすれば、132Wの熱を運ぶことができるが、複数のCPUや他の発熱部品を狭いところに詰め込むと、この条件を満たすのは難しく、空気では冷やせなくなる。一方、水は体積が同じなら3500倍の熱を運ぶことができるので、毎秒0.6cm3というわずかな流量で同じ熱を運べる。そして、10cm3/sの水をパイプで供給することは難しくないので、現在の発熱密度が10倍になっても十分、冷却が可能である。○コールドプレートを使う水冷方式水は電気を通してしまうので、直接、LSIやプリント板に触れさせるわけにはいかない。このため、パイプなどで水を運び、LSIなどに水で冷やす銅板やアルミ板などを接触させて冷却するという方法は古くから使われてきた。この水で冷やした銅板(あるいはブロック)を「コールドプレート(Cold Plate)」と呼ぶ。コールドプレート方式の弱点は、CPUなどの少数の高発熱の部品を冷やすには適しているが、メモリDIMMや、その他の部品にまでコールドプレートを付けることは難しいので、それらの部品の発熱を取り去るために空冷のファンも必要になるという点である。次の写真は、冷却系のメーカーであるASETEKの水冷用のラックといくつかの製品の例である。写真では見えないが、ASETEKのラックは、CPUなどを冷やして温まった水の熱を2次冷却水に移す熱交換器を内部に持っている。そして、冷却水の給排水系には、ASETEKはプラスチックの可撓制のあるパイプを使っている。CoolITも冷却システムのメーカーである。CoolITのコールドプレートは長方形の角を落としたような形状で、こちらも接続にはプラスチックパイプを使っている。ASETEKは1ラック用のCDUをラックに内蔵しているが、CoolITは、集中型の大きなCDUで複数のラックに冷却水を供給している。ASETEKやCoolITはプラスチックパイプを使っているが、水漏れを心配して、歴史的には、パイプとコールドプレートを銅で作って溶接するというのが一般的であり、LenovoのNeXtScaleサーバや富士通のFX100スパコンをはじめとして、多くの水冷システムは銅を使っている。銅パイプの場合は、力が掛かって接続部が破損しないように、余裕を持った配管が行われる。Lenovoのサーバは主要LSIだけにコールドプレートを取り付けているのであるが、DIMMにはカバーが掛けられており、この部分もヒートパイプを使うなど何等かの方法で水冷されているようである。Lenovoの説明パネルでは、85%以上の熱を水冷で運んでいると書かれていた。富士通のFX100スパコンの3ノードボードは1つのコールドプレートで、CPU LSIと両脇に配置された計8個のMicronのHMCメモリを冷却している。なお、この写真では、中央のノードはLSIが見えるようにコールドプレートを取り外した状態で展示されている。京コンピュータの時は、メモリDIMMは空冷、IOノードも空冷で、ラックの発熱の50%程度しか水冷されていなかったが、FX100では90%が水冷である。そして残る10%もオプションのEXCU(リアドア空冷か)で吸収して計算機室の空調負荷をゼロにすることができる設計となっている。SGIのICE-Xサーバは冷却水の通路は銅パイプであるが、コールドプレートはアルミで作られている。なお、水冷のシステムは、冷却水の接続にはノンスピル(あるいはドリップレスともいう)コネクタを使っており、コネクタを抜いても水が漏れることがないようになっている。○カスタムのコールドプレートを使う水冷プリント板に搭載された発熱部品の高さはマチマチであるので、単純な平面の大きなコールドプレートではうまく接触しない。このため、プリント板とほぼ同じサイズのアルミの分厚い板をそれぞれの部品の高さに合わせて、削ってすべての発熱部品に接触するようにして、ほぼ100%の熱をコールドプレートで運び出すというやり方を取っているのは主にヨーロッパ勢で、フランスのBULL、ロシアのRSC group、イタリアのEurotechなどである。Eurotechは、SC14において第2世代となる「Aurora Hiveシステム」を発表した。Aurora Hiveのモジュールはブリックと呼ばれ、幅が105mm高さが130mmで奥行が325mmとなっている。このブリックをラックの前後から挿入する構造で、表、裏ともに16行×4列のブリックを収容する。従って、ラック全体では128ノードを収容できる。ブリックは6角形ではなく4角形であるが、ラックには、ブリックを入れる4角形のスペースが整然と並んでいる様子が蜂の巣に似ていることからHiveと名付けられたという。コールドプレートは冷蔵庫の冷却プレートのような形状で、そのままでは発熱部品とは接触せず、間を埋めるような金属部品を取り付けているようである。分厚いアルミ板から削り出すのは高くつくと思われ、こちらの方が安くできそうである。