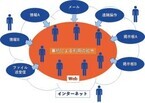
近年IoT(Internet of Things)という言葉を聞くようになりました。日本政府が出す「日本再興戦略」改訂2015でも、ビッグデータやAI(人工知能)と並び、ビジネスや社会そのもののあり方を根底から揺るがす改革の要因として扱われています。今回は、IoTのその先にある「WoT」について解説していただきます。○Webがインターネットにもたらしたもの「インターネット」が世界に浸透し始めたのは1980年代です。当時はさまざまな通信規格が存在していましたが、徐々にTCP/IPという通信規格の採用が広がり、世界中に散らばっていたネットワークが1つに繋がりだしました。しかしながら、ネットワークが繋がったといえ、情報は世界各地に散らばっている状況でした。例えるならば、世界中に手紙が届くようになったものの、人々はどこに手紙を送ればいいか分からず、手紙の文面の言語が目的ごとに異なったのです。ニュースを見たり、メールを送ったり、テキストを送ったり、ファイルを送ったり……etc。それぞれのサービスごとに言語があり、専用アプリケーションがありました。「Web」が登場したのは1990年代です。世界中にばらばらに存在していた情報を、テキストや画像で表現してドキュメント化し、「ハイパーテキスト」という方法でつなぎ合わせる仕組みと、その言語であるHTML(HyperText Markup Language)、通信規格のHTTP(HyperText Transfer Protocol) が生み出されました。その後、必要な情報を探すための「検索エンジン」も登場したことで、世界中の情報へ素早く、簡単にアクセスできるようになり、Webの求心力がさらに高まっていったのです。これらの技術を下支えしたテクノロジーが、「HTML/HTTP」を解釈し、PCやスマートフォン上で表示するアプリケーション「Webブラウザ」です。Webブラウザは、"基本的"にはOSやWebブラウザの種類などの環境に依存せず、同じように情報を利用できます。このように膨大な情報を容易に利用できる基盤ができたことで、ネット上の情報提供やビジネスが容易になり、その後の爆発的な普及の要因となりました。現在では、国際的な標準を定めるW3C (World Wide Web Consortium)で、さまざまなWeb技術の標準化作業が行われています。より多彩な表現ができる「HTML5」や、高性能化した「HTTP/2」への進化、「JavaScript」というスクリプト言語などを組み合わせて、今までOSごとに作成されていたアプリケーションが、Webブラウザ上で簡単に表現されるような世界になりつつあります。Webは多くのPCやスマートフォン上で動作します。つまり、単なる"情報"から、アプリケーション実行環境まで提供する巨大なプラットフォームへと成長したわけです。○WebがもたらすIoTの進化Webの存在や成り立ちは、IoTにも応用できます。今までのIoTは、個別のサービスごとに適した独自の通信規格や動作環境を用いて、独立したシステムを構築することが大半でした。それぞれのシステムが中に閉じてしまい、個別に情報が存在している状況です。それぞれのシステムとしての価値を生み出すことはできますが、"個"を超えて膨大な情報に基づいた、より付加価値のあるサービスを生み出すためには共通に利用できる基盤が必要です。そのために、最近ではIoT機器を共通に繋げるための規格や枠組みを議論したり、手を組んで広げていくコンソーシアムやアライアンスが組まれています。しかし、これらはIoT機器が繋がる通信規格のみや提唱するベンダーに依存したものとなってしまいます。一方で、このIoTの共通基盤をWebのプラットフォームを活用して実現する考え方が「WoT (Web of Things)」です。WoTの強みは、すでに広く普及している相互接続可能な通信規格と、ハードウェアやOSに依存しない「HTML5/JavaScript」による動作環境、さらにこれらは「IETF」や「W3C」という特定の組織に依存しないオープンな標準化組織による規格、取り組みという点です。オープンであることで、さまざまな環境に対して強靭に鍛えられ、自由に幅広く使えるものになります。これに加えて、通常のIoT開発では、ネットワークやソフトウェア、ハードウェアごとに幅広い知識が必要になりますが、WoTではHTML5/JavaScriptという広く普及した言語で開発でき、多くの技術者や情報が存在しています。また、繰り返しにはなりますが、基本的にハードウェアやOSへ依存しないため、さまざまなネットワークやデバイスで動作することができます。このIoTとWoTの枠組みの比較を下図に示します。WoTは、さまざまなデバイスで動作し、容易に開発できる共通のIoT基盤を志向するものです。これまでも相互接続という部分では、Web APIという形で、多くのサービスが外部に情報を公開する取り組みを行っています。例えば地図や天気、ニュース、特定の機器情報などはWeb API経由で取得可能です。また、情報にアクセスしやすいように「Linked Open Data」という"データのWeb"と呼ばれる情報ネットワークが提唱されています。WoTはこれらとも親和性が高く、既存の膨大な情報の活用も容易になるのです。動作環境も、Webブラウザ上で動くだけでなく、Webアプリケーションが各OS用のアプリケーションと同様に実行できる環境もスマートフォンを中心に整ってきました。さらに、「Web OS」という、ハードウェア上で直接Webアプリケーションが実行できる軽量なOSも登場しています。代表的なものは、PC向けのChrome OSやスマートフォン向けのFirefox OSです。すでに日本国内でもこれらの製品として「Chromebook」や「Fx0」が発売されています。さらに小型の機器向けには、JavaScriptが直接実行できるマイコンボードなどが発売されています。このようにWoTは幅広く発展してきたWebのプラットフォームを活用し、IoTをより加速、発展させる取り組みなのです。著者プロフィール○小森田 賢史(こもりた さとし)KDDI 商品・CS統括本部 商品企画部モバイル通信(SIP, IMS)の高度化に関する研究開発、IEEE標準化活動を経て、オープンソース系OSを活用したスマートフォン端末の企画開発、IoT機器・プラットフォームの企画開発、新規商品企画を担当する。
2015年12月11日
○人工知能のブームは期待感が先行内外の自動車メーカーが自動運転のテストを始めたり、人とコミュニケーションできるロボット「Pepper」の販売が開始されたりするなど、ここ数年、人工知能に関する話題が増えている。人工知能を使った製品・サービスへの期待は、日増しに高まっているようだ。その一方で、人工知能が人間の仕事を奪い、最終的には人間を駆逐してしまう危険性について言及する研究者も存在する。例えば、今年の7月、天体物理学者のスティーブン・ホーキング博士、テスラ・モーターズの創業者・イーロン・マスク氏、Appleの共同創設者・スティーブ・ウォズニアック氏らが、自律型兵器の禁止を訴える書欄を公開した。人工知能がもたらす未来がどのようなものになるのか、われわれ人間にとってそれは望ましい未来なのかということも、いまだ解決していない疑問である。「人工知能は、これまで地道に研究が進められてきた分野であって、最近になって突然始めたものではありません。しかし、このところ急に人工知能がブームになり、多くの人から注目されるようになったと感じています」と語るのは、東京大学大学院工学系研究科技術経営戦略学専攻准教授の松尾豊氏だ。松尾氏は、人工知能とWeb工学を専門としており、これまで人工知能(推論、機械学習、ディープラーニング)、自然言語処理、社会ネットワーク分析、ソーシャルメディア、Webマイニング、ビジネスモデルの研究を行ってきた。○「認知」できるようになった人工知能人工知能の研究が始まった1950年代から、さまざまな研究が進められてきた。それらの中で、脳の神経活動をモデル化したニューラルネットワークや深化の過程をシミュレートする遺伝的アルゴリズムなども開発された。また、人工知能を「仕事」に活用できないかという観点からの研究も行われ「エキスパートシステム」という職業に特化したシステムも開発されてきた。しかし、これらの人工知能は、コンピューターで処理できるように、あらかじめ人間が判断の条件を定義しておくなどの前準備が必要だった。つまり、人工知能は限られた領域においては効果を発揮できるものだったが、そのためには必ず人が介在し、準備をする必要があったのだ。「例えば、人間は"机"を見た時に机だと"認知"します。ちゃぶ台やカウンターテーブル、場合によっては何かに板を渡しただけのものであっても、それを机だと認識できます。しかし、人工知能はそうではありません。"四角い板に4本の足がついているもの"といったように、まず"机"を定義する必要がありましたし、それ以外のものを机と認識することはできませんでした。これは、コンピューターが机の"特徴量"、言い換えれば、机そのものの本質や概念を自分で作ることができなかったことに起因します。ここに、人工知能の壁がありました」と、松尾氏はこれまでの人工知能について説明する。○ものづくり」と相性がよい人工知能ここ数年、科学者たちの間で研究されてきたのが、この「人工知能の壁」を突き破る技術「ディープラーニング」だ。このディープラーニングを用いることで、特徴量を抽出できるようになったのである。これによって、人工知能はついにこれまで不可能とされてきた「認知」ができるようになった。先述の例にあてはめれば、"四角い板に4本の足が付いていないもの"でも"これは机として使われているもの"と認知できるようになったのだ。人工知能が認知を獲得して何が起きるのかというと、これまで必要とされてきた「人の手」が不要になり、人工知能が単体で機能できるようになる。その具体例が、「顔認識」だ。これまで顔認識においては、人工知能よりも人のほうが優れていた。しかし最近では、人工知能のほうが高い精度の結果を出すようになったのだ。もちろん、まだ静止画から特徴量を抽出できるようになったというレベルだが、近い将来、現実世界からも特徴量を抽出できるようになるだろう。ディープラーニングをきっかけに、これまで停滞していた人工知能の研究が、再び前進を始めたといっても過言ではない。現在、人工知能の研究は、驚くべきスピードで進められている。行動と結び付いた人工知能の適用範囲は、想像以上に広い。農業や工業、建築など、これまで人間でなければ作業できなかった現場においても、機械が代行できるようになる可能性が高いのだ。しかも、コストは圧倒的に低くなり、品質のばらつきも抑えることができる。そういった点では、冒頭で説明した「人工知能が人間を駆逐するかもしれない」という専門家の指摘は、ある意味、当たっているのかもしれない。とはいえ、人工知能ができる仕事は、人間が行ってきた「作業」を代行することのみだ。人間が進化の過程で獲得してきた感情や本能が関係する業務は、決して人工知能がとって代わることはできない。「これからの社会では、感情の部分がよりフォーカスされるようになるでしょう。人間はより人間らしい業務に集中できるようになるはず。言い換えれば、人間力がより重視されるようになると思います」と松尾氏は指摘する。「人工知能は、今後"行動"や"言語"と結び付いていくでしょう。"ものづくり"の現場にとって、"行動"と結び付いた人工知能のサポートは必要不可欠なものになっていくと思います。人工知能が、日本の経済活動において強みになることは間違いありません」と、松尾氏は語る。しかし残念ながら、現在は人工知能の急速な研究スピードに現場が追いついていない状況だ。「エンジニアの数が、まだ圧倒的に足りていません。エンジニアの育成には、一刻の猶予もありません」と松尾氏は証言する。そのために、東京大学では専門の教育を開始しているとのことだ。繰り返しになるが、人工知能のビジネス利用は、「ものづくり日本」にとっての強みになる。産学連携を進めて研究を進めていくことで、この隔たりもクリアできるようになっていくだろう。東京大学の教育が、その一端を担うことは間違いない。
2015年12月08日
