
サイバーエージェントのアドテクノロジー分野におけるサービスの開発を行うアドテクスタジオは、2016年1月に設立した、人工知能をアドテクノロジーに活用するためのAI研究組織「AI Lab(エーアイ ラボ)」において、明治大学教授 高木友博氏と共同研究を開始したと発表した。「AI Lab」では、ダイナミッククリエイティブ広告を通じて、ユーザーひとりひとりが「自分ごと」として捉えることができる広告の開発を目指し、クリエイティブ最適化技術の研究を行ってきた。今回の共同研究は、ディスプレイ広告のさらなる進化を牽引すべく、最先端の広告配信技術を開発することを目的としている。今後は高木教授とともに、データマイニングや機械学習を用いて、ユーザー目線でキャッチーな広告クリエイティブを自動生成する技術の開発を図るという。また、企業が持つユーザー情報やユーザーの行動から類推される属性、趣味・嗜好に加え、ユーザーの過去の広告接触情報を加味した上で、最適な広告を配信するマッチング技術などの研究を行い、より精度の高い広告クリエイティブ最適化の実現を目指していくという。そして今回の共同研究は、アドテクスタジオが開発する、多様なデータを柔軟に組み合わせターゲティング配信するDSP「BitBlend(ビットブレンド)」やインフィード広告に特化したクリエイティブ分析ツール「iXam Creative Lab.(イグザムクリエイティブラボ)」など、多数のプロダクトへ活用していく予定だという。
2016年02月29日
日本マイクロソフトは2月22日、最近のホットワードでもある人工知能や機械学習をテーマにした自社の取り組みを発表した。Microsoftの研究開発機関であるMicrosoft ResearchでCVPを務めるPeter Lee氏は「機械学習は活版印刷技術の発明と同じ、破壊的な時代をもたらす」と述べている。今、世界が変化の兆しを見せていることにお気付きだろうか(変化の連続とも言えるが)。「機械学習(マシーンラーニング)」や「人工知能(AI)」という単語を、目に耳にしたことがあるはずだ。機械学習は、あるデータをもとに反復学習した結果からパターンを見つけ出し、学習結果に当てはめることで、将来予測などに用いることが可能と言われている。一方の人工知能は、コンピューターに人間と同じ知能を与えることで、周りから得た情報をもとに判断・行動を目指す。そこから得た成果は我々の社会構造を大きく変え、暮らし方や働き方も必然的に変化する。PCの世界に置き換えると、約30年前はDOS上でコマンドを実行するCUIが中心だったが、約20年前にはGUIが取って代わり、約10年前にはiPhoneが登場してタッチUIがスタンダード化。人とデバイスの関係性を覆した。この流れを見れば、約10年後の現実世界もおぼろげながらイメージできるだろう。その一端を読み取れるのが、今回、日本マイクロソフトが開催した「人工知能・機械学習の研究開発の最前線に関するラウンドテーブル」である。Microsoftからは、Peter Lee氏が出席。Microsoftのお膝元である米レドモンドのMicrosoft Research(MSR) Redmodや、おとなり中国のMSR Asiaなど世界の7カ所に拠点を持ち、多岐にわたる分野の研究を司るMSR CVPだ。ほか、東京大学 大学院新領域創成科学研究科 教授の杉山将氏、産業技術総合研究所 人工知能研究センター所長の辻井潤一氏なども加わった。産学官の枠を越えて、機械学習や人工知能における著名人が集まり、実社会や産業界への影響を議論。ここではLee氏の発言から、我々コンシューマーが携わる部分を紹介したい。Lee氏が最初に取り上げた製品は「Skype」だった。MSRの研究成果や機械学習から得たデータで実現する通訳・翻訳機能だが、2014年12月に英語とスペイン語の双方向翻訳に対応し、2015年5月にはイタリア語と中国語(北京語)をサポート。その後はフランス語、ドイツ語をサポートしてきたが、今なおプレビュー版と表現している。Skypeの通訳・翻訳機能が、今後も成長し続けることを示唆しているのだろう。また、当初のプレビュープログラムでは、関心のある言語に日本語が含まれていたが、この点について「2020年開催のオリンピックに向けて、2015年の春には日本語の同時通訳機能もサポートする予定だ。日本の企業と協力して、翻訳・通訳の品質向上にも努めたい」と回答した。Skypeの通訳・翻訳機能に関してMicrosoftは、2カ月に1回のペースで新しい言語にチャレンジし、執筆時点では50種類以上の言語翻訳を可能にしている。この点についてLee氏は、「かつてのモデルは国連のスピーチなど丁寧かつ形式的な会話をベースにしていたが、Skypeでは利用できないため最初から作り直した。その結果、一般的な会話や歌も認識できるようになった」とした。Windows 10 Insider Preview ビルド14267のCortana英語版には楽曲検索機能が組み込まれているが、同様の技術を用いているのだろう。まずはLee氏の発言に期待し、春以降の動向に注目したい。現在の機械学習状況ついてLee氏は、「人々が聞く・喋る・認識するといったアクションが実用化へ向かいつつある」と述べる。MSRは以前から多くの研究プロジェクトを立ち上げてきたが、Windows 10のCortanaがメールの内容を読み取って自動的にリマインダーを作成する機能、「Microsoft HoloLens」から見える仮想的なオブジェクト、指や手で操作する部分などが、MSRが機械学習の研究結果をフィードバックした一例だという。これらの成果は「Project Oxford」でAPIを公開し、ユーザーは誰でも顔や画像、音声認識を行うことが可能だ。画像から年齢を推察する「How-Old.net」や、先ごろローンチした画像内の犬種を識別する「Fetch!」も、同様の技術を用いている。後者のアプリケーションは人にも使えるため、Lee氏が「奥さんにはやらない方がいいかもしれない」と話すと、出席者から笑いが起こった。Lee氏は機械学習の現状を、Johannes Gutenbergによる活版印刷技術の発明になぞって、「破壊的な時代がもたらされた」と表現する。ただ、「現在のAIや機械学習は聞く・理解・視覚的に捉える・知覚するといった部分まで来ているが、理性やフィードバックループといった認知は進んでいない。例えば、数年後には大学受験は可能ながらも、一般常識や道徳などを重視する小学3年生のテストに合格するのは10年以上に先になる」という見方も示した。さて、Lee氏の職歴にカーネギーメロン大学のコンピューターサイエンス部門責任者とあるように、MSRのメンバーはすべて科学者だ。「MSRは(他社研究所と比べると)大型投資による人材収集、Amazonに匹敵するMicrosoft Azureの活用、Bingを介した世界中のWebデータへアクセス」(Lee氏)と、3つのユニークポイントを持つ。Microsoft社員の行動パターンデータも保持し、Webとエンタープライズのデータを活用できるのは強みとなるだろう。「今後も基礎研究や応用研究の結果をクラウドに反映させたい」と語るLee氏からは、AI&機械学習がもたらす近未来が目前に迫っていることを感じられた。阿久津良和(Cactus)
2016年02月23日