このブリックに6枚のボードを収容でき、Xeon E3 1200 v3、あるいはX-Gene Oneプロセサを搭載したCPUボードが1枚、NVIDIAのK40あるいはXeon Phiボードを4枚、そしてInfiniBandの通信ボードを1枚というのが標準的な構成である。●不活性液体による浸漬を活用した冷却技術○不活性液体を使う浸漬液冷方式コールドプレートでは主要発熱部品だけの放熱に限定され、より多くの部品の放熱を行おうとすると、カスタムの切削加工などが必要となり、コストが掛かる。それなら、電気を通さない不活性の液体にプリント板を漬けてしまえば、全部の部品の放熱ができるという方式が考えられる。これが不活性液体を使う浸漬冷却である。不活性の液体として使われているのは、Exxon Mobile Chemicalが製造している商品名「SpectraSyn(Poly-Alpha-Olefin:PAO)」、3Mが製造している商品名「Fluorinert(Fluorocarbon)」、同じく3Mが製造している商品名「Novec(PerFluoroKetoneやHydroFluoroEtherなど)」がほとんどである。SpectraSynは車のエンジンオイルのようなもので比較的安価であるが、多少べとつくので、修理などの際にプリント基板や部品から取り除くのが大変という難点がある。FluorinertやNovecは蒸発してしまうのでしばらく放置すれば取り除けるが、冷却液が非常に高価なのが難点である。例えば、通販サイト「モノタロウ」でのフロリナート1.5Kg入りのビンの値段は、種類によって異なるが、34,900~50,353円となっている。1.5Kgといっても比重が1.7~1.9くらいと重いので、ビールの大瓶より少し多い程度の体積でしかない。つまり、ビールの100倍以上高い液体である。Novecの方はフロリナートの半分くらいのお値段であるがそれでも安くはない。大量に買えばもっと安くなるのであろうが、これで数100リットルのタンクを満たすのは大変である。Green Revolution Cooling(GRC)はSpectraSynを冷媒として使っている。写真の製品は42Uの標準ラックを横に倒してオイルに漬けたようなもので、これにオイルを循環させて、外部の熱交換器で冷却している。なお、この写真では隙間をあけてサーバを入れているが、詰めて実装することができる。昨年11月と今年6月のGreen500で1位を取った東工大のTSUBANE-KFCは、このGRCの製品を使っている。LiquidCool Solutionsの製品は、サーバボードをアルミのケースに入れて密閉し、ケースにオイルの供給と排出のコネクタを付けたという構造になっている。合成オイルで満たされるのはケースの中だけなので、開放型のGRCのものより多少は扱い易いと思われるが、修理などの際は、ケースを開けて、オイルを除去する必要があり、手間が掛かりそうである。なお、この写真ではアルミケースを水槽に入れているが、これは浸漬液冷という演出だけで、通常の使用ではこのように浸漬されることはない。東工大は、京コンピュータを1つのキャビネットに収容するTSUBAME 4を2021~2022年に完成させるいうロードマップを持っており、このTSUBAME 4の研究のため、試作機を作っており、NVIDIAのJetson TK1という組み込み用のボードを使った36ノードの試作機をSC14で展示した。この写真のようにプリント板の下半分だけを合成オイルに漬けて冷却している。主要な発熱部品は下半分に搭載されているので、これでも液冷の効果は得られる。また、上側にあるコネクタ類はオイルに浸からないので、保守やケーブルの繋ぎ変えが簡単にできるという。ICEOTOPEは、3MのNovecを冷媒として使っている。写真に見られる密閉型のモジュールはNovecで満たされている。モジュール内部にはNovecと外部からの冷却水の間の熱交換器が組み込まれており、モジュールには冷却水を供給する。つまり、外部から見ると、水冷のモジュールと同じになっている。LSIの発熱でMovecを気化させ、熱交換器で冷却して、液体に戻すという2相式の冷却であるので、比熱で熱を運ぶより効率が高いと思われる。下の写真はNovecの製造元の3Mのブースに展示されたもので、Novecを満たした水槽にプリント板を漬けている。展示のため、蓋が十字に置いてあるが、動作中は蒸気を逃がさないように蓋を閉める必要があると思われる。今回のGreen500で2位となったExaScaler/PEZYの展示は、何故かSuiren(睡蓮)スパコンが設置されているKEKのブースではなく、共同研究先の東京大学(平木研究室)のブースにあった。アクセラレータであるPEZY-SCのチップやボードは実物が展示されていたが、重くて嵩張る水槽は無く、パネルでの展示であった。Suirenは浸漬液冷で、これまで冷媒はフッ化炭素系というだけで詳細は非公開であったが、今回、3Mのプレスリリースで、FC-43という沸点174℃、密度1880Kg/m3のものを使っていることが明らかになった。