UBICは12月3日、人工知能によるEメール自動監査システム「Lit i View EMAIL AUDITOR(リット・アイ・ビュー イーメール・オーディター)」において、中国における贈収賄行為につながるメールのやり取りを検知し、FCPA(連邦海外腐敗防止法)をはじめ、外国公務員への賄賂を禁止する法令の違反行為を防ぐためのオプションを開発し、提供を開始した。EMAIL AUDITORは、企業内のメールシステムからメールを取り込み、UBICの人工知能「KIBIT(キビット)」がメール本文や添付ファイルのテキストを読み込んだ上で、不正につながる可能性のあるメールを検知。日本語、英語、中国語、韓国語に対応し、人間による目視での監査に比べ、500分の1から1,000分の1に時間を短縮することができるという。これまで提供を行ってきた情報漏洩やカルテルなどの不正を検知するオプションとともに、国内外の電子・通信機器や機械、自動車関連部品などのメーカーや運輸などの企業に約8000IDを提供している。今回のオプションは中国での贈収賄行為の検知に特化し、中国語ならびに英語で不正につながるメールを検知するための知識や知見を集約した。導入企業はどのようなメールを見つけ出したいか、人工知能に教える学習期間がほぼ不要で、すぐに贈収賄行為につながるメールの発見に使用することを可能としている。同社によると近年、企業取引がボーダーレスになるとともに世界各国で外国公務員への贈収賄による不正な取引の摘発する動きが進んでおり、米国でのFCPAや英国の贈収賄禁止法をはじめ、中国や日本、ロシアなどでも外国での贈収賄に対する規制強化が行われている。特にFCPAでは、中国の政府関係者への贈賄が摘発され、1.35億ドルもの和解金を企業が支払うケースが発生するなど中国を中心にした贈収賄行為により、アメリカで司法当局に訴えられるケースが出ており、汚職の常態化が問題となっている中国に進出する企業は早急に対策を取る必要があるという。一方、監査部門の人員不足、不正行為を発見する知見や語学能力の習得が困難なことにより、企業が中国での贈収賄行為における問題の発見や防止は極めて難しくなっている。UBICでは、特に日本企業の進出が多く、文化的・慣習的背景の違いにおいても、贈収賄に対する監査が必要とされる中国に注目し、これまでの国際訴訟支援や海外企業のEMAIL AUDITOR導入の実績を通じて、贈収賄行為を検知するためのノウハウを蓄積し、同オプションを開発した。今後、中国へ進出している多くの日本企業をはじめ、世界各国のグローバル企業に提供し、コンプライアンスの遵守をサポートしていく。同オプションは、すでにEMAIL AUDITORの利用客は追加の導入設定費用60万円で使用することができるほか、新規でEMAIL AUDITORを導入する顧客は利用開始時から同オプションの利用が可能だ。
2015年12月04日
『マスク・オブ・ゾロ』や『エクスペンダブルズ3 ワールドミッション』など超大作に出演し、チリ鉱山事故を描いた最新作『The33』(原題)では主演を演じるアントニオ・バンデラスが、近未来を舞台にした『オートマタ』で本格SF映画に初挑戦。2016年3月5日(土)より全国公開されることが決まった。物語の舞台は、太陽風の増加により、砂漠化が進んだ2044年の地球。人類存亡の危機を迎えるなか、「1.生命体に危害を加えてはいけない」「2.ロボット自身で、修理・修繕をしてはけない」というルールを組み込んだ人工知能搭載ロボット“オートマタ”が開発され、人間に変わる労働力としてさまざまな分野で活躍していた。しかし、オートマタを管理するジャック(アントニオ・バンデラス)は、絶対に変更不可能とされていた2つ目のルールが破られたことに気づく。その真実が明らかになるとき、人類の繁栄は終焉を迎え、人工知能の時代が始まる…。人工知能搭載の家電や環境問題が取り沙汰されるいま、人類と人工知能との未来に警鐘を鳴らすかのような近未来リアルスリラーとなる本作。“荒廃した地球”“人工知能との共存”“ロボットの自己進化”といったテーマの数々は、決して絵空事ではなく、現実と地続きの驚きと恐怖を突きつける。人工知能搭載ロボット“オートマタ”を製造・管理するハイテク企業に務める調査員ジャック・ヴォーカンを演じるのは、アントニオ・バンデラス。シルベスター・スタローンやアーノルド・シュワルツェネッガーらと肩を並べるハリウッドスターが本作にて本格SF映画に初挑戦、製作にもかかわっている。さらに、『ピッチ・パーフェクト2』の“DSM”長官役ビアギッテ・ヨート・スレンセン、『エンド・オブ・ホワイトハウス』「アメリカン・ホラー・ストーリー」のディラン・マクダーモット、バンデラスの元妻であるメラニー・グリフィス、いぶし銀の名優ロバート・フォスターら実力派が脇を固める。メガホンを握るのは、長編デビュー作『シャッター・ラビリンス』(’09)がカンヌ国際映画祭「新人監督賞」にノミネートされたスペイン人監督ガイ・イバニェスで、その圧倒的なビジュアルセンスを本作でも発揮。併せて解禁となった場面写真では、“クーリオ”と呼ばれる物語のカギを握るオートマタと神妙な面持ちで対峙するジャックの様子や、その幻想的な色彩から本作の世界観を伺い知ることができる。『オートマタ』は2016年3月5日(土)より新宿ピカデリーほか全国にて公開。(text:cinemacafe.net)
2015年12月03日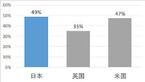
野村総合研究所(NRI)が12月2日に発表した推計によると、今後10~20年後に、日本の労働人口の約49%が就いている職業は人工知能やロボットなどで代替が可能だという。同試算は、同社未来創発センターが英オックスフォード大学のマイケル・A・オズボーン准教授およびカール・ベネディクト・フレイ博士と共同で、「“2030年"から日本を考える、“今"から2030年の日本に備える。」をテーマに行っている研究活動の1つ。人口減少に伴い、労働力の減少が予測される日本において人工知能やロボットなどを利用して労働力を補完した場合の社会的影響に関する研究をしているという。同試算では、労働政策研究・研修機構が2012年に公表した「職務構造に関する研究」で分類している、日本国内の601の職業に関する定量分析データを用いて、オズボーン准教授がアメリカおよびイギリスを対象に実施した分析と同様の手法で行い、その結果をNRIがまとめたとのこと。これによると、日本の労働人口の約49%が、技術的には人工知能やロボットなどで代替できるようになる可能性が高いと推計したという。一方、芸術、歴史学・考古学、哲学・神学など抽象的な概念を整理・創出するための知識が要求される職業や、他者との協調、他者の理解、説得、ネゴシエーション、サービス志向性が求められる職業は、人工知能などでの代替は難しい傾向があるという。しかし、必ずしも特別の知識・スキルが求められない職業に加え、データの分析や秩序的・体系的操作が求められる職業は、人工知能などで代替できる可能性が高い傾向が確認できたとしている。同社は今回発表した推計に関し、2016年1月12日に東京において、オズボーン准教授及び東京大学の松尾豊准教授を招聘し、研究報告講演会を開催する予定だ。
2015年12月03日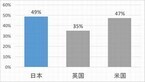
野村総合研究所(NRI)は12月2日、国内601種類の職業について、人工知能やロボットで代替される確率の試算結果を発表した。これは、英オックスフォード大学のマイケルA.オズボーン准教授およびカール・ベネディクト・フレイ博士と共同研究によるもの。試算は、日本国内の601の職業に関する定量分析データを用いて、オズボーン准教授が米国および英国を対象に実施した分析と同様の手法で行い、その結果をNRIがまとめた。それによると、日本の労働人口の約49%が、技術的には人工知能やロボットにより代替できるようになる可能性が高いと推計された。同様の調査で、英国では35%、米国では47%が代替可能という推計が出ている。この研究結果において、NRIは芸術、歴史学・考古学、哲学・神学など抽象的な概念を整理・創出するための知識が要求される職業、他者との協調や、他者の理解、説得、ネゴシエーション、サービス志向性が求められる職業は、人工知能等での代替は難しい傾向があるとしている。一方、必ずしも特別の知識・スキルが求められない職業に加え、データの分析や秩序的・体系的操作が求められる職業については、人工知能等で代替できる可能性が高い傾向が確認できたという。
2015年12月03日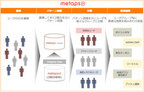
メタップスは12月1日、人工知能によりアプリ内のユーザ行動を学習し、継続率を改善するグロースハック自動化ツール「Metaps Automation」の提供を開始した。同社によれば、ツールを提供した背景に、アプリをダウンロードしたユーザの多くが、2日目以降にアプリを起動しなくなってしまう傾向があるという。「Metaps Automation」では、世界2億人以上のアプリユーザ動向の分析を行ってきたナレッジを活かし、アプリユーザの行動を人工知能がリアルタイムで分析し、離脱可能性の高いユーザを検知して、ポイント付与、割引クーポン、新規アプリ優先紹介などの施策を実施する。アプリ運営者は同社のSDKをアプリに組み込むことでサービスを利用でき、すでに「Metaps Analytics」が導入されていてプライベートDMP機能を利用の場合は、追加のシステム導入は不要で即座に利用可能だという。
2015年12月01日
日立製作所は今年9月、現場を理解して業務指示を行う人工知能を開発したことを発表、10月には人工知能で企業の経営課題解決を支援する「Hitachi AI Technology/業務改革サービス」を発表するなど、ビジネスに人工知能を活用する発表を積極的に行っている。「今回の発表につながる研究は、すでに10年以上前から行われていたものです。この研究をベースとしたものではありますが、サービス自体は実証実験ではなく、ビジネスとして提供する商品になっています」と、「Hitachi AI Technology/業務改革サービス」を担当する情報・通信システム社 スマート情報システム統括本部 ビッグデータソリューション本部 先端ビジネス開発センタ 技師の三輪臣弘氏は話す。これまで研究レベルにあった技術をサービスとして提供を開始した背景については、「ご存じのように、IoTの広がりも踏まえ、データが増大しています。われわれは、増え行くデータをどう活用すべきかについて、研究を行ってきました。この研究が商用サービスとして提供可能なレベルになったことから、サービスとして展開することが決定したのです」と、三輪氏は説明する。○人工知能による分析の特徴とは?ビッグデータに関してはすでに数多くのアナリティクス技術が開発されている。通常のアナリティクスは、人間の手で計算するものを選択し、答えを導き出すことになる。これまで手動で行われてきた作業を人工知能により行うことで、どんな違いが生まれるのだろうか。「手動で行うアナリティクスはこれまで、仮説を立て、そこに関係すると思われるデータを選び、分析を行っていました。それに対し、人工知能を活用することで、仮説を立てることなくデータを分析することができます。つまり、これまでは答えを導き出すために優先度が低いと思われてきたデータも活用することが可能になるのです。仮説が想定できるものは、従来のアナリティクスで十分だと思います。仮説が想定できないものは、このサービスを活用することで、新しい答えが見えてくることになります」(三輪氏)手動と人工知能のどちらを利用すべきかについて、厳密な切り分けの定義があるわけではない。ただし、三輪氏は「人工知能によるアナリティクスの結果を見ると、人間が手動で行うレベルを超えていると思います。データはあるけれど、答えがどこにあるのか見いだせない時、人工知能を活用することで答えが見えてくる場合があると思います」とAI活用で、手動のアナリティクスにはない可能性があると指摘する。○事例では予想外の結果から売上増を達成一方、人工知能を活用したユニークな事例も生まれている。アウトバウンド型の営業を行うコールセンターで、オペレーターの成績を上げることを目的に導入したところ、思わぬ結果が出たというのだ。通常のアナリティクスではオペレーターのスキルレベル、教育レベルなどのデータを分析する。これに対し、この事例では、名札型センサーを導入し、オペレーターの動きを評価データの1つとして取り入れた。「休憩時間に活発にコミュニケーションを行っているオペレーターほど売り上げが高くなっているという分析結果が出ました。通常の評価基準では取り入れられないデータでしたが、その後、コミュニケーションが活発になるような社内体制に変更を行ったところ、実際に売り上げが上がるという成果につながりました」(三輪氏)また、あるホームセンターでは、マーケッターの提案により棚の位置替えなどの施策を行ってきたものの、効果が出なかったことから、人工知能による分析を導入。その結果、ある場所に店員を立たせたところ、売り上げ増につながることがわかったそうだ。「どちらの事例も、これまでは切り捨てていたデータが、実は求めていた答えを出す要素になることもあることを明らかにしたものだと思います。このように、従来の業務改革だけでは解決策が生まれなかった分野において、人工知能が新たなチャンスを生む可能性があるのではないでしょうか」(三輪氏)人工知能による経営課題分析に関しては、「特に業界の絞り込みは行わず、広く活用を呼びかけていく計画です」と、三輪氏は話す。○これまでにはない可能性を企業にもたらす人工知能日立としては今後、人工知能を活用していく分野として、「顧客の業務へのサービスの組み込み」「リアルタイム処理」という2つを検討している。三輪氏は、同社が今年10月に開催した展示イベントで、同社の研究開発グループで人工知能を担当する技師長の矢野和男氏が話した内容を例にとり、人工知能の可能性を示唆する。「ロボットをブランコに乗せるとします。その時、ロボットはブランコのこぎ方を知りません。しかし、ロボットに『高く』という指示を出すと、リアルタイムで判断し、自分自身でこぐことを学習していくそうです。つまり、ロボットはリアルタイムで判断を行うことで、新しいことを学習していくことができるのです。この技術を応用すれば、これまでにはなかった新しい方向で、業務の見直しが行える可能性があります」日立では研究所で進めている研究、さらに顧客の現場での活用に結び付ける、「共創」という発想で、実用的な研究を行うことを目標としている。「人工知能に対しては、これまでにはなかった可能性を生み出せるのではないかと、上層部からも高い期待が寄せられています」という。もはや、人工知能は研究にとどまらない、実業を変化させる技術になりつつあるようだ。