KDDI研究所は2月22日、ウインドリバーと日本ヒューレット・パッカード、ブロケード コミュニケーションズ システムズ(ブロケード)と共同でネットワーク仮想化時代に向けて人工知能を活用した自動運用システムを開発し、人工知能による故障予測に基づきネットワークを自動運用する実証に成功したと発表した。なお、同実証に成功したのは世界初だという。今回の実証では、ソフトウェアバグなどの異常の兆候を9割以上の精度で事前に検知し、従来の約5倍の速度で仮想化された機能を別拠点などの安全な場所へ移行することに成功している。具体的には、共通的なネットワーク仮想化基盤にハードウェアやソフトウェアの深刻な障害の兆候を検知する人工知能を埋め込み、効率的に学習、状況判断するとともに、予兆結果に基づいてSDN/NFVオーケストレータが最適な復旧プランを導出し、仮想化された機能を瞬時に移行させる自動運用システムの実証を行った。成果として設備警報などで検知可能な異常だけでなく、一旦発生すると深刻な事態を引き起こす恐れのある事象にも対応可能となり、ネットワーク仮想化時代の運用高度化の実現が期待されるという。以下は実証実験の概要ならびに技術的ポイント。共通仮想化基盤に分散的に埋め込まれた人工知能が汎用サーバや仮想化された機能など、ハードウェアとソフトウェアの両面で異常な兆候がないか、学習、検知する。この結果、そのまま放置すると深刻な事態につながる恐れのある兆候を捉える。なお、精度の高い学習と分析には膨大な統計量の処理が必要になるため、人工知能を分散させるというアプローチを取っている。上記で捉えた兆候などの情報を統合管理制御システムに集約し、その情報に基づきSDN/NFVオーケストレータは最適な復旧プランを導出。例えばソフトウェア異常(例:バグに起因するメモリ漏洩)を放置すると突然機能が停止する恐れがあるため、停止する前に代替機能でサービスを継続させる。また、ハードウェア異常(例:冷却ファン劣化によるサーバの放熱異常)の影響を考慮して、該当する仮想化された機能を別拠点などへ移行させる。上記の復旧プランに基づき、実際の復旧作業を自動的に進める中で、特にハードウエアなどの設備に起因した異常に対しては、影響を受けるサービスの範囲が大きくなる。その様な場合、該当する仮想化された機能の数も非常に大きくなり、それらをサービスに影響を与えずに移行させるかが課題となる。そこで、高速移行技術で影響を最小限に留めながらリスクを回避する。各社の役割としてKDDI研究所は人工知能による監視システム、SDN/NFVオーケストレータ、仮想化された機能、ウインドリバーはキャリアグレード仮想化基盤ソフトウェア、高速移行技術、日本ヒューレット・パッカードは仮想化された機能、ブロケードは仮想化された機能(Brocade vRouter製品)をそれぞれ担当。KDDI研究所は、ネットワーク仮想化への取り組みを通じて、IoT/M2Mなど多様化するサービスへの柔軟な対応と、より複雑化する運用の簡素化を図り、第5世代移動通信システム(5G)ネットワークの実現を目指す。また、NFV/SDN運用システム技術はTMForumやETSIなどの標準化団体を通じて、共通仮想化基盤における人工知能活用はOPNFVやOpenStackなどのオープン実装団体を通じて、ネットワーク仮想化によるインフラ基盤の高度化に貢献していくという。
2016年02月22日
IoT(Internet of Things)は人工知能と並ぶ今年のITトレンドの1つだ。IoTに関連した製品の展開、企業による導入も始まっている。ヴイエムウェアと言えば、仮想化製品のベンダーとしての印象が強いが、同社の製品はIoTソリューションの構築に活用されており、すでにさまざまな企業にIoTソリューションを導入しているという。今回、米VMware EMEA担当 戦略コンサルティング部門統括 マティアス・ショーラー氏より、同社のIoTへの取り組みについて話を聞いた。同氏は、中央ヨーロッパで自動車関連のビジネスを統括しており、コネクテッド・カーや自動車業界の新たなビジネスモデル全般に取り組んでいる。ショーラー氏は初めに、IoTソリューションについて、「接続」「管理」「モバイル通信」「インフラ」「セキュリティ」「アプリのライフサイクル」を組み合わせる必要があると説明した。同社が提供するIoTソリューションはこれらの要素を活用して、「モノの管理」「データのキャプチャと分析」「クラウドモバイルサービスの提供」を行う。「モノの管理」では、AirWatchでデバイスのアクセスと管理を、NSXでセキュアなコネクションを、vRealize OperationでIoTエッジゲートウェイの管理と監視を行う。ショーラー氏によると、インテルと提携しており、インテル製ゲートウェイにvRealize Operationのエージェントが搭載されているという。「データのキャプチャと分析」では、Pivotal Spring XDでデータ収集を、EMCのFederation Business Data Lakeでデータストレージを、Pivotal Big Data Suiteでデータの分析と対処を、EMC Real Time Intelligenceでエッジ分析を行う。IoTアプリの設計・開発・展開・運用を行うために、SDDCなどによりデータセンターのインフラを構築し、アプリ・プラットフォームを活用して、クラウドモバイルサービスの提供を実現する。このように、同社は「IoT向け」と銘打った製品ではなく、一般に企業向けとして提供している製品群によりIoTソリューションを提供している。ショーラー氏はIoTソリューションの導入事例として、Coca-Colaを紹介した。コカ・コーラは、1台で100種類以上の飲料を提供する自動販売機「コカ・コーラ フリースタイル」を提供しているが、裏ではAirWatch製品が動いているという。AirWatchはデバイス管理、構成管理、デバイス分析、SAPとSalesforceの連携を行っている。具体的には、飲料の利用データの収集、販売機のメンテナンスと飲料の補充管理などを行い、収集したデータの分析結果から、販売機によって飲料の種類を変更したり、個人のオーダーを管理したりすることで、購買客のニーズに応えている「Coca-Colaは米国でペプシにシェアを奪われていたが、フリースタイルの導入により、盛り返していると」ショーラー氏。Coca-ColaがAirwatchを選んだ理由としては、「拡張性、柔軟性が高いこと」が挙げられた。あわせて、ショーラー氏のメインの業務であるコネクテッド・カーに関する取り組みについても紹介された。IoTは製造業で導入が進んでいると言われており、製造業の中でも自動車業界は日本の経済を牽引しており、その取り組み状況は気になるところだ。ショーラー氏は、Pivotal製品を用いてアプリを開発したメルセデス・ベンツとフォードを紹介。メルセデスが2016年に発売を予定しているEクラスに搭載されるアプリ「メルセデス・ミー」は離れた場所からのドア施錠・解錠などのリモート操作を実現し、スマートフォンを鍵と利用することが可能になるという。「メルセデスはソフトウェア・カンパニーを目指している。そのスタンスの成功は、元はソフトウェアベンダーだったテスラモーターズが示した。EVはエンジンが見えないため、ハードウェア面で差別化の要素がない。そのため、ソフトウェアとサービスで工夫をしていく必要がある」と、ショーラー氏は自動車業界におけるソフトウェアの価値について語った。ショーラー氏はIoTソリューションを支えるデータセンターのインフラにおいては、ハードウェアでもソフトウェアでも構築可能な拡張性が特に重要だと述べたが、拡張性と並ぶ重要な要素が「セキュリティ」だという。例えば、ドイツの製造業では、製造システムが仮想化されるなど、IT化が進んでいるが、セキュリティの強化が課題となっているという。ドイツのある工場では、1台のマシンのUSBから工場全体にウイルス感染が広がったそうだ。「NSXのマイクロセグメンテーションでタイトな制御を行えば、ウイルス感染の被害を最小に食い止められる」と、ショーラー氏は語る。「ヴイエムウェアがIoT」と聞いた時は少々違和感があったが、考えてみれば、同社の戦略「One Cloud, Any Application, Any Device」はIoTと関わりが深い。規模が求められるIoTのインフラもソフトウェア定義のデータセンターなら容易に拡張可能だ。さらに広がることが予想されるIoT分野において、ブイエムウェアがこれからどのようにして存在感を放っていくのか、興味深い。