●ヒートパイプを活用した冷却技術○ヒートパイプで熱を運ぶ冷却高発熱の部品からヒートパイプで熱を運び出し、処理しやすい場所に水や空気との熱交換器を設けるという方法を取るシステムもある。HPのHPC向けのサーバである「Apollo 8000」は、次の写真に見られるように、ヒートパイプでCPUなどの熱を運び出す。そして、写真の左側に写っているブレードの側面に見られるように、ヒートパイプの端を露出させた構造になっている。ラックに挿入すると、この露出部分が水冷のレールに接触し、熱を冷却水に伝えるという構造になっている。ヒートパイプの中は、発熱サイドで冷媒の温度が上がって蒸発し、水冷のレールに接触している部分で液に戻るという2相の冷却システムとなっており、その熱を2次冷却水に伝えるという冷却システムになっている。その点では、構造は大きく異なるが、原理的にはICEOTOPEのものと同じである。また、パネル展示だけで実物は無かったが、Calyosという会社が、「Vapor Chamber」という製品を展示していた。ASETEKやCoolITのコールドプレートのような形状のVapor Chamberをプラスチックや銅パイプで接続してヒートパイプを構成して熱を運び出す。しかし、一般にヒートパイプは銅系の合金のパイプで、封じ切りで作られており、この構造で蒸気が漏れないのかが気になった。この記事で紹介したように、SC14では高性能の冷却システムを使用するシステムが数多く展示された。サーバやスパコンのエネルギー効率は改善されていくが、必要な性能の増大の方がスピードが速く、発熱量は増える方向にある。また、設置面積を小さくするため、発熱の密度はどんどん高まっており、高性能の冷却システムの必要性が高まっていることが、この背景にある。そして、この記事で紹介したように、色々な冷却方式が使われており、現在は、乱立とも言える状態である。業界として経験を積むにつれて、将来的には、使い勝手のよい幾つかの方式に集約して行くのではないかと思われる。
2014年12月12日
●新設台数が鈍化し高齢化が進むスパコン○スパコンの新設はスローダウンしている恒例であるが、SC14で第44回のTop500の「BoF(Birds of a Feather:同じ羽を持つ鳥の集まり、転じて同好の士の集まり)」が開催された。今年1月に、Top500の創始者の1人であるHans Meuer教授が亡くなったので、委員会のメンバーはご子息のMartin Meuer氏に交代している。なお、Samuel Williams氏はHPGMG、Mike Heroux氏はHPCGという新しいベンチマークプログラムの説明のための参加であり、Top500委員会のメンバーではない。Top500というとリストの順位だけが注目されるが、その価値は単なる番付表というだけでなく、その中身を分析して行くと、スパコン界の状況が見えてくるという点が重要である。今回のTop500では、1位の天河2号から9位のVulcanまで、前回のリストからまったく変動がなく、かろうじて10位に米国政府機関のCray CS-Stormスパコンが入ったということだけが変化である。右側の図は、これまでの毎回のTop500リストで、何システムの新しいスパコンがリスト入りしたかを示している。もちろん、毎回、新システムの数は変動するが、概ね、150~200システムという状況が2013年6月までは続いていた。しかし、その後、新システムの数は急減し、今回は78システムになってしまった。明らかに、2013年以降は、Top500リスト入りする規模のスパコンの新設がスローダウンしている。新設のスローダウンの結果、リストに入っているスパコンの平均年齢が上がってきている。左上の図のように、2011年頃までは平均1.27年前後で推移していたが、それ以降、平均年齢が上がってきて、今回のリストでは2.9年と過去の2倍以上の年齢となり、Top500の世界も急速に高齢化が進んでいる。右上の図は、500システムの性能の合計の値の直前のリストからの伸びを示すものである。このグラフはアップダウンが激しいが、過去にはおおむね1.9倍弱程度とムーアの法則の1.6倍(なぜ、ムーアの法則が1.6倍かは不明)を上回る伸び率で推移してきたが、このところ1.2倍程度という低い伸びになっている。左下の図は、Top500全システムの性能の合計、1位のシステムの性能と500位のシステムの性能の推移を折れ線グラフで示したもので、1位の性能の線はでこぼこしているが、合計と500位の性能は片対数グラフに綺麗に乗っていた。しかし、2011年ころから500位の性能の伸びがスローダウンし始め、2014年には合計の数値の伸びもスローダウンの兆候が出始めている。