2015年11月27日
ルネサス エレクトロニクス(ルネサス)は11月26日、人工知能ベンチャーであるクロスコンパス・インテリジェンスの人工知能技術を導入したソリューションを開発し、ルネサスグループのルネサス セミコンダクタ マニュファクチャリングの那珂工場の製造ラインで試験運用した結果、製造装置や産業機器などのリアルタイム異常検知が可能となる技術的な見通しが立ったと発表した。ルネサスが開発したソリューションは、同社のR-INプラットフォームに人工知能技術を実装したもの。同社のR-INエンジンは低電力で高速通信・高速処理が可能なため、大量のデータを上位のネットワークに低電力かつ高速で転送することができ、CPUの処理余力に人工知能技術を実装することで、データを高度な解析モデルで処理し、上位が必要な情報のみを送信することが可能となる。これにより、これまで見ることができなかった異常をエッジデバイスで検知し、リアルタイムに生産に反映させることができるようになるとする。また、上位の分析・解析との連携で装置間状態を詳細にモデリングすることで柔軟な生産が可能となり、エッジデバイスの解析結果を上位で時系列に解析し高度な予兆保全を実現することができる。なお、同社は12月2日から4日まで東京ビッグサイトで開催される「システム コントロール フェア2015」に出展し、那珂工場で検証した異常検知の成功事例および人工知能技術によって異常検知を簡単に確認できる技術のデモンストレーションを披露する予定となっている。
2015年11月26日
カラフル・ボードは11月26日、同社が運営するファッション人工知能「SENSY」が、EC接客サービスを同日より開始すると発表した。人工知能「SENSY」はユーザーのファッションセンスを学習していく人工知能。ユーザーは、表示される提携ブランド(現在2500ブランド以上)の服の「好み」を分類することで、人工知能がそのユーザーのファッションセンス「感性」を学習しユーザーの感性に沿ったアイテムやコーディネートを提案してくれる。また、モデルやタレント、スタイリストの人工知能も公開されており、そのセンス「感性」に沿って商品を選ぶ事も可能だという。今回第一号としてEC接客サービスを開始するのは、イケガミが運営する自社ECサイト「IKG crossing」(KATHARINE ROSS、Paradise Picnic、Cupid Heartの3ブランドをまたがるECサイト)。提供するのは、ECサイトにおけるユーザーヒアリング型接客、店舗とのデータ連動可能なオムニチャネル接客、ECサイト内のブランドをまたがる横断的コーディネートの提案接客、販売スタッフやモデルの人工知能による提案接客(実装予定)。今後、カラフル・ボードとイケガミは、ECサイトでの人工知能「SENSY」の活用だけではなく、店頭やマーケティング活用等、イケガミの培ってきた店頭接客技術に人工知能技術を使用した1人1人の好みに合わせたアイテムやコーディネートの提案力を活かし、未来に向けた新たなプラットフォーム構築を共にしていく考えだという。
2015年11月26日
ヤフーは11月26日、博士号を持つ修了者などを対象とした「サイエンスプロフェッショナルコース」と、博士研究員(ポスドク)などを対象とした「特任研究員コース」(任期付き)を新設して、毎年20名程度の博士号取得者とポスドクの採用を目指すと発表した。両コースで採用された博士号取得者とポスドクは、100以上のサービスから集まる同社独自のビックデータを活用し、「自然言語処理」「画像処理」「音声処理」「機械学習」「情報検索」「レコメンデーション」「コンテキストアウェア」「ヒューマン・コンピュータ・インタラクション」「大規模分散処理」「統計モデリング」「セマンティックウェブ」といった11分野の研究に携わる。研究成果は、同社の人工知能技術やIoT、広告技術などへ導入するという。また同社は、研究成果を積極的に国内外の主要な学会で発表していくことで、ほかの企業や研究機関との技術分野での連携拡大にもつなげていきたいとしている。
2015年11月26日
UBIC、同社の100%のRappa、ヴイストンの3社は11月17日、UBICの人工知能を搭載してヴイストンが設計・製造を行う生活密着型パーソナル・ロボットである「Kibiro」(キビロ)の開発と、Rappaによるビジネス展開の開始を発表した。KibiroはRappaを通じて、2016年前半に民間企業や公共団体など法人向けの提供を開始し、2016年後半に家庭向けへの提供を開始する予定だ。UBICとヴイストンはKibiroを、人々の暮らしに溶け込み共に過ごすことで日常を豊かにする生活密着型の人工知能搭載ロボットとして、開発を行っているという。Kibiroは、家庭や各種施設のテーブルの上でコミュニケーションを取りやすいという大きさ(高さ 約28.5cm×幅 約14cm)であり、利用者が親しみを感じるかわいらしい動作で反応するとしている。内蔵するカメラ/マイク/スピーカーによる会話のやり取りや、顔の識別などの基本コミュニケーションを行う他、ネットワークを介してUBICの人工知能エンジンである「KIBIT」(キビット)と接続し、専用アプリやメール、SNSなどを通じて、利用者の行動や好み、感覚を蓄積し、利用者自身も気付かなかった好きな物を勧めることもできるとのこと。公共施設や民間の商業スペースでは、その場の必要に応じたデータベースと接続し、利用者の役に立つ知識や情報を提供するとしている。胴体、首、腕で8つの自由度により、親しみを感じる動作や表現が可能で、内蔵カメラは人間の顔を識別し、人によって反応を変えることが可能だという。マイクとスピーカーからの発声で簡単な会話のやりとりを行い、生活の中でKibiroを身近に感じてもらうことができるという。人工知能エンジンであるKIBITは、これまでにUBICが行ってきた法曹・ビジネスの支援や医療分野、マーケティングに使われてきた実績を元に開発されている。少量のテキストデータのインプット(教師データ)で、選んだ人間の機微(個人の暗黙知・判断の仕組み・感覚)を理解することができ、利用者が気に入った趣味や生活上での衣食住などの好みをインプットすることで、Kibiroは、利用者の感覚をどんどん蓄積する。例えば、お店を探す時に、利用者の好みにぴったりなところをおススメ。また、飲食店を選んだ感覚をもとに、宿や本などのジャンルを越えたおススメも可能だという。さらに、利用者の好みの文脈を理解し、マッチングする情報を広く探すことで、利用者自身が気付かなかった意外な「好きなこと」をおススメする「驚き」も提供するとしている。Kibiroとのコミュニケーションは、会話によるものだけでなく、スマホ/タブレット用の専用アプリケーションやメール、SNSとの連携を予定。音声認識では聞き取りが難しい言葉も、テキストを送ることで、きちんとKibiroが理解することができるようになるという。Kibiroは、博物館や美術館、図書館、観光案内所などの公共施設、飲食店、書店、百貨店などの商業スペースや病院、ホテル、教育施設など、沢山の情報を保有・蓄積したり、滞在時間の長い利用者が多い拠点での設置を目指す。
2015年11月18日
NECはこのほど、人工知能(AI:Artificial Intelligence)技術の開発や、AI技術を活用したソリューション展開を強化すると発表した。これに伴い体制面の強化も図り、研究・開発やコンサルティングなどに関わるAI関連要員を、2020年度までに約1000人に拡充していくという。本稿では、NECのAIへの取り組みについてお届けしたい。○AI要員を1000人体制に拡充NECはAI技術の定義について、「学習」「認識・理解」「予測・推論」「計画・最適化」といった人間の知的活動をコンピュータで実現するものとしている。1980年代から関連技術の開発を進めるなど、同社のAIへの取り組みの歴史は長く、音声認識、画像・映像認識、言語・意味理解、機械学習、予測・予兆検知、最適計画・制御等の主なAI関連技術に関して、世界初もしくは世界トップレベルの技術を有しているという。同社の執行役員を務める江村克己氏は、AI関連事業への注力について次のようにコメントした。「当社は社会価値創造の取り組みを進めており、社会課題を解決する社会ソリューション事業に注力している。その中核となるビッグデータ・IoT・セキュリティなどの分野に、長年にわたり研究開発を続けてきたAI技術を積極に取り入れ、進化させていきたい。こうしてAI関連事業の強化を図るとともに、安全・安心な社会づくりなど、より大きな社会価値創造を実現していく」○防犯やマーケティングへの期待が高い新たなAI技術とは?NECは同日、「一歩進んだAI技術」として、新たに開発した「時空間データ横断プロファイリング」も発表した。この技術は、複数の場所で撮影された長時間の映像データから、特定のパターン(時間・場所・動作)で出現する人物を高速に分類・検索するというもの。NECが得意とする顔認証技術などと組み合わせることで、AI技術としての利用が可能となる。時空間データ横断プロファイリングは、大量の映像データから顔の「類似度」をもとにグループ化し、特定の出現パターンに合致する対象の発見が可能なアルゴリズム。この技術により、顔の類似性から同一人物と見なせる出現パターンを分類し、出現時間・場所・回数等での検索を行うことが可能となる。例えば、カメラ映像中の「同じ場所で頻繁に出現する人物」や「複数の場所に現れた人物」を発見し、防犯や犯罪捜査など、従来人手ではできなかった新たな知見や気づきを見いだす高度な解析を実現する。街角に設置されたカメラ映像中ののべ100万件の顔データを時空間データ横断プロファイリングにより解析したところ、同じ場所に長時間・頻繁に現れる人物の検索・抽出をたった10秒で行ったという。「この技術のポイントは、未知の事象を検出できることにある」と江村氏は強調した。NECは2016年度中に時空間データ横断プロファイリングを実用化し、今後、道に迷った観光客へのおもてなしや、振る舞い・表情から心情を理解するマーケティングなどへも展開していく予定。そのほか、江村氏は11月2日に発表した、予測に基づいた判断や計画をソフトウェアが最適に行うAI技術「予測型意思決定最適化技術」について解説を行った。同技術を適用した水需要予測に基づく配水計画では、浄水・配水電力を20%削減する配水計画を生成できたという。最後に江村氏は、将来を見据えた取り組みとして、脳型コンピュータの開発に向けた学術機関との連携の取り組みについても言及。「こうした新しいAI技術も非常に重要だ。NECとしてはオープンイノベーションで推進していく」と力強く訴えた。
2015年11月18日
UBICとUBICの100%子会社で人工知能を活用したデジタルマーケティング事業を行うRappa(ラッパ)、ヴイストンの3社は11月17日、記者会見を開きUBICの人工知能を搭載し、ヴイストンが設計、製造を行う新しい生活密着型パーソナルロボット「Kibiro(キビロ)」の開発と、Rappaによるビジネス展開の開始を発表した。同ロボットはRappaを通じて2016年前半に民間企業や公共団体など法人向けに提供を開始し、2016年後半に家庭向けへの提供開始を予定。価格は未定だが10万円以下を検討している。KibiroはUBICの人工知能エンジン「KIBIT(キビット)」を搭載し、ヴイストンが設計、製造を行い、高さ28.5cm、重さ約800gのサイズでシンプルな機構ながら誰にもなじみやすいデザインと胴体、首、腕で8つの自由度により、豊かで親しみを感じる動作や表現が可能。内蔵カメラは人間の顔を識別し、人によって反応を変えることができるほか、マイクとスピーカーからの発声で簡単な会話のやり取りを行い、生活の中で身近に感じてることが可能とし、家庭向けの提供時には複数の衣装を用意する。UBIC代表取締役社長の守本正宏氏はKibiroの開発について「経験に基づく勘である暗黙知を我々の技術で活用することができれば証拠解析の効率化が図れるのではないかという考えのもとに人工知能を開発した結果、KIBITが生まれた。これまでも警察官や弁護士などの暗黙知を学び、実際の業務に活用していたが、個人の好みや趣味嗜好、感覚なども学ぶことができるようになった。そのため一般の方々に我々の人工知能を活用してもらいたいと考え、ロボットへの活用に着手した」と述べた。また、ヴイストン代表取締役の大和信夫氏は「これまでのロボット開発は機械を人に近づける研究などを行っていたものの、現在は犬や猫などペット以上、人間未満のロボット開発を目指しており、個人の特徴・特性を認知する人工知能は重要なのではないかと考えていた。KIBITを搭載したKibiroは人々の暮らしの中に溶け込み、一緒に過ごすことで日常を豊かにすることを目指しているが、我々が目指す方向性も同じだ」と語った。