2016年02月22日
●「人生の相棒」のような存在を目指す"ドラえもん"のような人工知能(AI)を開発しているベンチャー企業がある。2013年10月に設立された「ネットスマイル」だ。設立者で代表取締役を務める齊藤福光氏に話を伺った。○そもそも"ドラえもんのようなAI"とは?"ドラえもん"のような人工知能。マンガやアニメのイメージから聞くだけで何となくワクワクしてしまうのだが、ドラえもんを人工知能として捉えた場合、具体的にどのようなものになるのだろうか。齋藤氏が目指しているのは"人生が楽しくなる相棒のような存在"だという。「ドラえもんというのは、そもそものび太が将来しずかちゃんと結婚できるようにサポートするために未来からやってきたロボット。いつも傍にいて、その人が何をしたいのかを全部理解して手助けをしていく。夢を達成するためのバックアップをするというのがドラえもんという存在です」"ドラえもん"と聞いて、私たちがすぐにイメージするのは、丸くて青色のネコ型ロボット。しかし、ネットスマイルが開発しようとしているのは"人工知能"の部分。あくまでソフトの部分であり、ハードではない。では、ドラえもんのような人工知能の開発というのは、具体的に何を指すのだろうか。「今一番力を入れているのは"対話エンジン"です。コミュニケーションの部分ですね。対話エンジンとしてさまざまなハードやデバイスに搭載していくようなイメージです。ロボットに搭載するというのもありですし、IoTとつなげて機器に搭載したり。『アイアンマン』のジャービスのイメージに近いですね。あとは『サマーウォーズ』のアバターみたいに画面上で対話するというのも考えられます。大きなSNSみたいな感じで、AI同士もコミュニケーションするし、人間同士もコミュニケーションする世界観ですね」自然言語を理解・学習し、人間の意志決定を支援するという意味では、IBMが開発した"ワトソン"にも近いのかもしれない。また、人の感情を理解するという意味では、ソフトバンクの"Pepper"も思い起こされる。"ドラえもんのような人工知能"はそれらとは何が違うのだろうか。「ワトソンは英語ベースで開発されていますが、日本語はまだです。我々がやろうとしているのは日本語です。一方、Pepperのアルゴリズムは教えたことをそのままやるみたいなイメージ。人間の脳というのも一定のルールをもとに動いているのですが、ロボットとはそのルールの普遍性が違うので、概念まで踏み込まなければなりません。そういう次元の対話エンジンを目指しています。ディープラーニングで画像認識や音声認識、すなわち目や耳にあたる部分の研究もしています」(※編注:インタビュー実施後、IBMがワトソンの日本語対応を発表した)ネットスマイルでは、さらに人工知能をプラットフォームとして提供していく意向だという。つまり、人工知能のプロファイルをユーザー自身がそれぞれ用意されたプラットフォーム上で作成するという方向を志すという。「ひとりの人間が100のAIを持てることをイメージしています。例えば株式の情報を収集するAIや料理のレシピに詳しいAIといった具合に、いろんなパターンのAIがあって、誰が自分のAIを持っている。そして、AIが分身となり、コンシェルジュのようにサポートしてくれるようなイメージです」●夢の達成を手伝うための人工知能○AIに人間臭さは必要か?ドラえもんと聞いて私たちがもうひとつイメージするのが、お節介だけど少し間の抜けたユニークなキャラクター。ロボットだけど人間味のある部分に魅かれる部分もあるだろう。ドラえもんのような人工知能を開発するにあたり、この部分を齊藤氏はどのように考えているのだろうか。「AIに人間味があったほうが私はいいと思います。ないとあまり使われなくなるような気がします。というのも、人と人の関わりの中でも"コミュニケーションロス"というのは発生するもの。最初からプログラミングする必要はないと思いますが、ある程度の許容はあってもいいのではないかと感じます。自動車を制御するのであれば効率だけで人間味は一切必要ありませんが、コミュニケーションのためのAIですから。一番重要なのはAIが人間に対して興味があるか。そうでなければコミュニケーションが成り立たないと思います。その人なりの夢を達成するお手伝いをするための人工知能なので、嫌われない程度にお節介だったりするということも大切ではないかと」ネットスマイルが開発している人工知能は、ネット上にある全データを理解し、入力した"夢"に対してインターネット上からすべての情報を引っ張ってきて解析し、それをもとにユーザーのパーソナリティと結びつけながら会話をするというのが大まかな仕組みとのこと。しかし、人工知能そのものが持つデータは限定したものになるという。齋藤氏はその理由を次のように話す。「日本語の全部のデータを入れたら、多分ドラえもんは支離滅裂になってしまいます。というのも、そもそも人間というのは自分の持っている知識と経験は限定的なもの。ゆえにパーソナリティが出るのであって、万能なドラえもんというのはないんです」○学校に行けない子供たちのために「コンシェルジュみたいな存在で、題材が身近なものが欲しかった」ことが、ドラえもんのような人工知能の開発のきっかけと話す齋藤氏。5年以内に世界に向けて示せるものを形にしたいという目標を掲げている。実用化にあたっての具体的なビジネスモデルについて、次のように明かす。「今、具体的にお話をしているのがコールセンターの応答。人間がしゃべっているようなインターフェースとしての人工知能です。人間が触れ合うところはビジネスモデルがあると考えています」と齊藤氏。「もっと大きなところでは、世界には発展途上国で学校に行けない子どもたちが5億人ぐらいいると言われています。例えばエボラ出血熱が蔓延しているような地域には教師が行きたくても行けません。でも、ドラえもんがそういうところの子どもたちに教えてあげる。貧しい国に無料で配ることで世界のインテリジェンスが底上げされれば経済格差や情報格差がなくなって世の中がもっとよくなるのではないかと。ドラえもんのような人工知能がそれを解消させる存在になれれば」と、さらなる夢も語る。●AIは"人を幸せにしたい"という欲求を持つ○開発が進めば恋愛のアドバイスも可能にそれでは実際に、現時点での開発段階はどのレベルまで進んでいるのだろうか。気になるところを訊ねてみた。「人間で言うと今2歳児ぐらいですね。今年中に10歳ぐらいにしたいと計画を立てています。6歳ぐらいを超えてきたところで、Twitterとかでつぶやけるとか、何か出したいと思っています。まずは楽しんでもらえるような。子どもたちに教えられるようになるには、20歳ぐらいですかね。