右下の図は、性能の合計値が500システム合計の性能値の半分となる順位の推移を示すグラフで、2010年頃までは上位50~70システムの性能合計が全システムの性能合計の半分を占めるという状況であった。しかし、このところ上位10~30システムで半分を占めるという状況になっている。これは性能の高い大規模システムと性能の低い小規模システムとの2極化を意味している。次の左上の図は、システムの平均性能の推移と1個のプロセサの性能の推移を示すもので、縦軸は適当にスケールされているので、絶対的な値は意味はない。この図から明らかなのは、プロセサの性能の向上にくらべて、システム性能の伸びの方が大きく、テクノロジの伸びだけではスパコンに必要とされるたけの性能向上を支えることは出来ず、使用するプロセサの個数の増大で対処しているという状況になっているということである。右上の図は、500システム全体で、GPUなどのアクセラレータが占めるFlops値の合計を示すものである。2012年から2013年に掛けて、アクセラレータのFlops値の急速に増加したが、その後は、伸び率が減少している。左下の図は、アクセラレータのFlops値が全体のFlops値の中で占める割合を示したもので、このところ34%くらいのところで留まっており、どんどんアクセラレータのFlops値が伸びて、Top500全体の性能を引き上げて行くという状況ではない。右下の図は、LINPACKのFlops値を消費電力で割ったエネルギー効率の図であり、リストの中で最も効率の良いシステムのFlops/W値は順調に伸びているが、下位のシステムでは効率の改善が遅れていることを示している。Top10システムでは2000GFlops/kW程度になっているのに対して、Top50システムでは1500GFlops/kW、Top500システム全体では1000GFlops/kWとTop10に比べて半分の効率でしかない。●今後もBellの法則は成立するのか?○Gordon Bell氏が提唱したBellの法則Gordon Bell賞の創始者であるBell氏は、おおよそ10年ごとに新しい重要なクラスのコンピュータが出現するというBellの法則を提唱した。次の右上の図は、それぞれのアーキテクチャのシステムがTop500システムの中で占める割合を示したグラフで、1994年頃まではベクトルスパコンの時代であった。しかし、それ以降は、(IBMのPOWERや富士通のSPARC64のような)カスタム設計されたスカラCPUを使うスパコンが多数を占める時代となり、これが10年程度続いた。まさにBellの法則が当てはまる状況であった。そして、2003年頃になると、x86などの市販の汎用プロセサを使う小規模サーバをクラスタ接続するマシンが主流を占めるようになり、この状況は現在も続いている。アクセラレータを使うマシンが増え始めているが、近い将来、これが主流となり、汎用CPUだけのクラスタシステムの時代が終わって、Bellの法則が成り立つようになるのかどうかは、まだ分からない。Top500スパコンの性能の伸びがこのところスローダウンしていることは明らかであるが、2015年から2017年頃に掛けて、100~数100PFlops級のスパコンの設置計画が米国や中国をはじめとしていくつか出てきており、現在のスローダウンは一時的なものであるという見方もある。一方、ムーアの法則もスローダウンしており、テクノロジの伸びとスパコン性能の伸びの乖離が大きくなり、システムが巨大化し、コストも高くなるので、Top500級のスパコンの調達がスローダウンしてきているという見方もあり、どちらが正しいのかは、まだ、はっきりしない。次の2つの図は、国別の性能合計の伸びと、今回のTop500リストでの国別のシステム数を示すパイチャートである。国別の性能合計では、米国が一貫してトップを走っており、EU全体の合計の性能も、概ね、米国の線と並行で推移している。日本と中国の線を見ると、中国の急速な性能向上が目立つ。2010年以降でいうと、京コンピュータの完成で一時的に逆転したが、それ以外では、中国の性能合計が日本のそれを上回っている。国別のシステム数では、米国がほぼ半分の46%を占め、中国が12%でそれに続いている。こちらのグラフはEU全体のまとめでなく国別になっており、日本、英国、フランス、ドイツの各国が5~6%というレベルで並んでいる。Top500の世界では、このところの性能の伸びのスローダウンが今後どうなっていくのか、近い将来、現在の汎用CPUだけのコモディティクラスタの時代が終わり、新しいクラスのコンピュータの時代に変わるのかが注目される。また、Top500は密行列を計算する性能を測っているが、これでは現代の問題を代表していないということから、HPGMGやHPCGベンチマークが提案されており、これらのベンチマークで測ると、性能の伸び方が、ある程度変わって見えることになるかも知れない。Bellの法則の新しいクラスのコンピュータは、HPLの計算性能を上げるのではなく、ストレージを含めてビッグデータの処理性能を画期的に引き上げるという方向に行く可能性が高く、HPL性能で計測している限り、新しいクラスのコンピュータの台頭は見えないかも知れない。Top500の分析は、どのようにスパコン界が動いて行くかについて考えるヒントを与えてくれるが、スパコン界の動きを理解するためには、Top500以外のより広い範囲の分析も必要となる。そしてスパコンへの投資額は、国家間の競争や安全保障などにも影響される。その点で、中国の急速な台頭や国別のシェアもスパコン界の動向に影響を与える重要な要素であり、スパコン界は目が離せない状況となっている。