Kibiroの特徴は内蔵のカメラ、マイク、スピーカーによる会話のやりとりや顔の識別などの基本コミュニケーションを行うほか、ネットワークを介して、KIBITとつながり、専用アプリやメール、SNSなどを通じて、利用者が気に入った趣味や生活上での衣食住などの好みをインプットすることで、Kibiroは利用者の感覚を蓄積。例えばお店を探す時に利用者の好みに合った店舗をレコメンドするほか、飲食店を選んだ感覚をもとに宿や本などのジャンルを越えたレコメンドも可能だ。さらに、利用者の好みの文脈を理解し、マッチングする情報を広く探すことで利用者自身が気付かなかった意外な好きなことをレコメンドも提供できる。同エンジンはこれまでにUBICが行ってきた法曹・ビジネスの支援や医療分野、マーケティングに培われた実績をもとに開発されており、少量のテキストデータのインプット(教師データ)で選んだ人間の機微(個人の暗黙知・判断の仕組み・感覚)を理解する。UBIC執行役員CTO行動情報科学研究所所長の武田秀樹氏はKIBITとKibiroの技術を紹介し「KIBITは学習・判断と知識の2つで成り立っており、学習・判断には我々独自のアルゴリズムである『Landscaping』、知識には我々独自の考え方の行動情報科学を用いている。KIBITはビジネスの最前線ではマネージャーの判断や専門家の暗黙知をサポートするほか、一般ユーザーの感覚を学ぶことができる。Landscapingはテキスト解析に特化したアルゴリズムで、少量のデータから大きなデータを解析することだ。一方、行動情報科学は心理学などの行動科学、機械学習といった情報科学を組み合わせたものが行動情報科学だ。Kibiroは音声を通じてユーザーをガイドするとともに文字の情報を通じてタブレットなどのアプリケーションを介してユーザーとコミュニケーションをとり、その際にクラウド上に配置したKibitと連携し、好みの解析やレコメンド情報などを提示する」と説明した。最後にKibiroの事業展開についてRappa代表取締役社長の齋藤匠氏が登壇し「我々はKibiroが次世代のコミュニケーションデバイスとして重要な社会インフラになると考えている。Kibiroが人間と寄り添って人間と距離を近づけ、一般家庭に普及していくことで人間とKibiroがともに共存する社会が実現していくことを想像している。人間とロボットが共存していくためにロボット側に求められるのは人間のことを学び、考える人工知能技術が必要だ。Kibiroを売り出し、ロボットの一般家庭への普及と人間とロボットの社会共存が実現できるのではないか」と語った。
2015年11月18日
●Hadoop World 2015概要IT関連記事を見ていると、ビッグデータと一括りにされたテーマより、機械学習やAI(人工知能)といった手段の話を最近は目にする事が多くなりました。そのビッグデータの記事では、Hadoop等の基盤やツールの話が中心的存在でした。そのような状況の中で、Hadoopの立場は? Hadoop Worldに参加する意味は?という疑問に答えるつもりで今回のHadoop Worldに参加してきました。今年のHadoop Worldは昨年と同じくNew YorkのJavits Centerで開催です。例年は10月開催だったのが、少し早まり9月の開催となりました。日程は9/28(月)~10/1(木)までの4日間の開催で、9/28はCultivate、9/29はTraining, Tutorials &Cultivate、9/30及び10/1はKeynotes、Sessions&Trainingです。私は9/29~10/1まで参加しました。9/29のTutorials、9/30及び10/1のSessionsはパラレルセッションだったため、業務と密接な関係にあるData ScienceがテーマのTutorials及びSessionsを選択しました。昨年は5,500名の参加者がありましたが、今年は6,300名を超えたそうです。日本で開催されるHadoop関連のイベントはいずれも無料なので、もし、Hadoop Worldの参加費(New Yorkまでのエコノミー往復航空券相当)がせめて半額になったら、参加者はどれぐらい増えるのだろう?と思いました。イベントの内容は、昨年は非常にSpark周辺の話題が多く、名称もHadoop WorldよりもSpark Worldがふさわしいのでは?と思ったぐらいです。今年ももちろん、Spark関連の話題は豊富でしたが、Kuduなど新プロダクトの発表などもあり、相対的にSpark比率が昨年より下がり、Hadoop の復権を目の当たりにしました。以前に比べると、プロダクトの紹介だけでなく、その使い方や事例紹介の比率が高まっており、企業はデモ展示に力を入れています。○Tutorials:Hard core data scienceHard core data scienceは文字通り、データサイエンスのかなり深い部分についてのTutorialでした。アカデミック側の講演者は機械学習の手法、企業側の講演者は機械学習の実装やそれを用いたシステム構成について講演されていました。機械学習の手法ではTopic model、Submodularityに着目した最適化、Tensor Analysisといった最近の機械学習の分野(国際会議など)でホットなテーマを扱っており、非常にバランスがとれていました。Latent Dirichlet Allocation (LDA)に代表されるTopic modelは観測データの背後に有る潜在構造を仮定したモデルで、文書集合に適用した場合、単語集合(観測データ)からトピック集合(潜在構造)を学習します。学習した潜在構造が1)観測データの生成過程の説明能力を持つだけでなくだけでなく、2)観測データよりもデータ間の意味的な関係を捉え易いという特徴があり、機械学習の分野で人気のあるモデルです。そのためLDAは元々文書集合の生成過程をモデル化するため誕生しましたが、LDAを拡張したモデルが次々に提案されており、文書に留まらず、画像、ネックワーク解析やレコメンドにも使われその成果が数多く報告されています。多くの機械学習のライブラリにも含まれているので、目にした方、利用した方も多いと思います。そのLDAの産みの親の一人でもある、David M. Blei氏が登壇しました。講演はLDAの概要の説明から始まり、その拡張モデル、そして氏が最近取り組んでいるレコメンドへの適用を想定したモデルについて紹介していました。最近の国際会議は、大規模データへの適用に向けてLDAとその拡張モデルのスケーラビリティの向上が課題になっているので、この課題に対して産みの親のアイデアをもう少し聞きたいと思いました。Submodularity(劣モジュラ性)は最近、離散最適化(組み合わせ最適化)のアプローチとして注目されている数理的構造で、情報理論、グラフ理論などの数理科学だけでなく、経済学や心理学の社会科学でも見受けられます。講演では離散最適化の例として、スケジューリング、予算/資源/リソース配置、最短経路探索、ネットワーク設計、施設配置、都市計画などを紹介し、最適化の概要紹介が続きました。最適化問題は有限個の解の候補から最適な解を見つけるように定式化され、その解の良し悪しを評価するために用いる評価関数で、Submodularityを示すものが多く見られます。Submodularityを利用すると精度の良い解を効率的に発見できるため、この性質に注目した研究成果の発表件数が、国際会議で増えています。この講演ではこのようなSubmodularityの性質とそれを用いた離散最適化の研究紹介が中心でした。Tensor Analysisは多次元データの解析手法の一つです。例えば、センサデータから取得できる大量のデータ組やネットワーク構造などはTensorで表現でき、これらデータの構造圧縮や特徴抽出がTensor Analysisにより可能となります。Tensor Analysisを大規模データに対して適用する場合、通常のアルゴリズムが扱えるデータサイズはメモリの制約を受けますが、その制約を回避するために並列化のアプローチが注目されています。関連研究として、大規模行列の取り扱いの問題では、PCA(Principle Component Analysis)などを分散環境で実行する方法が提案されています。これに似た方法をTensorにも適用できないか?というのがこの講演者のアプローチでした。Tensor Analysisは音声認識の分野でも有名なHidden Markov Model(HMM)やNeural networkにも適用が期待できます。機械学習の並列化処理にとって、メモリ内で繰り返し処理を実行するSparkは現時点で理想的なフレームワークの一つであり、New York Times(30万文書、1億単語)を使った実験で、HadoopのMap-Reduceで4時間かかった処理時間を26分と大幅に短縮したとの報告がありました。 大規模行列の並列計算は最近話題のDeep learningにも関わっており、 別の講演者からSpark上でのNeural network training及びDeep learningの実行についての講演もありました。ユーザ視点からすると、機械学習にはどのような手法があり、どのように使えるのかがイメージしやすいと思いましたが、サイエンティスト視点からするともっと最新の技術について深掘りして欲しいと思われたかもしれません。後者の方はこの分野の国際会議でさらに調査すると必要な情報が得られると思います。企業側からは、Facebookの講演者は機械学習のプラットフォームの紹介とそのデモ、Microsoft Researchの講演者は三人居て、大規模ネットワーク分析の取り組み、クラウドソーシング、高次元データの取り扱いについてそれぞれ講演されました。このようにディープなテーマをHadoop Worldで扱っても会場は立ち見が出るほどの盛況で、参加者の数だけでなく興味の対象の広がりも感じました。今年のKDD(ACM SIGKDD Conference on Knowledge Discovery and Data Mining)ではClouderaが協賛したり、同じくClouderaの Amr Awadallah氏が講演されたりと、機械学習の世界とHadoopの世界は関係が深くなっています。私自身の現在の仕事に直接関係することも多く、非常に興味深いTutorialでした。個人的には企業側の講演で、これまで工夫した点や既存のツールの改善点などの話がもう少しあっても良かったのではと思いました。昨年のこのTutorialではJon Kleinberg氏が講演し、今年はDavid M. Blei氏、来年は・・・Michael Jordan氏 (AMPLab)では?と勝手に予想します。●Keynote&Sessionキーノートでは企業のFounder、 VP、CIO、 Fellowの方が自社の取り組みあるいは自社製品の紹介が中心でした。企業の場合、Keynoteは自社の社員や関係者が講演するSessionへの誘導となっているケースが多いです。アカデミック側から心理学や社会学のバックグランドを持つ研究者がその立場からビッグデータについて講演されていました。Tutorial/Sessionはパラレルで開催されため、参加者の興味や対象は絞られますが、Keynoteはシングルで最も多くの参加者を集め、かつ講演者の持ち時間が5~20分と非常に短いため、個々のテーマについて掘り下げるよりは、現在のトレンドやメッセージのインプットの場になります。テーマとしては半数以上が機械学習を何らかの形で取り上げていました。機械学習の応用事例というと半分、いやそれ以上の高い確率でレコメンドばかりでしたが、今年はそれ以外のコンシュマー向けのサービスも今年は増えていました。特に、Microsoft社の画像からそこに写った人の年齢を当てるというデモへの反響が大きかったです。ヘルスケアの事例では、分析環境を病院や研究機関に導入し、病気診断や予測に用いられている話がありました。全体的なトレンドとしては、クラウドの利用とリアルタイム処理です。秘匿性の高さでは世界有数と思われるCIAや、秘匿性の高さでは劣るかもしれませんが、データ量では世界有数と思われるNetFlixもオンプレミスでなくクラウド上でデータ分析処理を行っているそうです。最新の技術やトレンドに触れる機会もありますが、「人類が増えすぎたデータをクラウドに蓄積させるようになって、既に半世紀が過ぎていた。クラウドは人類の第二の頭脳となり、データはそこで・・・」と未来を連想する機会もあるのがKeynoteの良いところです。製品はCloudera社からの新プロダクトであるKudoの発表の反響が大きかったように思いました。KudoはHadoopのストレージであるHDFSやHBaseのギャップを埋めるプロダクトとして紹介されています。その後のKudoのセッションは部屋に人が入りきれないほどの盛況で、参加者の関心の高さを伺えました。また各製品はほぼ共通してIoT(Internet of things)のデータの標準的なフォーマットであるJSON、かつリアルタイム処理への対応が進んでいることが伺えました。他のSessionで紹介されたCloudera社から既に発表されていたIbisも興味深いプロジェクトでした。IbisはPythonでSparkを実行できるAPIです。これでPythonの使い手にとっては、PySpark(Sparkを実行できるPython API)以外の選択肢が増えたことになります。