まずは小学生ぐらいにできたら、"もう1人のお友だち"みたいに、寂しいところに傍にいてサポートしてくれるようなものになると思います」一方、マンガの世界では"しずかちゃんとのび太の恋の行方"を応援するドラえもんだが、人工知能が恋愛のアドバイスまでできるようになるのか。齋藤氏は次のように考えを明かした。「身体性を持たないロボットの場合、心の"ときめき"とかを理解するかというと、そこまでは解釈できません。とはいえ、"人を幸せにしたい"というのもAIの欲求の1つなので、"何かに恋をする"という欲求を入れることはできるかもしれません。でも、イメージができるようになるまでに10年ぐらいかかると思います。人工知能が恋愛アドバイスをできるようになったら30歳ぐらいの年齢ですね。プログラムする人の感情とか考え方といったパーソナリティが大きく反映されると思います」○シンギュラリティを目指しているわけではない人工知能と言うと、最近では人間の知を超えて暴走することへの脅威に話題が及びがちだが、齊藤氏は「ドラえもんが目指すのはシンギュラリティではない」と強調する。「人間社会とAIの社会は最終的には似るんじゃないかと個人的には思っています。人間の社会と同じように、悪いAIが居ればそれを封じ込めるような良いAIが登場する。『鉄腕アトム』と同じことですね。悪意を持ったAIよりも善意のAIが上回ることで自治する。30~40年後ぐらいにはそういう世界になるんじゃないかと思っています」そしてそんな中、ネットスマイルが開発しているのは、"明るく楽しい社会"をつくる人工知能だ。「ドラえもんと話すことで、世界が広がって、人生が楽しく希望を持って暮らしていけるような人工知能」というのが、ネットスマイルが定義する、ドラえもんのような人工知能だ。
2016年02月22日
●ディープラーニングに必要なこと人間の限界を超え、新たな発明や発見につながるものとして、さまざまな産業界で注目されている人工知能(AI)。近年の、人工知能開発の飛躍的な進化を支えているのが技術面での進歩だ。前回は人工知能に関わる3つの要素を紹介し、その中の1つ「GPU」において、NVIDIAが大きな役割を担っていることを紹介した。今回は人工知能の発展において、GPUが具体的にどのような役割を果たしているかを見てみよう。○ディープラーニングは莫大な演算の繰り返し人工知能のブレイクスルーである「ディープラーニング」。単純な変換を多層に繰り返すその手法は、数学的には『(x1 x2 x3)(y1 y2 y3)…』と記述する「行列演算」をひたすら繰り返しているのに似ている(実際にはもっと複雑だが)。こうした演算の繰り返しはまさにコンピュータが得意とするところだが、コンピュータの中央演算装置である「CPU」は、行列演算だけでなく、さまざまな演算を汎用的に行うように開発されているため、行列演算はそれほど高速ではない。コンピュータの世界では、実行する処理が限定されているのであれば、その処理を専門的に処理するようハードウェア的に実装したほうが、より高速で効率良く行える。例えば動画を再生するなら、動画再生に最適化された回路を作ったほうが、ソフトウェア的に処理するよりはるかに高速なのだ。それでは行列演算に最適化された回路を開発すれば、より高速にディープラーニングを処理できるのだろうか?答えはイエスだ。ただし、わざわざこれから開発するまでもなく、すでにそのような処理に特化された「GPUコンピューティング」が存在している。GPUコンピューティングとは、本来3Dを中心にグラフィック描画を専門に行う「GPU」に特定の演算処理を任せようというものだ。GPUはゲームなどが要求する超高度なグラフィックを高解像度・高速に処理するため、グラフィック処理についてはCPUを上回るほどの処理能力を与えられているのだが、これを特定の演算に応用しようというのが「GPUコンピューティング」の考え方だ。たとえば3Dグラフィックで、3次元空間にある立方体を回転させ、それを2次元であるモニターに投影する場合、各頂点の位置がどのように見えるかは、8つある頂点の、X、Y、Z軸それぞれの座標を行列変換するのに等しい。GPUコンピューティングこそ、まさにディープラーニングに求められている資質そのものだと言えるわけだ。こうしたGPUコンピューティングをいち早く提唱し、実践してきたのが米NVIDIA社だ。同社はゲーミングPC用の「GeForce」、あるいはグラフィックワークステーション用の「Quadro」といったGPUで知られているが、いずれも同社のGPU用開発環境「CUDA」を用いたプログラムで、3Dグラフィックではなく特定の演算処理を行わせることができる。●GPUはCPUの最大10倍速○GPUコンピューティングの先端を走るNVIDIA実際、GPUで処理した場合とCPUで処理した場合では、最大で10倍近くもの速度差が現れる。あたらしいアルゴリズムを組み上げ、データを処理させた結果を確認し、新たな推論を打ち立てる人工知能開発の現場において、数週間かかっていたデータ処理が数日で終わることのアドバンテージは計り知れない。NVIDIAは同社のGPUコアと大量のメモリを搭載した「Tesla」ブランドの演算カードを開発しており、これをセットすることでPCやワークステーション、サーバーがGPUコンピューティングに対応したアプリを超高速で実行できるようになる。拡張スロットに取り付けるタイプのカードなので、1台の本体に対して数枚のカードをインストールすれば、性能向上に対する空間効率も非常に高くできる。ディープラーニングにおいては、CaffeやChainer、Theanoといったディープラーニング用ソフトがNVIDIA Teslaに対応済みであり、実際にGoogleやIBMといった巨大企業のサーバーファームから、大学の研究室レベルまで、多彩なスケールで実際にTeslaを使ったディープラーニングが行なわれている。まさにNVIDIA Teslaの処理能力が人工知能の爆発的な進化を支えているかたちだ。○NVIDIAがこれから目指すものGPUコンピューティングそのものは、NVIDIAのほかに米インテル社や米AMD社など、NVIDIAとGPUで競合するメーカーも開発を進めている。また、GPUの種類を問わず利用できる開発環境として「OpenCL」「DirectCompute」といった共通規格もあるのだが、インテルはCPU内蔵GPUに注力しており、単体で強力なGPUを開発していない。AMDは単独のGPU「RADEON」シリーズを販売しているが、NVIDIAの「Tesla」に相当するGPUコンピューティング向けの演算カードは販売していない。特にTeslaのような演算カードの存在は、実際の研究機関などで採用されるにあたって大きなアドバンテージになる。開発環境の実績や充実度を見ると、実質NVIDIAの一強という状況だ。また、NVIDIAはTeslaの高い処理能力を活用する場として、自動車業界をターゲットに挙げている。現代の自動車は随所にセンサーを設けており、それらから走行中に毎秒入力されるデータは非常に莫大な量になる。さらに、これが自動運転車となると、カメラの映像や音波など、センサーの数も入力されるデータの量も格段に跳ね上がる。こうした大量のデータを瞬時に処理し、事故を起こさずに走行するよう、自動運転車には人工知能的なアプローチが行なわれているのだが、ここにTeslaの強力な処理能力を生かそうというわけだ。このように、人工知能や自動運転といった次世代の重要な技術においては、GPUコンピューティングが非常に大きな役割を持つ。そして、GPUコンピューティングの進化を最前列で支えるNVIDIAの存在は、これからのIT分野や産業界において、その進化の速度を左右する、非常に重要なポジションを得ていくことは間違いない。