2014年12月10日
SC14でのGreen500の1位に輝いたのは、ドイツのダルムシュタットにあるヘルムホルツセンターの「Lattice-CSC」というスパコンである。スコアは、5271.87MFlops/Wで初めて5GFlops/Wを超えた。2位は高エネルギー加速器研究機構(KEK)のSuiren(睡蓮)の4945.63MFlops/W、3位は東工大のTSUBAME-KFCの4447.58MFlops/Wで、4GFlops/Wを超えたのはこの3システムだけである。恒例であるが、1位から3位には表彰状が手渡され、その後、1位のチームは、どのようにして高スコアを実現したかなどについて発表を行うことになっている。L-CSCは量子色力学の計算を行うために設置されるシステムで、計算ノードは、ASUSの2ソケットサーバで、CPUは10コアのIvy-Bridgeを2個使用し、それに4台のAMDのFirePro S9150 GPUを接続している。最終的には160ノードのシステムになる計画であるが、まだ、システム構築中で、今回の結果は56ノードで測定されている。ソフトはGPLライセンスで入手できるオープンソースのCALDGEMMとHPL-GPUをカスタマイズして使っているという。次の図に示すように4GPUまでは完璧に性能がスケールしている。次の図に示すように、実線のCPU処理時間が破線のGPU処理時間を下回っていれば、パイプライン処理がうまく働き、全体の95%以上でこの条件が成立している。そして、DGEMMはGPUだけでやらせる方法とCPUとGPUで処理分担する方法を実装しており、両者を使うと2-5%性能が高くなるが、GPUオンリーの方が3-4%エネルギー効率が高い。このため、両者をダイナミックに使い分けているという。なお、このグラフで、GPUオンリーの処理の場合、CPU時間は非常に短く、GPU処理時間が長くなっている。一方、両者を使った場合は、GPU処理時間は多少減り、CPU処理時間は長くなっているが、それでも、概ね、GPU処理時間を下回っている。また、DTRSMについてもGPUに一部オフロードすると、残った行列のサイズが大きい場合は性能上有利であるが、行列サイズが小さくなると逆転するので、これもダイナミックに切り替えてその時点で最良のものを使っている。また、CPUはDVFSを使って最良の条件で動かしている。一般的には低いクロックの方が効率が高いが逆転する場合もあるので、それぞれの時点で最適のクロックを選んでいる。これらの動作条件のダイナミックなチューニングに加えて、GPUにもDVFSを適用し、処理の初期のCPU負荷の小さいときや処理の終盤のGPU負荷の小さいときは、不要なCPUやGPUは低電力状態にしてしまってエネルギーを節約している。そしてハードウェアとしては、HDDを使わない、温度にあわせてファンの速度を調節して電力消費を減らしている。Level 1ではルール上は、コアフェーズの最初と最後の10%の期間を除いた、20%の期間の消費電力を測れば良いことになっているが、70%-90%の期間をとると最後に消費電力が減っているので、この登録ではコアフェーズ全体の消費電力を計測した。結果として56ノードで5295MFlops/Wとなったが、これにInfiniBandスイッチの消費電力257Wを追加して、5271MFlops/Wの値をGreen500に登録したという。これを電力が減少する70%-90%の区間で測定すると、InfiniBandスイッチの電力を含まない値であるが、6010MFlops/Wとなり、問題の規模を小さくして測定すると、6900GFlops/Wまでスコアを上げられるという。このため、電力測定は20%の区間でなく、コアフェーズ全体とすべきと主張している。Level 1ではシステムの1/64を測定すれば良いという点では、一部の良いノードだけが選択的に測定されてしまう恐れがあるので、全体を測定すべきという意見と、100kW以上の大電力を高精度で測るのは難しいので、部分的な測定を認めるべきという両方の意見を併記している。
2014年12月09日