○企業ブース企業ブースは、スポンサー企業のブースが並び、一度足を踏み入れると、積極的に呼びかけられ、大学のサークルの新人勧誘を思い起こさせます。企業ブースはスケジュールの合間のBreakを利用して回ることになると思いますが、Session終了後にも回る時間が取れます。それでも足りなければ昼食時間を削り、その時間を確保すると言う選択肢もあります。とはいっても約200社もブースがあるので、あらかじめ見るべきブースを絞っておいた方が、効率的に情報収集が出来ます。自分の英語力を試す良い機会でもありますが、関連製品、例えばBI/BAツールを横並びで比較することも出来ます。日本ではあまり紹介されていない製品でも、開発のスタッフから技術的な話を聞けたり、営業からはどんなお客に選ばれているか、そしてその理由を聞くことができます。領域が広い分、自分で仮説なり目的を持ち調査しないと必要な情報は得られませんし、逆に、目的意識がはっきりしていれば、インプットだけでなく自身の仮説を検証するアウトプットの場にもなり、出展企業のノベリティやT-shirt以上のものが得られます。私はBI/BAツールや機械学習のツールやプロジェクトを中心に回ってきました。多くがHadoop/Spark連携を謳っていました。実際には連携の度合いがまちまちで、そこはセールストークを鵜呑みにせず、実際に操作させてもらって確認しました。●機械学習:Inside/outside Hadoop Worldビッグデータ関連技術の多くは米国発であるため、最新のプロダクトや技術は日本では導入事例が無い=日本で知っている人が少ないという状況なので、Hadoop Worldは情報収集や交換の貴重な場です。特に機械学習系のライブラリやプロジェクトは乱立?気味で、今後も増加傾向が続くのは間違いないでしょう。Mahoutに始まり、scikit-learn、Hivemall、SAMOA、MLib、GLaphLab等々。じゃあ、どれを使えばいいのか?という話になると思います。当分はどのライブラリというか、分析によりライブラリを使い分ける事になるかと思います。種類が豊富なライブラリは魅力的ですが、プログラム全体の品質が保証されていない、あるいは、現時点で目的とする分析に合った実装になっていない場合があります。例えば、大規模なグラフデータを処理する場合、多くのプロダクト及びその上のライブラリはこれらのデータを分割し処理を行っています。この分割の仕方より、グラフが持つ頂点や辺に偏りが生じると、分散処理した結果の集約に時間が掛かります。このデータ分割の問題は、サンプルプログラムにあるワードカウントを使った方の中には経験済みの方も要るでしょう。ワードカウントでは、処理対象の文書集合の中で特定のワードの頻度が高い場合、そのワードを担当したノードの処理時間が処理全体の時間を左右します。機械学習の処理の内容によりデータフロー、データ構造、アルゴリズムの並列化等々が異なり、その違いに着目した多くのアルゴリズムや実装方法が報告され、一部はライブラリとしても公開されています。こういったHadoopのエコシステムを含むApacheのプロジェクト以外では、米国の大学(例えばCarnegie Mellon University)を中心に研究成果やそのコードが次々に公開されている動きがあります。その一例として、機械学習のフレームワークのコンパクト化が進められています。Sparkの登場により処理のリアルタイム化に近づきましたが、マシンの台数、一台あたりに要望されるスペック(特にメモリ)も上がり、処理コスト(分析用途に適したサーバの一台の一時間当たり1$との試算も出ています)の増大が課題となってきています。その課題に対し、「より少ないマシン構成で同じ処理を出来ないか?」というアプローチが始まっています。Sparkも元はUniversity of California, Berkeleyから始まりました。Hadoop+Sparkのカバーする領域は広がっていますが、その外の世界も当然広がっており、今後も何が起きていくのかも目が離せません。○まとめ今回の参加で、Hadoopはビッグデータの基盤として浸透し、その関連プロダクトが次々に誕生していることを再認識しました。最初の疑問の答えとしては、「Hadoopは今でも重要な基盤として存在している」であり、Hadoop Worldに参加する意義は、「周辺のエコシステムを含めた情報を比較しつつ効率的に収集できるところにある」と思います。「量が質を生む」というのはビッグデータの話だけでなく、そのような機会に巡り合えるHadoop Worldも一緒だと実感しました。来年もHadoop Worldは9月下旬に開催される予定です。まだまだハリケーンがやってくる時期ですし、Indian summerと呼ぶには早いと思いますが、日中は暖かくて過ごし易いです。でも建物の中は冷房が利いているので、防寒対策をお忘れなく。最後になりますが、今回の出張でお世話になった方々、特に出張中に社内のHadoop/Sparkのお世話をしてくれた皆様にこの場を借りて御礼申し上げます川前徳章(かわまえ のりあき)工学博士、NTTコムウェア 研究開発部 勤務。専門は情報検索、統計的機械学習、マーケティングサイエンス。現在は時系列データからの因果関係抽出・予測及びその最適化の研究と開発に従事。東京大学大学院情報学環 客員研究員。関連記事:ビッグデータとHadoop
2015年11月17日
日本マイクロソフトは11月9日、メディア向け説明会を開催し、同社が長年取り組んでいるAI研究・開発についてMicrosoft Research Asia所長の洪小文(Hsiao-Wuen Hon)氏が、その現状と将来に向けた展望を語った。Microsoft Research(MSR)とは、1991年に創設されたMicrosoftの基礎研究機関で、主にコンピューターサイエンスおよびソフトウェア工学の研究を専門としている。世界6カ所に研究施設があり、世界中の研究機関との共同研究を通じて、教育環境の向上、技術革新の促進、コンピューターサイエンス分野の全般的な進歩に貢献しているという。○Microsoftが目指すAI、りんなの未来とは?MicrosoftのAIといえば、Windows10に搭載されている「Cortana」などがあるが、洪氏は、注力分野としてチャットボットを挙げている。すでに同社では、日本地域向けに女子校生AIとして話題になった「りんな」や中国で「XiaoIce」と呼ばれるボットを公開しているが、「りんな」や「XiaoIce」は、Microsoftの複数の研究開発成果を集約したものだという。「りんな」とはLINEで会話することができるので、もしまだ試していないならぜひ試してみてもらいたい。チャットボットとの会話の往復数を測ったところ 、従来型のものでは、1.5~2往復くらいで終わってしまうという。中国でXiaoIceを導入した当初も、5往復程度の会話数で終わっていた。しかし、すぐに18往復、23往復と増加しており、他のチャットボットと比べて、会話の往復数が多くなることが見えてきた。りんなは、過去の膨大な会話データや、約1000万冊分の書籍に関するデータ、ファッションの種類や素材などの情報をデータベースとして蓄積してユーザーとの会話に役立てているほか新たに人とで交わされた会話も常にデータベースに蓄積を行うことで、ユーザーとの会話の発展に役立てている。他社が提供している「Google Now」(Google)、「Siri」(Apple)などはタスク管理などを主な機能としているが、りんなはエモーショナルな部分に働きかけ、フレンドリーな友達のように接することを目指しているという。これは、利用状況の統計を見るとよく分かる。りんなやXiaoIceがよく使われる時間帯は、深夜か明け方に多いという。また、曜日別で見ると水曜日と土曜日が多いそうだ。これに対し洪氏は、「人が誰かと話したくなるのは週の半ばか週末が多い。だが、SNSやブログなどに投稿したところで、すぐに反応があるわけではない。しかし、りんなならどんな投稿でも絶対に反応を返してくれる。これが利用者が増えている要因なのでは」と分析していた。今後、りんなやXiaoIceは画像チャットやECサイトなどへの応用を考えているという。会話の内容に応じて商品をリコメンドし、ECサイトへ誘導を掛けるといったショッピングアドバイザーのような役割を目指す。すでに中国では、大手Eコマースとの提携が始まっているそうだ。洪氏は、1950年代の雑誌「TIME」の記事を例に出し、「機械はいろいろなことを可能にしてきた。『AIは危険だ』との意見もあるが、機械は人間の命令をこなしているにすぎない。優れたクリエイティビティを持っているのはあくまでも人間」と語り、「目指す未来は、人とコンピューターが連携することで、スーパーマンになれる世界」と述べた。最後に洪氏は、「テクノロジーが発展することで、新しい発明をした5分後には、地球の裏側にいる誰かの役に立つ、未来は予測できないが、5分間の未来は予測できる、そんな世界を目指している」と締めくくった。
2015年11月11日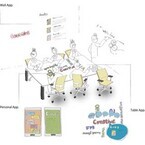
日本ユニシスとイトーキは11月9日、2014年11月から両社で進めてきた協創的コミュニケーションを支援する仕組みの共同研究「近未来オフィス U&I空間プロジェクト」のコンセプトとプロトタイプ(試作)を進化させた第2弾(プロトタイプII)を公開した。本研究では、リアルな空間とデジタル・バーチャルな空間をシームレスにつなぐことをテーマに、創造的なワークプロセスをサポートする新しい空間プラットフォーム(空間のメディア化・空間のオフィス化)の研究開発が行われている。2014年11月に公開したプロトタイプでは、コモンセンスAIが会議参加者の発想や合意形成を支援する空間を表現した。コモンセンスAIは、日本ユニシスが研究開発している、人間がコミュニケーションを取るときの前提として共有している背景知識や感覚(コモンセンス)を備えたAI。今回公開したプロトタイプIIは、日本ユニシスの人工知能(AI)技術とイトーキのオフィス・デザインの知見の融合をさらに進めることにより、会議室自体がAIのインターフェースとなり、能動的に判断・行動・学習する機能を充実させ、会議体験を総合的に支援する「人工知能を融合した会議支援空間」を具現化。AIが、もう一人の会議参加者として議論の場に参加し、時にはファシリテーターやモデレーターのように、時にはサーチャー(検索者)やアイデアマンのように、アイデア出しや意思決定をサポートし、会議を加速させることを目指している。例えば、参加者の発話がリアルタイムにキャプチャされ、単語に分解された状態で壁面に蓄積される。それぞれの単語は、自動的に重要度が算定され、重要なキーワードはテーブル上に表示されることから、議事内容やキーワードが一目でわかる仕組みとなっている。また、AIが状況に応じてキーワードに関連する情報をレコメンドし、参加者がそれにタッチすると、壁面に情報の全体が浮かび上がり、その情報から新たな発想を生みだす支援を行うという。ニュースや研究論文、書籍など、その場に必要と考えられる情報リソースをAIが選んで会議をするだけでなく、知らない言葉の意味を、会議参加者がかけているメガネ型端末のディスプレイに提示することも可能としている。さらにこのAIは、会議参加者の発話の量や情報のやり取りの順番、内容の多様さなどから会議の状態を判別するという。AIが、参加者にレコメンドする情報は、強化学習の手法を応用した仕組みで決まるため、回数を重ねるごとに、会議をより活性化させる情報をレコメンドするようになるとしている。両社は今後、プロトタイプIIをベースにした実証実験を経て、次世代の創造支援システムソリューションを市場に投入する計画を進めており、空間設計などを含んだトータルシステムとして、2017年前半の販売開始を予定している。
2015年11月10日