2016年02月22日
TED2016において、XPRIZE FoundationとIBMがコグニティブコンピューティングのコンテスト「The IBM Watson AI XPRIZE」の開催を発表した。参加チームは、世界が抱える大きな問題を解決する人とAIのコラボレーションのアイディアを示す。賞金総額は500万ドルだ。XPRIZEは民間による有人弾道宇宙飛行のコンテストを開催して話題になり、その後もゲノム解読のスピードや民間による月面無人探査など、技術進歩と変革を促す様々なコンテストを行ってきた。これまでのコンテストではXPRIZEが目標を設定し、その達成を参加チームが競っていたが、AI XPRIZEでは参加チームがそれぞれAI-ヒューマン・コラボレーションにおいて挑戦する内容を定義できる。参加チームはまずIBMのカンファレンス「World of Watson」において中間賞(賞金50万ドル)を争い、絞り込まれた上位3チームがファイナリストとしてTED2020のステージでプレゼンテーションを行う。優勝賞金は450万ドル。
2016年02月18日
●人工知能の進化で人間に残される仕事今、ITの世界で最もホットなバズワードである人工知能(AI)。人工知能がやがてビジネスの世界にも影響を与えるのは免れないことは、前回紹介した。果たして人工知能は今後どのように進化を遂げ、ビジネスパーソンはそれに対してどう対処していけばいいのか。人工知能開発のエキスパートであるセバスチャン・スラン氏に、人工知能時代のビジネスシーンの将来像を伺ってみた。○人工知能が仕事を進化させるセバスチャン・スラン氏は、米Google社で先進的技術の開発部門である「Google X」を創設し、自動運転車やGoogle Glassの開発を率いた人物だ。スラン氏はGoogle Xで自動運転車の開発を進めるにあたって人工知能(機械学習)を採用し、目覚ましい成果を挙げた。現在は科学技術・工学・数学などの分野の教育を提供する「Udacity」のCEOを務め、教育分野に力を入れている。今回、人工知能を搭載したERPシステム「HUE」の発表に合わせて来日。HUEのデモンストレーションを見たスラン氏は、同システムで仕事の効率が高まることは認めつつも、同時に「ある分野では仕事が減る」とも警告する。「あと数年すると、大企業の社長が会計士に『今後はコンピュータに会計をまかせるよ』という時代がくるかもしれない」(以下、発言はスラン氏)そう言って、今後、数年~数十年で消滅する業種をリストアップして見せた。この中には秘書やパイロット、会計士、弁護士といった、現在では花形といってもいい知的職業も多く含まれているが、スラン氏によればこういった職業の多くは反復作業をしているに過ぎず、クリエイティブな作業ではないのだという。確かに、パイロットならすでに自動パイロット装置があり、飛行場によっては自動装置の利用を義務付けているところもある。会計士や税理士は本質的にはルーチンワークだし、過去の判例と突き合わせるといった作業においては、人間よりも人工知能のほうがはるかに素早く正確だ(米国ではすでに、特定ジャンルに特化した人工知能を導入した法律事務所もある)。複雑な事件でもなければ、若手の弁護士で足りるような仕事は人工知能がやればいい、というわけだ。スラン氏は技術の進歩に伴って一定の職業がなくなり、機械に置き換えられるのは、避けられないことだという。グーテンベルグの印刷機によって写筆家が職を失い、産業革命によって多くの手工業が機械工業に取って代わられたように、現代でも技術の進歩によって仕事自体が変わらざるをえない。しかも、その変革は想像しているよりもずっと早くやってくるというのだ。●人工知能が生み出す変革○人間はより高度な仕事へシフトするスラン氏の語るように、人工知能が90%もの仕事を肩代わりしてくれるのであれば、人間は残り10%にもっと力を注げるようになる。過去に調べ物といえば辞書や書籍をめくるしかなかったものが、今は検索エンジンにまかせれば、たいていの情報は百科事典よりも詳しく、瞬時に調べられる。調べ物における検索エンジンの役割を、さまざまな業務で担うのが人工知能というわけだ。それでは、具体的にどの程度の仕事が機械に取って代わられるのだろうか? ホワイトカラーについては、スラン氏は「反復作業はすべて」と断言する。報告書や請求書の作成といった作業はまさに、反復作業の典型例だ。一方で「弁護士の仕事も90%はなくなるでしょうが、10%は置き換えられないと思います」ともいう。要は、誰でもこなせる仕事(Low IQな仕事)は人工知能がとって替わり、人工知能がカバーできない高度な知識や技能を要する仕事をこなせる人だけが生き延びられるということだ。また、自分の職種が前述のリストに入っていないといって安心してはいられない。スラン氏は「なんでもいいから職業を1つ、人工知能に1年間学習させてみれば、おそらく人間よりも効率的にその仕事をこなせるようになるでしょう」とも言っているのだ。確かに、一部の創造的な業種を除けば、仕事の大半はルーチンワークだったり、過去の事例から類推できることが多く、これらは人工知能がカバーできる範囲だ。このままいけば、やがて現在の人間の仕事の多くは人工知能に取って代わられてしまうのは避けられないようだ。○人工知能が新たな身分制を生み出す?一方で懸念もある。企業内の人員はやがて、方針を決める一部の人間と、会社のオペレーションに必要な最小限の人間、そして大量の人工知能だけで賄われることになり、人工知能を使える人間と、人工知能に使われる人間の2種類に大きく分けられてしまうのではないか。いわば、新たな身分制の登場だ。それによって職を失う人もいるかもしれない。しかしスラン氏は、憂慮ばかりしなくてもいい、とフォローする。「たとえば農業はテクノロジーが関与したことで、400年前と比べて、98%の仕事がなくなりました。鍬や鋤を使って手作業で行っていたものが、機械に置き換えられたのです。しかし、テクノロジーがあることで、パイロットやプログラマー、サウンドエキスパートといった新しい職種が生まれました。だから無職になるわけではありませんし、人はそもそも、働きたい生き物だと思います。きっとやることは見つかります」。確かに、コンピュータが登場する前は職業プログラマーや、果てはプロゲーマーといった職種が登場すると想像した人はいなかっただろう。たとえば人工知能を搭載したロボットが警備員の仕事を奪うかもしれないが、同時に警備ロボットのメンテナンスという新たな仕事が現れるはず。勤労意欲のある人は、決して悲観するばかりでなくともいいというわけだ。●賢くなる人工知能にどう対応するか○変革に備えるために学び続ける今後、ほとんどの業種で人工知能が関わってくるのは、もう避けられない。人工知能に仕事を奪われる可能性を前提に、ビジネスマンはどのように備えればいいのだろうか。スラン氏は新しい時代に備えるにあたり、教育の重要性について指摘する。ビジネスマンも、人工知能の登場に備えて、新たなテクノロジーか、あらたな職種について学ばねばならないというわけだ。スラン氏自身、Udacityにおいて、社会人への教育に力を入れている。「教育というのは、人生のある一時受けるものだという考えをやめなければなりません。生涯教育です。人生のお供であり、一生やり続けるものです」。耳の痛いことだが、新たな時代に向けて学ぶ意欲がなければ、適応していけないという指摘は確かだろう。Udacityでは特にシリコンバレーで必要とされる職種に必要とされる、カリキュラムを無料で受講できる仕組みを用意しているが、これはすべての人が受けられる内容ではない。どんな職種であれ、自分自身のレベルを客観的に判断し、冷静に自分が学ぶべき内容を把握することが大切だ。「時々辛いと思うのは、労働者の多くが、新しいことを何も学びたくないということです。学ぶということが素晴らしいということを、そうした人たちに伝えたいですね」とスラン氏が語るように、現状の仕事をこなす忙しさのあまり、新たなことを学ぶ努力は怠りがちだ。しかし、今後、仕事のスタイルがこれまでと大きく変わる時代が到来するにあたり、学ぶ努力を怠らなかった者が生き延びられる時代が来るだろう。常にアンテナを広く張り、新しいものを積極的に取り入れていく姿勢こそが、人間が人工知能と共存していくために求められる資質ということになるだろう。