とんかつ専門店「かつや」を運営するアークランドサービスは12月19日、からあげ専門店「からやま」を神奈川県相模原市にオープンする。同店は「伝説のからあげ! からあげ 縁 - YUKARI -」等を運営するBAN FAMILYとのコラボレーションにより誕生した。「かつや」等の運営で培ったノウハウにより、定食、丼や鉄板メニューなど、幅広いバリエーションを取りそろえる。「からやま丼」(490円)は、からあげを卵でとじた丼メニュー。「鉄板極ダレ定食」(690円)は、からあげを鉄板に乗せて熱々の状態で提供する。3種類のつけダレで食べる「からやま定食(竹)」(690円)のほか、からあげ総重量約1,000gの「デカ盛りからやま定食」(1,990円)も用意する。また、からあげを最後までおいしく食べられるように「からあげ縁」の「極ダレ」も常備。100種類以上のバリエーションとなる「からあげ縁」のタレの中から、厳選した数種類を提供する。店舗では、食事を提供するだけではなく、持ち帰りコーナーも設置。複数種類のからあげを、常時グラム単位で量り売りする。※価格はすべて税別
2014年11月20日
2014年11月17日に、開催中のSC14において、NVIDIAは最上位の科学技術計算用のGPUとなる「Tesla K80」を発表した。SC14の会場で、Tesla部門のジェネラルマネージャーのSumit Gupta氏にK80について話を聞いた。新開発のMaxwellアーキテクチャのGPUの登場が期待されていたのであるが、K80はその名前が示すようにKeplerアーキテクチャのGPUを使っている。Maxwellはどこに行ってしまったのかと聞くと、今日はMaxwellベースのTesla製品の発表は無い、現在はこれしか言えないという回答であった。それはともかく、今回発表のK80はTesla製品としては最上位に位置する製品で、GPU Boost時の最大性能は、単精度浮動小数点演算では8.74TFlops、倍精度浮動小数点演算では2.91TFlopsとなっている。これは従来の最上位製品であるK40が、それぞれ5TFlops、1.66TFlopsであったのと比較すると、約1.75倍の性能向上である。また、GDDR5メモリの容量は24GBとK40から倍増し、メモリバンド幅も288GB/sから480GB/sと67%増加している。従来のK40はGK110Bチップを1個使用しているが、K80はGK210という新GPUチップを2個使用している。従って、1.75倍の演算性能といっても、GPUチップあたりの性能ではGK210は0.83倍程度の性能である。GK210は新規のGPUチップで、レジスタファイルの容量とシェアードメモリの容量がGK110Bと比較して2倍になっているという。従来は、レジスタ数やシェアードメモリの使用量の制約でコンカレントに実行するスレッド数が抑えられていたケースでも、これらのリソースが増えたことにより多くのスレッドをコンカレントに動かすことができ、リコンパイルなしに性能があがるケースが出てくるという。K40の2倍のGPUチップと2倍のGDDR5メモリを搭載しているので、消費電力が気になるところであるが、K40の235Wに対して、K80の消費電力は300Wとなっており、2倍ではなく、28%の増加に収まっている。このため、K80を普通のサーバに内蔵して、空冷で使うことができるという。K40のベースクロック動作時の性能が1.43TFlopsであるのに対して、K80のベースクロック時の性能は1.87TFlopsであり、これはGK210 1チップでは0.935TFlopsとK40のGK110Bよりもかなり低くなっている。この1つの理由は、K40は2880CUDAコアを持つのに対して、K80のGK210では2496コアと13/15のコア数であるからである。しかし、これだけでは性能の差は説明できない。もう1つの大きな差は、K40のベースクロックは993MHzであるのに対して、K80のそれは749MHzに低下しているからである。一方、GPUブーストを使うと、K40は1153MHzであるのに対して、K80は1166MHzとほぼ同じクロックとなる。これは、どちらも同じ程度の周波数で動作することができるチップであるが、K80の場合は消費電力を抑えるため、ベースクロックの周波数を下げているためと考えられる。ベースクロックを約80%に下げることにより各チップの消費電力をほぼ半減させることができると思われ、GK210 2チップ合計でK40のGK110Bと同程度の消費電力になると思われる。メモリ容量はK40の12GBに対して、K80では24GBになっており、各GK210チップに12GBずつGDDR5メモリが接続されていると見られる。メモリバンド幅はK40の288GB/sに対してK80は480GB/sであり、K40では3GHzクロックであるのに対してK80では2.5GHzクロックとなっている。これは2割弱の低減であるので、2倍のGDDR5 DRAMの消費電力は、合計では1.7倍程度に増加する。さらに、K80では、CPUからの×16のPCIe 3.0を2個のGK210に接続するために、PLXのPCIeスイッチを使っている。