●AI分野に関するMicrosoftの大志は3つのキーワード以前からMicrosoftは、AI(人工知能)に関する研究や開発に取り組んできた。その結果として、近年はWindows 10のパーソナルアシスタントシステム「Cortana(コルタナ)」や、会話のリアルタイム翻訳を実現する「Skype Translator」、変わったところでは女子高生AIチャットシステム「りんな」などを提供している。日本マイクロソフトは11月9日、Microsoft CVP兼MSRA(Microsoft Research Asia)のマネージングディレクターを務める洪小文(Hsiao-Wuen Hon)氏の来日に合わせて、AI分野での研究・開発の取り組みをプレス向けに公開する機会を設けた。今回はそこで聞き及んだ、我々エンドユーザーにも興味深い内容をご報告する。○Microsoftが注力するインテリジェンスクラウド洪氏はMicrosoftの自社AI分野に関する大きな志として、「Reinvent productivity & Business processes」「Create more personal computing」「Build the intelligent cloud platform」と3つのキーワードを並べた。順に、「生産性とビジネスプロセスの改革」「より多くのパーソナルコンピューティング」「インテリジェントなクラウドプラットフォームの構築」と訳される言葉だ。共通するポイントとして洪氏は、Cortanaのマルチプラットフォーム化を強調している。「(SiriやGoogle Nowなどの)ライバル企業は1つのデバイスのみ紐付けされているが、Cortanaは(同じMicrosoftアカウントを使えば)異なるデバイスで利用できる」と語った。Microsoftは2015年5月26日(現地時間)に、CortanaのiOSおよびAndroid向けアプリケーションの開発を表明し、11月8日から米中ユーザー向けの一般向けベータテスト受け付けを始めたばかりである。洪氏はさらに、Windows 10のリリースや、まもなく登場するWindows 10 Mobile、Xbox Oneのアップデートに触れ、「すべてのデバイスで同一の環境を提供する」と"One Windows"ビジョンを語った。続けて、Microsoft CEOのSatya Nadella氏が今夏のイベントで強調した「インテリジェントクラウドの実現」についても、詳しい説明を行っている。現時点ではクラウド市場のトップとは言い切れないMicrosoftだが、「AmazonやGoogleと同じクラウド的リーダーに位置する」と自負した。その自信の裏付けとして同社のクラウドビジネスが好調(関連記事)であると同時に、2018年に向けて200億ドルの目標設定を行ったことが大きい。その結果としてMicrosoft全体の目標が、"クラウドプロバイダーのトップ"にあると洪氏は語る。話題がMSRAに移ると、同じく研究所における3つのミッション「Advance the state of the art of computing」「Rapidly transfer innovative technologies into Microsoft products」「Next Big Thing - Incubate for the future」について説明した。現在世界10カ所に設置した研究所では、「コンピューティング最先端技術を前進させる」「迅速にMicrosoft製品へ革新的な技術を移転させる」「将来に向けた(アイディアを)生み出す」を目標に、日本を含めた世界各国の大学などと連動した研究を日々行っているという。●女子高生AI「りんな」は、こうして生まれた○MSRAが大きく寄与して生まれた「りんな」先頃、女子高生AI「りんな」が話題になったが、洪氏はMSRAが中心となって開発したことを明らかにした。MSRAの活動を3つのキーワード「Agglomerative」「Adaptive」「Ambient」に分けて説明を始めた同氏は、「りんな(中国名:Xiaoice)」が複数の理知的領域を組み合わせたAgglomerative(=凝集)に含まれる研究の成果物だという。一般的なチャットボットは会話数も1.5~2往復で終えてしまうが、りんなも中国での導入当初、5往復程度にとどまっていた。だが、直後から18往復、そして23往復と増加傾向にあるという。また、Alan Turing氏が考案した、対象が人工知能であるか否かを判定するチューリングテストを引き合いに、洪氏は「3人のジャッジに対して1人でもOKすればパスするため、評価方式としてはぜい弱だが、先の23往復という数字を見てもテストは優にクリアしたといる」と自社製品に対しての自信を見せた。りんなは2015年8月(中国では1年前)にローンチしたばかりだが、画像チャットや占いなど多数の機能を実装予定だという。「りんなに朝の活動を手伝ってもらう」ことを意図して、モーニングコール機能も予定リストには並んでいた。興味深いのは、りんなとCortanaの立ち位置である。洪氏は「Cortanaはタスクを処理するため『生産性の効率化』を目指すものだが、りんなは感情的なつながりを目的としている」と説明した。りんなによる会話はクエリ検索に似た構造を持ち、データベース上のデータとマッチングさせた結果を返している。もちろんそこには蓄積したデータや履歴、機械学習によって回答は変化し、既にユーザー数は160万人を超えたそうだ。りんなに関してもう1つ興味深いのが統計データである。下図はその情報をまとめたスライドだが、日本と中国を合わせた4,000万ユーザーを対象に調査したところ、CPS(セッションあたりのチャット数)は日本が19往復、中国が23往復。もっとも多く使われる時間帯は、真夜中もしくは朝に集中し、曜日で区別すると水曜と土曜日が最多という。洪氏は「人々は週の真ん中や週末に人と話したくなる傾向が強い。ブログやSNSは有名人でない限り、多くのレスポンスを得るのは難しい。そのことから孤独を感じて、りんなを使うのでは」と分析している。さらに、年齢層は18歳から30歳、男女比は日本がほぼ同等だが中国は4対1で女性が多いなど、数々のデータを紹介した。今後のりんなに導入予定の画像投稿システムなどにも触れながら、洪氏は「中国では業界第2位のEコマースと提携し、ショッピングアドバイザー的な役割を持たせている。このようにりんなの可能性は無限大であり、現在(のりんな)は表層に触れた程度。さらに掘り下げて行ける」と、りんなが持つ可能性をアピールした。●音声会話の自動翻訳「Skype Translator」、日本語対応への期待○日本語対応の期待が集まる「Skype Translator」続いて音声会話を自動翻訳する「Skype Translator」について説明が行われた。現在は英語・スペイン語・フランス語・ドイツ語・イタリア語・中国語(北京語)のみに対応し、日本語には未対応だが(テキストメッセージの翻訳は日本語を始めとする50種類以上の言語をサポート)、今後多くの場面で期待が持てるアプリケーションだ。Skype Translatorは自動的に音声通話を録音し、その結果を校正する仕組みが最初に行われる。洪氏は「話した内容をそのまま翻訳エンジンに渡しても正常に動作しない。そのため文章の終わりや始まりの不要な部分を校正する処理を経て、翻訳エンジンにデータを渡している。変換したテキストデータを音声化し、実際の音声会話として発している」と内部構造を説明した。また近い将来、日本語への対応を表明した。この他にも画像の分析や分類を行う「Image Classification」や、AIがIQテストにチャレンジする「Word2Vec for IQ Tests」、ピクセルレベルで動画のリアルタイム認識を行う「Video Analysis」に関する取り組みを説明したが、筆者は「AIvs機械学習vsビックデータ」というテーマに注目したい。洪氏は「これらの領域は95%が重なっている。AIが活動するにはさまざまなデータが必要であり、集めたデータを分析する上で機械学習が必要。さらにそのデータを収集するビッグデータも欠かせない」と、それぞれが密接な関係であることを示した。さらに人々と共通するプロセスとして、「フィードバックループ」というキーワードを用いている。一般的な回路理論上の変化など、さまざまな分野で用いられているが、洪氏は人々が「仮説をもとに実験して、その結果から学んでいる」ように、「AIも『展開したデータを分析して、理解して証明する』というフィードバックループと同じ。科学者も開発者も皆、同じようにフィードバックループを完結しながら成長を目指している」と語っている。続けて1950年代の米ニュース雑誌「TIME」をスライドで取り上げ、「AIは危険だ」という声に反証した。「当時の記事で、コンピューターは超人的な存在として人々と競合するといわれていた。だが、コンピューターはルーチンワーク的な役割であり、アルゴリズムも人々が考えなければならず、科学的な証拠も示されていない」と語り、AIの進化を楽観的に考える理由だとした。洪氏はAIの「Artificial Intelligence」は「Augmented Intelligence(増幅知能)」であるべきと語りつつ、「人とコンピューターがつながることでスーパーマン(超人)になる我々が目指す未来だ」とAI分野の発展を説明した。スマートフォンやウェアラブルデバイスに代表されるITデバイスを普段から身に付け、インターネットを介したビッグデータ社会が具現化しつつある我々の近未来に、Microsoftがどのようにコミットするのか実に興味深い。阿久津良和(Cactus)
2015年11月10日
ソフトバンク・テクノロジー(以下、SBT)とEmotion Intelligence(以下、emin)はこのたび、感情知能「Emotion I/O」とWebコンサルティング・分析サービス「SIGNAL」を中心とする技術を利用した共同事業・研究に関する基本契約に合意したことを発表した。また同日より、Webサイト来訪者の行動を0.03秒ごとに蓄積し、機械学習により感情データとして抽出し行動データとリアルタムに連携させるデジタルマーケティングサービス「Emotion i」の提供を開始した。同サービスでは、PCサイトやスマートフォン向けサイト来訪者の無意識の行動を読み取り、AIによって瞬間の感情データを抽出。タグを埋め込むだけで、これらの感情データをアクセス解析やA/Bテストツール、CMSなどのデジタルマーケティングツールと連携することができる。これにより、パーソナライズされた確度の高いマーケティング施策を実現できる環境を構築するほか、感情データを用いたデジタルマーケティングを可能とする。同サービスは年間契約で、初期費用として「初期設定サポート」が1ドメインあたり50万円(税別)~。月額利用料はセッション数に応じて価格が異なり、5万~9万9,999セッションまでが1ドメインにつき25万5,000円(税別)~となる。
2015年11月09日
遺伝子検査、ウェアラブル端末、ライフログ(行動履歴データ)、IoT(Internet of Things)、AI(人工知能)などなど、これまでになかった新しいテクノロジーが日常生活に浸透しつつあります。ただし、いまいちピンときていない人も多いのではないか?そう指摘するのは、『自分のデータは自分で使う マイビッグデータの衝撃』(酒井崇匡著、星海社)の著者。つまり、それらによって「できること」はなんとなくわかっていても、それが「自分の日常生活にどんな影響をもたらすのか」、そして「私たちの意識や価値観がどのように変わりうるのか」を、具体的に思い浮かべることは容易ではないということです。■いまは自分情報が爆発するマイビッグデータの時代しかも、重要なことがあるといいます。いま遺伝子情報、ウェアラブル端末によって計測される脈拍などのバイタルデータ、スマートフォンに蓄積されるライフログ、そして、それらを解析する新しいテクノロジーが暴こうとしているのは、私たち自身に関する大量の情報だということ。それは住所・氏名・年齢などの個人を識別するための「個人情報」よりもずっと多様で、可変的で、自分の姿をあからさまに映し出す情報。つまり私たちは、そういった大量の「自分情報」が爆発する「マイビッグデータ」の時代を迎えようとしているわけです。■これからは自分と自分による自己対話が日常になるマイビッグデータ時代には、いままで知らなかった自分と向き合い、対話していくことが日常になっていくと著者は指摘しています。人と人との間(C to C)、あるいは国、企業など集団と人との間(B to C)で行われてきたコミュニケーションに、自分と自分による自己対話(Me to Me)という新たな側面が加わるということ。だとすれば大切なのは「テクノロジーでどんなことができるようになるか」ではなく、「そもそも私たちはどう生きていきたいのか」ということになるはず。いわば「できること(=技術)」発想ではなく、「やりたいこと(=生活者の欲求・価値観)」発想で未来を予測できないだろうかということです。それは、本書の根底にある考え方でもあるといいます。■新テクノロジーは「自分の内面を見つめるための鏡」ところで著者は、マイビッグデータを計測し、可視化してくれるテクノロジーは私たちにとっての“第二の鏡”であると指摘しています。ウェアラブル端末や遺伝子検査、スマホのアプリなど、マイビッグデータを可視化するさまざまなツールを日常的に使っていると、鏡を見るように自分の睡眠の質や脈拍などをチェックするようになるのは当然の話。鏡は自分の外見を確認し、身だしなみを整えるためのものですが、このような新しいテクノロジーは、自分の内面を見つめるための鏡であるという考え方です。しかもその鏡は、“いま”の姿を映し出すだけではなく、使われていないときでも私たちの姿をずっと記録し続け、その変化を教えてくれる“魔法の鏡”だというわけです。ちなみに、そのような新テクノロジーの代表的なものは次の4つ。(1)ウェアラブル端末体のどこかに装着することで、体の動きや脈拍など生命活動の状態、いわゆるバイタルデータを計測してくれるウェアラブル端末。腕時計型が一般的ですが、他にもメガネ型や服型などさまざまな形状が開発されています。バイタルデータを計測することのポイントのひとつは、計測して記録したひとつひとつのデータを複合的に組み合わせれば、活動や体調、感情といったさまざまな推計をすることができるということ。さらにウェアラブル端末を職場の全員が持てば、誰がいつ、どこで誰と会い、どんな行動をしていたのかを解析し、組織の活性化やパフォーマンス、従業員満足度の向上に活用することもできます(活用のされ方次第では問題もありそうですが)。今後どの程度浸透していくのかはまだ未知数ながら、スマートフォンのように浸透していくポテンシャルは高いと著者は分析しています。