2016年02月09日
デルはこのほど、Cylanceの人工知能を活用したセキュリティ技術を採用したエンドポイント向けマルウェア対策スイート「Dell Data Protection | Endpoint Security Suite Enterprise」と、法人向けPC用の「POST(Power On Self Test)ブート BIOS 検証ソリューション」を発表した。Cylanceは、人工知能を活用したセキュリティ技術を開発しており、APT攻撃やゼロデイ攻撃で使用されるマルウェア、スピアフィッシング、ランサムウェアに対する防御機能を持つ。同社の技術を採用したエンドポイント向けのセキュリティ・ソリューションは「Endpoint Security Suite Enterprise」が初めてだという。Cylanceの検証では、99%のマルウェアとAPT攻撃を組織できるとしている。同ソリューションでは、ウイルス定義ファイルの定期的な更新が不要であるほか、管理者が単一のコンソールですべてのコンポーネントを管理できるため、エンドポイントセキュリティの管理に必要となる時間やリソースが削減できるという。一方のPOST(Power On Self Test)ブート BIOS 検証ソリューションでは、クラウド環境下で、個別のBIOSイメージをデルのBIOSラボの公式基準値と比較検証し、ブートイメージに脅威が入り込んでいないかを検知できる。このBIOS検証機能は、デルが提供する第6世代インテル Core プロセッサーを搭載した法人向けPCで利用できる。
2016年02月09日
人工知能を活用することで英語教育を可能としたロボット「Musio」の開発を手がけるAKAは2月5日、成基およびGLOBAL VISIONの2社と 「教育効果の実証実験並びに教材開発実施に関する協力覚書(MOU:Memorandum of Understanding)」を締結したと発表した。今回のMOUは、2016年6月に予定しているMusioの正式販売前に成基およびGLOBAL VISIONが日本で蓄積してきた英語教育に関する知見やノウハウをもとに、 Musioを日本の英語教育向けに最適化していくことを目指したもの。具体的には、 成基が運営する英語学童教室「GKC(グローバルキッズ倶楽部)」ならびに個別指導塾「ゴールフリー」などにおけるMusioのパイロット導入および実証実験を通じて、 Musioを活用したより効果的な学習方法を開発するとしている。 また GLOBAL VISIONは、 実証実験で得られた知見をもとにAKAと共に英語学習コンテンツの開発を行い、同社のネットワークを通してMusioを公的・私的教育的機関へ販売する予定としている。なお、MusioはすでにAKAのWebサイトにて予約受付を開始している。
2016年02月06日
Hameeは2月4日、ECマーケットでの未来の働き方を実現する次世代ソリューションの開発を目的として、人工知能・機械学習を研究する「ネクストエンジンAIラボ」を設立したと発表した。同社がこれまで提供してきた「ネクストエンジン」は、大手ショッピングモールや自社で運営するECサイトの出品・注文・在庫をまとめて管理することができるクラウドサービス。今後も商取引の電子化が進展すると予想されるなか、EC運営業務は、マーケティング、広告効果検証、マーチャンダイジング、商品開発、カスタマーサービス、デザイン、写真撮影、商品登録、受注、発注、在庫管理、物流、経理、モール出品、カート構築など多岐にわたり、さらにオンラインモールなどの販売プラットフォーム、商品カテゴリ、ECを支えるソリューションごとにフォーマットの統一がされておらず、アナログで行う作業が多いことから、生産性が高くないといった課題があるという。同社は、このような現状をふまえ、EC運営者が本来やるべき"ビジネスの成長"だけに専念できる世界を実現すべく、新たな領域の研究を行う専門組織を設立するに至ったとしている。また、「ネクストエンジンAIラボ」設立に先立ち、AIや機械学習、ビッグデータ、オフィス自動化関連の研究者、エンジニア、Eコマースの専門家、協力事業者、大学などの研究機関の募集を開始するという。
2016年02月04日
2月3日(現地時間)、MicrosoftはAI(人工知能)を使って入力予測を行うキーボードアプリケーション「SwiftKey」の開発元を買収したことを発表した。Microsoftは買収額を明らかにしていない。同社は今後数カ月内にSwiftKeyの技術をMicrosoft Researchが開発したWindows Phone向けキーボード「Word Flow」と統合する。SwiftKeyはユーザーの入力スタイルを学習しながら、その使用頻度の高い単語候補を提示するスタイルのキーボードアプリケーション。Android版は2010年からリリースし、iOS版は2014年から提供が始まった。既にMicrosoft Researchが開発したWord FlowをWindows Phone用にリリースし、現在iOS版のベータテストが行われている。Microsoft Technology and Research担当EVPのHarry Shum氏は、「今回の買収は、すべてのプラットフォームへサービスを提供するというMicrosoftの取り組みを示すものだ」と述べた。なお、今回の買収により、SwiftKey CTOであるDr. Ben Medlock氏とCEOのJon Reynolds氏はMicrosoftに参加。同社はAI分野やスマートフォン事業の強化を実現したこととなる。阿久津良和(Cactus)
2016年02月04日
ミライセルフは2月2日、クイズとAIを用いて社員の価値観を元に業務への適性判定・分析を行うサービス「mitsucari(ミツカリ)」の提供を開始した。クイズは、米カリフォルニア大学バークレー校で10年以上研究されている社会心理学と100名以上を対象としたインタビューに基づいて作成しており、従業員の"価値観"を分析する。例えば「直感と確実性のどちらが大切か」「レストランの選び方」といった質問からキャリア指向性や個性を判断する。クイズは全48問が用意され、10分程度で回答できるものになる。クイズの回答データは、社員の人柄や価値観を14項目7段階に、感受性と指向性を5段階でデータ化され、その後、人工知能を用いて価値観などと部署の文化の相関関係を分析して社員の適性を判定する。人工知能の機械学習は、顧客企業に応じて重視する価値観や傾向が異なるため、それぞれに応じて適性判定を行い、精度向上にも役立てる。会社全体や部署に対する適正判定だけでなく、最も似た価値観を持つ社員の名前も表示する。これにより、経営者や人事、上層部の直感で行われていた採用・人事配属が「データ分析による客観的なものに変わる」としている。サービスは、社員1~20名規模向け「スタートアッププラン」と21名~100名規模向け「レギュラープラン」が用意されており、101名以上は個別見積もり。スタートアッププランは月額5000円、レギュラープランは月額2万円(いずれも税別)となっている。