このチップの消費電力は10W弱である。結果として、ボードの消費電力が65W増加というのは妥当な線である。なお、PLXのスイッチは2個のGK210 GPU間の転送もサポートしており、一方のGK210が他方のGK210に接続されたメモリをアクセスする場合は、外側のPCIeを使わず、PLXスイッチ経由で直接データ伝送ができるので、シングルチップのPCIeボードを2枚使用するより効率が良いという。K80とK40をXeon E5-2676v2と比較したものが次の図である。ただし、この比較は、K40、K80を動かすためXeon E5-2697v2が使われており、CPU単独の性能とCPU+GPUの性能を比較している。従って、CP2KやQuantum Expressoの場合は、GPUを付けてもあまり性能は上がらず、費用や消費電力あたりの性能は低下していると思われる。しかし、その他のアプリではCPU単独の2倍以上の性能が得られているので、GPUのコストがCPUと同等と考えれば、GPUの接続はコストの面でも効果的ということになる。多くのアプリケーションで、K80はK40より2~4割程度高い性能が得られている。しかし、K80の価格がどうなるかが問題である。この点について質問すると、ハイエンド製品の価格はほぼ一定で推移しており、K80の価格は、現在のK40と同等になるとのことであった。その時には、K40の価格は引き下げられ、K80との性能比に見合った価格になると予想される。
2014年11月18日
スーパーコンピュータ(スパコン)関係の最大の学会であるSC14が、開幕した。今年の開催地はNew Orleansで、ここでの開催は2010年から5年ぶりである。主催者側によると、事前登録した今年の参加者は約1万人で、昨年と同等のレベルであるという。SCではチュートリアルや特定分野のワークショップ、企業や研究機関の展示、本会議という大きく分けて3つのアクティビティが行われる。11月16日の日曜が開幕であるが、日曜と月曜はチュートリアルとワークショップという日程で、SC14本会議は18日の、主催者の挨拶と基調講演から始まる。そして展示は、17日の午後7時のOpening Galaからとなる。Opening Galaでは食べ物や飲み物が振る舞われ、ビールを片手に展示ブースを回るという姿が多く見られる。ここで、どのような展示があるかの目星をつけて、翌日から19日午後3時までの展示期間にどれを詳しく見るかという作戦を決めることになる。今年は、スパコン関係では日本の顔とも言える東京工業大学(東工大)の松岡聡 教授がSidney Fernbach賞を受賞し、記念講演を行うので、そのポスターが各所に立っている。なお、Cray賞は、元NECの渡辺氏、元富士通の三浦氏が過去に受賞しているが、学術的な業績を評価するSidney Fernbach賞の日本人の受賞はこれが初めてである。また、今年は、超弦理論などの宇宙論で最先端を走り、同時に、一般向けのベストセラーの解説書を多く書いているBrian Greene教授が、幕開けの基調講演を行う。SCの基調講演は、毎年、注目の人が行うが、今年も面白そうである。さらに、今年はCDC(Center for Decease Control and Prevention)が感染症の伝染を防ぐために、スパコンがどう使えるかという発表を行う。取り扱っているのは仮想的な感染症であるが、この手法は、エボラなど現実の脅威にも適用できるものであり、重要な研究である。基調講演や、論文発表も重要な最新情報を得るチャネルであり、SCに参加する理由であるが、SCのもう1つの見どころは、企業や研究機関、大学などの展示である。今年は360の展示ブースが並ぶ。今年も、HP、NVIDIA、DELL、Micronなどが中央の目貫の場所に大きなブースを構えている。そして若干離れてIntelの大きなブースがあるという具合である。また、小さなブースでも興味深い技術を展示しているところもあり、見逃せないが、すべてをじっくり見るには時間が足りないというジレンマがある。また、これまで何度か誌面で取り上げられてきたExaScaler/PEZYがTop500、Green500に挑戦する。小企業の挑戦がどこまで通用するのかも興味深い。マイナビニュースでは引き続き、SC14での発表、展示をカバーして行く予定である。
2014年11月17日
エプソンは、プロ写真家や写真愛好家向けのA3ノビ対応8色顔料インクジェットプリンター「SC-PX5VII」を11月6日に発売すると決定した。価格はオープンで、推定市場価格は税別90,000円前後だ。SC-PX5VIIは、プロ写真家や写真愛好家に向けたエプソンプロセレクションシリーズの新製品。2014年9月2日の発表時には発売予定を11月上旬としていたが、このたび発売日を正式に決定した。新開発のインク「Epson UltraChrome K3 INK」で描写力が向上した。とくに新フォトブラックインクは、インクを包む樹脂に従来機の1.5倍となる密度で顔料の色材を配合し、黒濃度を向上。より深みのある黒、より滑らかなグラデーション表現を可能にする。