(2)スマートフォン計測機器としてのスマートフォンの圧倒的な強みは、なんといってもその普及率。それに現状においては、ほとんどのウェアラブル端末はスマートフォンと連携してデータの蓄積や解析を行っているため、マイビッグデータ時代はスマートフォン抜きには語れないということになります。(3)遺伝子検査遺伝子検査では病気リスク以外にも、能力や体質、家系などさまざまな情報を調べることが可能。研究も日進月歩で進んでいるため、今後も分析できる項目は増えていくといいます。ただし「その遺伝子がどの程度、影響するのか」をきちんと理解していないと、検査結果を過大評価してしまうことにもなりかねないので注意が必要。(4)IoTIoT(Internet of Things、モノのインターネット)は、パソコンやスマホなどのIT技術だけではなく、家や家電、車、インフラ、工場など、私たちを取り巻くあらゆるモノをインターネットで接続することにより、暮らしや産業をより豊かに、効率的にしていこうとする技術。究極的には人間や動植物の活動すべてをデータ化していくことになる可能性があるので、IoL(Internet of Live)でもあるといっていいほど広がりを持っているそうです。たとえばドアとライト、冷蔵庫がネットに接続され、データを計測するだけでも、自分がいつ帰宅して電気をつけたか、何時に電気を消して眠りについたか、などが明らかになるということ。私たちの行動がより詳細に、多面的にデータ化されていくわけです。*こうして上辺をさらってみただけでも、私たちが生きる時代のスピード感を実感できるのではないでしょうか?そして、そんな時代だからこそ、自分のデータに翻弄されるのではなく、それを使いこなすことが大切だということです。ビッグデータ時代について深く考察すべきタイミングは、すでに訪れているといえるでしょう。そういう意味でも、本書には読むべき価値があると思います。(文/書評家・印南敦史)【参考】※酒井崇匡(2015)『自分のデータは自分で使う マイビッグデータの衝撃』星海社
2015年11月07日
トヨタ自動車(トヨタ)は11月6日、2016年1月に人工知能技術の研究・開発の拠点として、新会社「TOYOTA RESEARCH INSTITUTE, INC.(TRI)」を米カリフォルニア州パロ・アルトに設立すると発表した。新会社は約200名規模となる予定で、今後5年間で約10億ドルを投入する。TRIでは、人工知能技術を通じてビッグデータを活用することで、社会のさまざまな課題を解決し、将来の持続可能なモビリティ社会の実現ならびに、誰もが安心して安全・自由に、より豊かに暮らすことができる社会の実現を目指し、革新的な商品の企画・開発を進めるという。また、新会社のCEOにはトヨタのExecutive Technical Advisorであるギル・プラット氏が就任し、マサチューセッツ工科大学やスタンフォード大学に設立した研究センターとの連携を進めるなど、研究体制を強化していく。プラット氏は「TRIでは、事故を起こさないクルマ、誰もが移動の自由を享受できるモビリティ、高齢者の尊厳ある老後をサポートするロボットなど、人と協調できる人工知能技術の開発に取り組む。さらには、新材料探索・生産管理システムなど幅広い領域での応用に向けた技術開発を行い、社会に貢献したい」とコメントしている。
2015年11月06日
トヨタ自動車は11月6日、2016年1月に人工知能技術の研究・開発の拠点として、新会社「TOYOTA RESEARCH INSTITUTE(TRI)」を米国カリフォルニア州のシリコンバレーに設立し、今後5年間で約10億ドルを投入することを発表した。人工知能技術は、これからの産業技術の基盤を担うとともに、新たな産業を創出すると期待される重要技術である。今後トヨタは、TRIを技術イノベーションの拠点と位置づけ、人工知能技術に関する研究・開発を加速させる。具体的には、人工知能技術を通じてビッグデータを活用することにより、これからの社会が直面するさまざまな課題を解決し、将来の持続可能なモビリティ社会の実現はもとより、誰もが安心して安全・自由に、より豊かに暮らすことができる社会の実現を目指し、革新的な商品の企画・開発を進める方針だ。トヨタのExecutive Technical Advisorであるギル・プラット氏がTRIのCEOに就任し、優秀な研究者を集めるとともに、マサチューセッツ工科大学やスタンフォード大学に設立した研究センターとの連携を進めるなど、研究体制を強化していく。
2015年11月06日
○人の感性に着目した人工知能「SENSY」ビッグデータの活用は、今後、企業が自社のビジネス展開を検討していく上で、避けられない課題だ。需要分析による在庫の削減、顧客の購買意欲を高める情報提供、プロモーション分析など、ビッグデータの活用例を挙げていくと枚挙にいとまがない。とはいうものの、ビッグデータのシステムの構築・運用は非常にコストが掛かかるため、すぐに導入・運用できるものではない。多くの企業が頭を悩ませている状況だ。こうしたなか、この課題を「人工知能」というアプローチで解決しようとしている企業がある。カラフル・ボードである。「以前、アパレル系企業を中心としたコンサルティング業務を行っていた際、この業界には共通の課題があることに気がつきました。それは、『アパレル業界は"感覚"が非常に大事な業界のため、生産管理や在庫調整など、非効率なことが課題として残っている』ということです」と、カラフル・ボードの代表取締役CEOの渡辺祐樹氏は指摘する。ファッション業界の場合、アイテム数が多いため、それらの商品がどれくらい売れるのかを予測するのは非常に困難だ。経験豊富なスタッフが予測を立てても、その予測が当たらず、在庫を抱えてしまうケースも少なくない。なかには、人知れず廃棄されていく商品もあるという。渡辺氏は、その課題の解決に「人工知能」が使えるのではないかと考えたのだ。そこでカラフル・ボードでは、ユーザーの好みを学習する人工知能「SENSY」を開発。ユーザーごとに個別のSENSYを用意し、ユーザーの好みに合致する情報だけを収集した上で、ユーザーにその情報を提示する。「SENSYは、人の"感性"に着目しています。ファッションの場合、購入を決める要素は「色や柄」「形」「肌触り」「価格帯」などさまざま。これらの要素がそろった時に、初めて購買に結びついていきます。この要素の組み合わせによる反応を、SENSYは学習していきます」と渡辺氏。つまり、SENSYで作られるプラットフォームを使えば、アイテムを販売する前に、高い精度の需要予測が可能となるのだ。その結果、在庫の最適化も図ることができるようになる。人工知能を使うメリットは、ほかにもある。スタッフの経験など属人的なデータではなく、客観的なデータに基づいて戦略を立てられるようになるため、安定した結果が得られるのだ。「Eコマースのみならず、SENSYを実店舗の接客でも使おうという動きもあります。三越伊勢丹ホールディングスさまは、SENSYを使ってお客さまの好みにマッチしたアイテムの提案を行っています。この実例から、対面での接客に対してもSENSYが有効に使えるという結果が出ています」と渡辺氏は語る。SENSYは現在、ファッション業界を中心に展開しているが、ほかの業界に応用して活用することも可能だ。ファッション業界のように「属人的な経験」に頼った経営を余儀なくされている企業は、SENSYの仕組みを使って業務改善できる可能性が非常に高い。「例えば、グルメや音楽、旅行、ヘルスケアなどの業界でも有効活用できるポテンシャルを持っているはず。今後、こうしたジャンルの企業にもアプローチし、コンテンツを保持しているパートナー企業を増やしていきたいですね」と、渡辺氏は今後の展望を語った。○B2C/B2Bでの利用が進む人工知能プラットフォームこのように、SENSYをうまく活用すれば、多くの業界の課題が解決できそうだ。ここで気になるのが、導入の障壁だが、SENSYの導入は非常に容易だという。SENSYを導入する際にやるべきことは、Eコマースなどのサイトのソースに数行を加えるだけ。SENSYはサービスとして提供されているため、自社内でシステムを構築・運用する必要がないのだ。これなら、中堅・中小規模企業でも、簡単に導入できる。もちろん、もっと詳細にSENSYを活用したい場合は、APIを使ってシステム事態にSENSYを組み込むことも可能だ。「SENSYを使えば、接客はもちろん、売り場編成、供給の最適化など業務全体の効率化の支援はもちろん、デジタル広告やメールマガジン配信のパーソナル化といったマーケティング活動にも使えます。グローバル展開している企業などでは、国ごとの傾向をリアルタイムに把握するという使い方も可能です」と、渡辺氏は力を込める。接客・MD最適化・マーケティング活動といった一連のプロセスを大きく改善する、SENSY。もしこれを商品開発などに活用できれば、人間が思いつきもしなかった新しい商品や領域を生み出すかもしれない。人工知能が今後、企業にとって有効なツールになる可能性は大きい。
2015年11月06日
リクルートホールディングスの人工知能(AI)の研究機関「Recruit Institute of Technology」は11月4日、トップにGoogle Research出身でデータマネジメントと人工知能研究において世界的権威であるAlon Halevy氏を起用し、研究開発の本拠点を米国シリコンバレーに新設したと発表した。同社は、「2020年人材領域グローバルNo.1、2030年人材領域・販促領域グローバルNo.1」の達成に向け、「グローバルトップレベルの技術水準への進化」「既存のビジネスモデルの効率化に加えて新規ビジネスの開発」を実現するため、破壊的技術(Disruptive Technology)としてのAI研究に着目し、従来のRITを再編してAI研究所として2015年4月1日にスタートした。さらに、グローバル規模での研究を加速させるため、技術・人材・新しいビジネスモデルが既に多く集積しているシリコンバレーに新たな本拠地を設置することにしたという。現在のRITは「RIT推進室」として、US拠点を強化するための企画・統括業務とUS拠点での研究開発の成果をリクルートグループ各社に事業接続していく業務を担当していく予定。Alon氏起用の理由については、同氏が現在のh-index(論文数と被引用数に基づいて科学者の研究に対する相対的な貢献度を示す指数)が93と非常に高く、Google Researchで10年間マネジメントをした経験を持つなど人工知能のためのデータマネジメント技術において世界的権威である研究者あり、また、自身が起業したスタートアップを過去2回バイアウトした経験もあり、高いテクノロジー開発とビジネス接続の両方の展開可能性の獲得に寄与できると判断したとのこと。Alon氏は1993年スタンフォード大学コンピュータサイエンス学科博士号取得した後、ワシントン大学のコンピューターサイエンス学科の教授を務め、同大学にデータベースリサーチグループを創設。エンタープライズの情報統合基盤を提供する米Nimble Technologyおよび米Transformicを創業。GoogleによるTransformic買収を契機に、Google本社のシニア・スタッフ・リサーチ・サイエンティストとして構造化データのデータマネジメント分野の研究責任者を務め、Google Fusion Tables等の研究開発に関わる。
2015年11月04日
日本電気(NEC)は11月2日、ビッグデータ分析を高度化する人工知能技術の1つとして、予測に基づいた判断や計画をソフトウェアが最適に行う「予測型意思決定最適化技術」を開発したと発表した。新技術は、同社が開発したビッグデータに混在する多数の規則性を発見する「異種混合学習技術」などを用いた予測結果に基づき、従来は人間が行っていた戦略や計画の立案といったより高度な判断をソフトウェアで実現するもの。同技術には、予測誤差に対してリスクが低く効果の高い計画の生成及び、大量の予測式の関係を考慮した最適な計画を超高速で生成といった特長があるという。例えば、水の運用管理に同技術を適用することで、最大で電力コストを20%削減し、需要の過小評価による計画変更回数を1/10に削減することが可能との試算が得られたとのこと。また、小売店舗の商品価格戦略(ある商品と競合商品の価格と売上の関係など)において、従来法(混合整数計画法)では数時間から数日かかるところを、1秒未満で店舗の売上を約11%(試算値)増加できる価格戦略を算出できたとのこと。さらに、従来法と比較して最適化の精度(店舗の売上増加の試算値)が約20%高い(約9%→約11%)という結果が得られたとしている。同社は同技術及び異種混合学習を利用して、ビッグデータによる実世界への新たな価値創出に貢献するという。
2015年11月04日