2016年02月03日
●ディープラーニングが生まれるまで現在、IT業界のみならず、さまざまな産業界で最もホットな話題のひとつである「人工知能(AI)」。かつてSFの夢物語だった「考える機械」が、今、さまざまな産業界において、急速なピッチで現実のものになろうとしている。人工知能の進化の裏には、技術面での進化が欠かせないものだった。○人工知能のレベルを引き上げた「ディープラーニング」人工知能というと、映画「2001年宇宙の旅」の「HAL」のように人類に反乱を起こすちょっと危険なコンピュータ、あるいは「鉄腕アトム」や「ドラえもん」のように人間臭い感情を持ったロボットのことを思い出す人が多いのではないだろうか。現実の人工知能はこういったレベルには達しておらず、画像認識や音声認識など、限られた処理において、「人間が正確に条件を入力しなくても、自分で推測して答えを導き出す」という程度のものにすぎない。しかし、技術の進歩に伴い、その精度と速度は人間を上回るものになろうとしている。たとえば、画像の中に何が写り込んでいるかを見つけ出す画像認識については、2011年ごろまでは「機械学習」という手法で鍛えられた人工知能は長年、80%程度の正答率を超えることができなかった。しかし2012年に新しい処理方法「ディープラーニング」を使って鍛え上げた人工知能が国際的な画像認識コンテスト「ILSVRC」で前年を大きく下回る誤認識率となった。人間の誤認識率は約5%とされており、2015年にはついに人間を上回る精度を実現している。機械に、人間のように「自分で判断し、自分で答えを見つけ出す」機能を実現させようという試みは、実は1940年代にはスタートしている。「ニューラルネットワーク」という人間の脳の神経伝達を模倣したモデルのうち、最初期の手法である「パーセプトロン」が、最初の学習機能を持った人工知能として登場した。しかし、このパーセプトロンでは解決できない問題が生じてしまった。やがて、「隠れ層」と呼ばれるものを加えた新たなモデルが登場することが問題解決の糸口となったが、十分な精度をもたらすための莫大なデータと、それを現実的な速度で処理する処理速度がなかったため、2000年代にいたるまで人工知能の進化は限定的なものだった。2000年代に入りインターネットの普及で、学習に利用できる莫大なデータが容易に入手できるようになり、一気にニューラルネットワークを使った研究が進むようになる。特に数段階以上と深い階層を用いるニューラルネットワークを使った学習を「ディープラーニング」(深層学習)と呼ぶようになり、これがそれまでの限定的な浅い階層しか持たない人工知能との決定的な差を生むことになった。●ディープラーニングの利点○ディープラーニングの何がすごいのかディープラーニングは、それまでの機械学習を発展させたものだ。機械学習では、コンピュータに入力するデータの中から、解析に役立ちそうな特徴を抽出するための仕組みに人の手が介在した。ところがディープラーニングでは、こうした特徴抽出すらも処理の中に含まれており、特徴の選択も機械が学習する。人間は最小限の下処理をしたデータを人工知能に与えてやるだけでいい。たとえば10万枚の写真の中から「猫」の映った画像だけを探す場合、従来の手段では猫っぽい特徴のあるデータをあらかじめいくつか用意しておき、その部分を指定しておくと、機械がその特徴に似た部分を探してくれるというものだった。これがディープラーニングだと、与えられた写真を精査し、「これは猫っぽいのではないか」という答えを機械が人間に示してくる。それに対して人間が評価を与えると、その評価をもとに再度データを調べ直す、という手法で精度が徐々に高まっていく。まるで「これは? これは?」と親に聞いてくる子供が、さまざまなものを覚えていくような動きだ。ディープラーニングは画像認識のほか、自然言語解析や、いわゆるビッグデータのような莫大なデータの解析を得意としている。人間に並び、あるいは上回る精度で有意なデータを見出すことができるディープラーニングから得られる推測データは、人間が参考にするに十分な信頼性を持っている、あるいは人間の感性を超えた解答をもたらす可能性があるのだ。たとえば米IBM社の人工知能「Watson」は、数十万のレシピを学習した結果、これまでになかった新しいレシピを「提案」するに至っている。チェスや将棋の世界でも、ディープラーニングで過去の打ち筋を研究した対戦プログラムが、これまでの定石とは全く異なる新しい打ち筋を「発明」している。つまり、人工知能は人間と並ぶ、あるいは超える「知性」を持って、これまでの人類の知能が発見できなかった新しい知見にたどり着くことができる可能性を持っているわけだ。事実、製薬分野などでこれまでに見つかっていない新薬を人工知能が「発明」しているケースもある。これこそがディープラーニングがもたらした人工知能のブレイクスルーそのものだと言っていいだろう。●人工知能の発達を決める3つの要素○ディープラーニングを支える2つの柱ディープラーニングには、ニューラルネットワークを鍛えるための莫大な量のデータと、それを処理するための超高速なコンピュータの2つが必要だ。ディープラーニングにたどり着くまでに、十分な精度をもたらすための莫大なデータと、それを現実的な速度で処理する処理速度がなかったため、2000年代にいたるまで人工知能の進化は限定的だったと記したが、そのことは、最近の研究事例を見てもわかる。たとえば、2012年にGoogleが猫の概念をディープラーニングによって抽出するのに、200×200ピクセルのYouTube動画から切り出した画像を1000万枚用意し、1000台のコンピュータ(16000CPUコア)を使ってようやく達成できたものだ。しかも時間は1週間かかっている。幸い、大量のデータは、今ならインターネットにいくらでもデータが転がっている。企業などであれば、行動データやいわゆるビッグデータも、人工知能を鍛える上でもってこいの「餌」なわけだ。もう1つの超高速なコンピュータについても、毎年の技術革新のおかげで、スーパーコンピュータクラスの超高速処理が可能なコンピュータを、個人の研究者がなんとか揃えられるようなレベルにまで価格が下がってきている。ただし、ここでイメージすべきは、超高性能CPUではない。求められるのは、GPUの性能となる。そして、GPUの開発環境や実績などを見ていくと、ディープラーニングの発達は米NVIDIAが握っているとも言えるのだ。NVIDIA自身も、今ではこの人工知能の分野に力を入れている。ではなぜGPUの発達が求められるのか、NVIDIAがこの分野で取り組んでいるのは、どんなことか。次回はこの点についてみていこう。
2016年02月02日