2014年11月05日
NTTドコモが冬春モデルとして発表した「GALAXY Tab S 8.4 SC-03G」(サムスン電子製)は、専用のキーボードを搭載した8.4インチのAndroidタブレット端末。発売時期は12月中旬以降で、価格は未定。GALAXY Tab S 8.4 SC-03Gは8.4インチSuper AMOLEDディスプレイ(1,600×2,560ピクセル)搭載のAndroidタブレット。タブレットと一体となる専用のBluetoothキーボードを搭載し、ノートPCスタイルでもタブレットスタイルでも使うことができる。ディスプレイにはSuper AMOLEDを採用。液晶では表現しづらい、深いエメラルドグリーンのような緑系の色も忠実に再現する。そのほか、2つのアプリを同時に使用できる「マルチウィンドウ」機能を搭載。PCのようなマルチタスクの使い勝手を実現している。また、「SideSync」機能によって「GALAXY」スマートフォンと連携させることで、手元にスマートフォンがなくてもタブレット上で、着信やメールを受信できる。主な仕様は以下の通り。OSはAndroid 4.4、CPUはクアッドコアのMSM8974(2.3GHz)を搭載。内蔵メモリは3GB、ストレージは32GB、外部ストレージはmicroSDXC(128GB)に対応する。サイズ/重量は、約213(H)×約126(W)×約6.6(D)mm/約298g。バッテリー容量は4,900mAh。背面には約800万画素、前面には210万画素のCMOSカメラを内蔵する。防水/防塵には対応していない。通信面では、受信時最大150Mbps、送信時最大50MbpsのXi(2GHz/1.7GHz/1.5GHz/800MHz)、FOMAハイスピードをサポート。また、LTE/Wi-Fi同時接続による高速ダウンロード機能に対応。そのほか、IEEE802.11a/b/g/n/acに準拠したWi-Fi、Bluetooth 4.0、ワンセグ/フルセグなどに対応する。なお、VoLTE、赤外線通信、おサイフケータイ、NFCには対応していない。(記事提供: AndroWire編集部)
2014年10月02日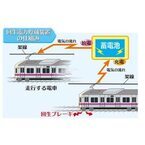
京王電鉄はこのほど、相模原線堀之内変電所にて、今年度中に回生電力貯蔵装置を導入すると発表した。同社はこれまで、京王線・井の頭線全車両に回生ブレーキを装備し、車両がブレーキをかけた際に発生する回生電力を、近くにいる他の車両に架線を通して供給していた。回生電力貯蔵装置の導入により、今後は近くに電車がいないために利用されなかった電力を貯めておくことも可能になるという。貯蔵した電力は電車の走行用電力として供給されるため、電力のさらなる削減につながる。堀之内変電所に設置される電力貯蔵装置は、設備容量2,145kW、最大充放電電流 1,300A(定格電圧DC1,650V時)の日立製作所製リチウムイオン電池。京王電鉄は回生ブレーキに加え、電車の加速力や速度に応じて電圧・周波数を変化させながらモーターを効率良く動かすVVVFインバータ制御装置も全車両に装備している。これらの装置の導入により、電車1両が1km走行するのに必要な消費電力量を、導入前より約45%削減することに成功しているという。
2014年05月30日
三井広報委員会は3月15日、少年野球の指導者を対象とした野球教室「三井ゴールデン・グラブ教室」を神奈川県のサーティーフォー相模原球場にて開催する。○守備のスペシャリストを講師に招く三井グループ企業25社で構成する三井広報委員会が2010年にスタートさせ、年2回開催してきた「三井ゴールデン・グラブ教室」。同教室は現役時代にゴールデン・グラブ賞を受賞した元プロ野球選手の指導のもとで、野球指導者に正しい野球知識を習得してもらうことを目的としており、今回で9回目となる。今回の相模原教室は、サーティーフォー相模原球場にて開催。午前中に指導者講習会やバッテリーの基本、午後には守備の基本(内野手・外野手)など、"守備"を中心とした野球の基本技術とその指導方法についての講義や実技指導が行われる。予定講師は、日本ハムOB西崎幸広氏、ヤクルトOBの大矢明彦氏と宮本慎也氏、巨人OB屋鋪要氏とNSCA認定パーソナルトレーナーの石川慎二氏。日時は3月15日の9時10分から15時10分。参加資格は少年野球指導者などで、参加人数は120人。参加費は無料。申し込みの締め切りは2月14日までとなっている。詳細及び申し込みは三井広報委員会オフィシャルサイト内「三井ゴールデン・グラブ野球教室」ページにて。
2014年01月23日




