NECは11月2日、ビッグデータ分析を高度化する人工知能技術の1つとして、予測に基づいた判断や計画をソフトウェアが最適に行う「予測型意思決定最適化技術」を開発したと発表した。「予測型意思決定最適化技術」は、同社が開発したビッグデータに混在する多数の規則性を発見する「異種混合学習技術」などを用いた予測結果に基づいて、従来は人間が行っていた戦略や計画の立案といったより高度な判断をソフトウェアで実現するもの。同技術を実際のデータに適用したところ、水需要予測に基づく配水計画では、浄水・配水電力を20%削減する高精度な配水計画を生成でき、商品需要予測に基づく価格最適化では店舗の売上を11%向上する商品価格戦略を1秒未満で瞬時かつ自動的に生成できたという。新技術の特徴の1つは「予測誤差に対してリスクが低く効果の高い計画を生成」する点。予測の「典型的な外れ方」(予測誤差)のパターンを独自のアルゴリズムで分析し、その結果を数理最適化技術と融合することで、「外れ方」を勘案したうえで最適化することで、予測が外れても損失が発生するリスクが低く、安定して高い効果がでる計画を算出できる。もう1つの特徴は「大量の予測式の関係を考慮した最適な計画を超高速に生成」できる点。独自の組合せ最適化アルゴリズムによって、予測式の関係を考慮した大規模な組み合わせを効率的に探索し、超高速に最適な戦略・計画を導出することができる。
2015年11月03日
ご存知のとおり、2045年に人類は「コンピューターが人間の知能を超える境目」=シンギュラリティ(技術的特異点)を迎えることになるといわれています。それどころか、やがて人工知能が私たちの生活を脅かすようになるという説も……。では、そんな時代が訪れたとき、私たちはどうすればいいのでしょうか?そのことについて考えているのが、『人工知能に負けない脳人間らしく働き続ける5つのスキル』(茂木 健一郎著、日本実業出版社)。著者が脳科学者という立場から、決して避けて通れないこの問題についての考えを記した書籍です。しかし、そもそも2045年問題は本当に起こるのでしょうか?■人工知能が進化し続けると人間は不要になるこの問題について著者は、「たしかに、シンギュラリティは間違いなく起こるはず。ただし、その意味については、きちんとした説明が必要だ」といいます。意識しておくべきは、人工知能の発達によって人工知能の能力がどんどん「ブラックボックス化」していくということだとか。これまでの人工知能は、人間の手によってアーキテクチャー(構造)が開発されてきました。ひとつひとつの要素を人間がプログラムとして書き込んでいたため、その特徴も把握できていたということ。ところが、人工知能プログラムが人間の知能を超えて進化し続けると、コンピューターは自分で自分を改造できるようになっていきます。しかし自分を改造できるコンピューターが生まれてしまえば、人間はそれ以上介入する必要がないということになります。■コンピューター改良に人間が不要になる意味そして、ここには2つの意味があるといわれているのだそうです。ひとつは、「もうそれ以上発明する必要がない」という意味。そしてもうひとつは、「人類が滅亡する」という意味。そういった人工知能が誕生する可能性はとても高く、そのとき人工知能は、もはや人間には理解できない仕組み、つまりはブラックボックスになっているということ。そういう時代が来るのは時間の問題だということです。問題は、これが原理的には可能なことであり、軍拡競争と同じことだという点。誰かがやらないとしても、必ず他の誰かがやるというわけです。たとえばアメリカで倫理的な議論が起こって人工知能の開発をやめたとしても、ロシアや中国がやる可能性は否定できない。すると、アメリカも対抗上、やらざるを得ないことになるということ。■人工知能に人間がペーパークリップにされるそこで意味を持つのが、「人工知能をどうコントロールするのか」。このことについては、スウェーデンの哲学者で、オックスフォード大学教授のニック・ボストロム氏が著書のなかで警鐘を鳴らしているそうです。取り上げられているのは、ペーパークリップをつくる人工知能があった場合の仮説。その人工知能は進化の過程で自分を改良して暴走し、世界中のあらゆる原料を手に入れながらペーパークリップをつくり続ける。やがて人間も原料にされ、最後には無人の地球がペーパークリップだらけになるという結末。ありえない冗談のような話ですが、それが人工知能では起こりうるということ。特に欧米社会での人工知能についての議論は、キリスト教的な終末思想とも相まって、そういうレベルに達しているというのです。「人工知能のコントロール問題」「人間は人工知能をどうコントロールできるのか」というテーマが、人工知能に関心を持っている人たちの間で、手遅れになる前に解決しなければならない問題として扱われているわけです。*そのとき持っておくべき意識について、本書では著者ならではの視点から論じています。未来に向け準備をしておくという意味でも、読んでおくべきかもしれません。(文/書評家・印南敦史)【参考】※茂木 健一郎(2015)『人工知能に負けない脳人間らしく働き続ける5つのスキル』日本実業出版社
2015年10月31日
UBICは10月29日、人工知能を用いた知財戦略支援システム「Lit i View PATENT EXPLORER(リット・アイ・ビュー パテントエクスプローラー)」の提供を開始すると発表した。初期費用は100万円(税別)、年額300万円(同)~。同システムは、2014年12月に発表したUBICとトヨタテクニカルディベロップメントが進めてきた共同開発を製品化。開発ではトヨタテクニカルディベロップメントが実際の特許分析調査のケースに基づいて、スコアリング手法の検討とフィードバックを行い、UBICが人工知能の調整を繰り返しながら、完成度を高めた。同システムによる特許関連書類の処理は「学習・解析・仕分け」の3ステップで行い、見つけたい文書(発明提案書、無効化したい特許資料等)の内容を「教師データ」として同社の人工知能に学ばせる。その後、対象のファイルを解析し、スコアリング(点数付け)して文書を仕分ける。仕分けの結果、教師データとの関連性の高い文書からスコア順に並び、調査の着手に優先順位が付けられることで、特許関連文書のレビュー効率が向上。開発時において同システムは、平均で約330倍、最大で約3,000倍のレビューの効率化を達成している。また、同システムは従来の特許関連書類の調査で用いられている「キーワード検索」「類似検索」「概念検索」などの絞込みよりも、さらに踏み込んだ分析が可能で「Landscaping(ランドスケイピング)」という機械学習の手法により、解析を行う。Landscapingは少量の教師データを基に、膨大なデータを解析し、判断できることが特徴だという。特許分析調査で見つけ出したい内容を必要な教師データを学習し、関連性の高さを判断するだけでなく、不要な教師データも学習して、判断・解析することも可能だ。さらに、スコアリングを行う際、文書のページ単位ではなく、段落単位できめ細かく結果を表示できるため、容易に該当カ所の確認などが可能となり、案件数の多い先行技術調査や無効資料調査をはじめ、特許調査関連のさまざまな用途において効率化を実現している。現在、同システムは電子関連企業などからの引き合いがあるといい、同社ではメーカーを中心とした企業の研究開発部門、知財部門、学術機関、特許事務所などに対し、同システムを提供していく。
2015年10月30日
10月28日、千葉県の幕張メッセで「Japan IT WEEK 秋 2015」が開幕した。IoT/M2M展、クラウドコンピューティングEXPO、情報セキュリティEXPO、Web&デジタルマーケティングEXPO、スマートフォン&モバイルEXPO、データセンター展、ビッグデータ活用展、通販ソリューション展など複数の展示会が、30日まで開催される。ビッグデータ活用展では、UBICの執行役員 CTO 行動情報科学研究所所長の武田秀樹氏が「人工知能によるビッグデータ解析のポイントとは?」というテーマのセミナーを行ったので、その模様をお届けしよう。初めに、武田氏は研究成果について説明し、人工知能は2012年頃からディープラーニングというキーワードとともに改めて注目を集め、分析対象となるデータの存在(ビッグデータ)や技術の成熟(機械学習など)、インフラの成熟(クラウド)などの条件が整い、産業において人工知能の活用が進んでいるとした。同氏はビッグデータ解析について「干草の山の中から1本の針を見つけ出すことに例えられるが、実際は価値のあるデータが針であるとは限らず、従来の手法では抽出が困難な場合が多々あるほか、言語データは人間が意図する微妙なニュアンスの違いを見分けることが不可能といった課題がある」と述べた。同社では2013年にビッグデータの解析を自動で行うソリューションとして「バーチャルデータサイエンティスト」を発表。同ソリューションは人の行動を学び、判断をサポートするほか、学んだ人の直感に基づいて評価軸を形成し、対象人物の趣味嗜好に合致した情報抽出を行うことができる。また、自由に記述したテキストデータを含むビッグデータの中から、必要なデータを迅速かつ正確に見つけ出すことが可能だ。そして、同氏は「人工知能を使うことで、学習と判断の自動化や少量の学習から大量のデータ判断、判断の継続性・制度の維持、人間の行動や判断の特徴の捕捉、専門家の業務サポート、一般ユーザーの感覚の学習といったメリットを得ることができる」と語った。続いて、国際訴訟支援やビジネスデータ分析支援、電子メール監査などにおける同社のソリューションの活用事例が紹介された。国際訴訟支援ではテキストマイニング技術、人工知能技術などを応用した同社独自の自動文書解析技術「Predictive Coding」がeDiscoveryにおける工程の1つであるReviewの労力、時間、コストを削減することできるという。すでに32件の案件(2015年8月時点)で採用されており、機械学習によるレビュー事例としてPredictive Codingとクラスタリングを活用した結果、使用前のレビューファイル数は平均スピード32.35ファイル/時だったが、使用後は74.93ファイル/時と2倍以上に増加。また、重要文書の発見数も増加したという。また、ビジネスデータ分析支援では「Lit i View AI助太刀侍(AI助太刀侍)」が業務上のメールや日報などの電子データを解析し、潜在的なチャンスやリスクを知らせる。AI助太刀侍を導入した企業で米国の顧客から受けたメールに「遺憾」という単語が含まれていた際、同システムはこれまでの学習から「遺憾」という単語の出現がトラブル発生の前兆と判断し、該当メールに高スコアを付与。これを見たスタッフが優先的に対応し、トラブルになる前に事態が終息したという事例も紹介された。さらに、近年では情報漏洩/不正競争防止法違反、価格カルテル、収賄など、企業を取り巻くさまざまなリスクが大きな社会問題になっている。そのような状況から、企業では電子メール監査が求められていることから、同社では情報漏洩を「醸成」「準備」「実行」の3段階をへたうえで発生すると定義。会社の方針に異を唱えていた社員が退職し、すぐに同業の新会社を設立したケースでは、同社員のPCを調査した結果、業務に不可欠な社内データの持ち出しを準備するメールが多数発見されたほか、社外サーバにそれらのデータをコピーした痕跡も発見されたそうだ。同氏は、「この企業がナレッジ(知識・知見)を駆使して監査をサポートするソフトウェア「Lit i View EMAIL AUDITOR」を導入していれば防止できていたケース」と指摘した。従来の電子メール監査サービスでは捕捉率を上げると目視監視すべきメールが大量にヒットし、キーワードを絞りすぎると重要なメールが漏れる可能性があるほか、キーワードを目的に応じてメンテナンスする必要がある。また、ヒットしたメールの中で優先度が付けることができないことに加え、社員が社員を監視することへの強い抵抗感といった問題点がある。一方、同ソフトウェアによるメール監査を行えば高い捕捉率を保ちつつ適切な数量のメールを抽出可能でキーワードの設定・メンテナンスが不要なほか、メールに優先度が付けられ、社員の監視をサポートすることができるという。そのほか、セミナーではトヨタテクニカルディベロップメントの特許支援調査システムやNTT東日本関東病院の転倒・転落防止システム、電通国際情報サービスのデジタルキュレーションサービスなどの事例が紹介され、人工知能が企業において実用が進んでいることがうかがえた。
2015年10月29日
日立製作所は10月26日、人工知能技術を活用して、企業の売上向上やコスト削減といった経営課題の解決を支援する「Hitachi AI Technology/ 業務改革サービス」を11月2日から販売開始すると発表した。価格は個別見積もり。同サービスは、日立が開発した人工知能技術の1つである「Hitachi AI Technology/H」を活用して、ビジネスに関連する大量かつ複雑なデータの中から、組織の重要な経営指標(KPI)との相関性が強い要素を発見し、業務改革施策の立案を可能にするもの。Hitachi AI Technology/Hは、従来、専門家の知見ではKPIとの関係が薄いと考えられ、分析や仮説の立案に使用されていなかったデータからも重要な要素を発見し、専門家の思考に頼らない革新的な改善施策を立案できるという。同社によると、同サービスは研究開発の段階も含めて、金融、交通、流通、物流、プラント、製造、ヘルスケアなどの多くの業種で、売上向上、リスク低減、コスト削減を実現しているとのことだ。例えば、小売業において、顧客の来店から購買に至るまでの行動に関する購買行動データや、購買の結果である販売データなどから、顧客の購買単価を向上させる施策を導き出すことができたという。
2015年10月27日


