「人工知能(AI:Artificial Intelligence)」は、1950年代にはパーセプトロンが考案されてブームになったが、できることが限定されていることから下火になった。その後も1980年代にはエキスパートシステムのブームが起こり、わが国では第5世代プロジェクトが推進された。しかし、エキスパートシステムは開発が難しく、適用性が限定されているという問題があり再び下火となった。第3次のブームは、IBMのDeep Blueが人間のチェスチャンピオンを破った1997年ころからである。その後、2005年にはDARPAのロボットカーチャレンジで、スタンフォード大学の車が砂漠のコースの無人走行に成功した。これらは、ある意味で、特定の目的のために作られた人工知能システムであったが、2011年にはIBMのWatsonがJeopardy!で人間のチャンピオンを破り、広い範囲の問題に対する人工知能の可能性を示した。2012年には、画像認識の分野でトロント大学のHinton教授のグループが素晴らしい成績を上げて、「ディープラーニング」が注目されることになった。ディープラーニングとはいかなるものかを、2015年に開催された「NVIDIA GTC」におけるGoogleのJeff Dean氏の基調講演とそのスライドを基にして説明する。○ディープラーニングとはどのようなシステムかディープラーニングのシステムは、人間の脳についての知識を利用して階層的に認識を行うシステムである。次の図の正方形の中に描かれている●や○は神経細胞のような働きをする。猫の画像を第1層の神経細胞に入力して処理を行い、その出力を第2層の神経細胞に入力して処理するという多層構造になっており、脳がそれぞれの場所でだんだんと高次の抽象性を持った情報を抽出するのと似たような処理を行い、後の層になるほど抽象度の高い情報を抽出する。次の図の上側のニューロンは、下のx1、x2、x3と書かれたニューロンからの信号にそれぞれ、w1、w2、w3という重みを掛けて、それらの総和を取り、総和を非線形の関数(ここでは、正の入力はそのままで、負の入力は0にするmax(0,x))を通して出力を作る。また、単に総和だけではなく、定数のバイアスを加えるというケースも多い。重みは正の値とは限らず、負の値を持つ場合もある。ここでは図を書く都合で入力は3つしか描かれていないが、実際にはもっと多数の入力を持ったニューロンが使われる。また、max poolingと呼ぶ、小領域のデータの最大値を選択する演算が追加されることが多い。ここで最初の層のxiは入力画像のピクセルで、単純な数値ではなく、RGBの値などを持っている。2層目以降の出力は、ネットワークの設計に依存し、もっと複雑な情報を持つ場合が多いが、最終出力では0~1の範囲の1つの数値という場合もある。そして、このようなニューロンからなる層を重ねたニューラルネットワークを構成する。通常、この図のように、一番下の層が入力層で、一番上の層が出力層として描かれる。そして、中間の層は隠れ層と呼ばれる。この図ではニューロンの数が少ないが、実際には各層のニューロン数はもっと多いし、層数も多いネットワークが使われる。このニューラルネットワークが、猫の画像を見て、猫と認識できるかどうかは、学習に掛かっている。最初は、まったく認識出来ないのであるが、猫の画像の場合は、出力層が猫と出力すれば正解と教え、猫でない画像の場合に猫と出力すれば誤りと教えてやる。なお、猫であるかどうかだけを認識するシステムなら、出力は1つで猫らしさを示す値だけを出力すれば良い。手書きの郵便番号認識システムでは出力は10本あり、それぞれの出力は0~9の数字らしさを示す数値を出力する。学習は、例えば、次の図でxは入力画像で、yは猫らしさの正解の値である。1つの画像を選び、xを入力して、ネットワークのニューロンの出力を順に計算して出力を得る。この値が正しくない場合は、出力が正解yに近づくよう重みを変更する。これを多数の猫の画像を使って行う。一般的に猫を認識するには、いろいろな種類の猫のいろいろな姿勢で、背景もいろいろな種類の画像を用いて学習させる必要がある。インターネットから多数の画像が集められるようになったことが、ディープラーニングの認識精度が向上した大きな理由の1つである。また、多数の画像で学習を行うので、計算量は膨大であるが、コンピュータが速くなり、最近ではGPUを使って、さらに高速に学習を行えるようになったことが貢献している。
2016年02月02日
●Pepperの魅力は集客力のみか人のように動き、仕事をこなすロボットがいる職場。数年前までは夢物語だったが、人工知能搭載ロボットのPepperはそれをすでに実現しつつある。今では企業や量販店などの受付・応対がメインで、実行できることは限られているが、今後は様々な分野で活躍すると見られている。Pepperはどんなシーンに入り込んでいくのか。○Pepperはすでに500社以上に導入Pepperが企業に導入されたのは2014年末のこと。まだわずか1年強の時間しかたっていないが、すでに500社以上に導入されている。その主な活用は、応対・接客だ。ネスレ日本は、集客効果を期待して、コーヒーメーカーの販売スタッフとしてPepperを活用。販売店に配置して、Pepperに商品紹介を行わせたところ、売上は15%アップしたという。みずほ銀行も集客効果、窓口への誘導などを期待し、Pepperを導入。来客を応対し、金融商品の提案を行うなど、応対した客の10%以上をカウンターに送客し、成果を挙げた。こうした事例は増えており、Pepperがビジネスシーンで活躍する姿を見聞きする機会が増えた。しかし、今現状でPepperに期待されているのは、物珍しさによる"集客力"だ。その位置づけはまだ"客寄せパンダ"という域からは出ていない。そんなPepperに求められているのが新たな力。それを付加するのが、アプリケーションであり、新たなビジネスシーンに入り込む力になりうる。その可能性を見える形にしたのが、27日、28日の2日間開催されたイベント「Pepper World 2016」である。●医療、介護、教育分野に入り込むPepper○Pepperが入り込むシーン「Pepper World 2016」で示されたPepperの利用シーン。そこから見えてきたのは、医療、介護、教育分野への利用の広がりだった。医療分野では、GE HealthcareがMRI検査でのPepper活用法を紹介する。同社は、Pepperに説明能力と"和ませ力"に期待する。MRIは精密検査であり、検査の注意事項が多いため、実施前に緊張がとけない人も多い。そこで、Pepperに手順や注意事項の説明役を担わせる。これにより、注意事項の説明の漏れがなくなる。愛嬌のある動作をすることで、患者を和ませることも可能だ。同社の説明員によると「まだ実証実験を行っていないので、何ともいえないが、Pepperには、緊張感を和らげる効果を期待したい」と話す。介護分野でも医療同様の効果が期待される。エクシングは介護施設向けレクリエーションアプリを開発。体操、クイズ、カラオケといったコンテンツでPepperと遊べるようになっている。実際に高齢者が使ってみると、Pepperを「孫みたいに思った」というケースもあったという。教育分野では、英会話能力をPepperがアップしてくれるかもしれない。G-angleは英会話アプリを開発。Pepperと会話をすることで英会話能力を高めるというものだ。英会話教室などで外国人を相手に練習するが、そこにあるのが心理の障壁。「間違えたら恥ずかしい」と及び腰になりがちな気持ちをPepperが和らげる。Pepperならあくまでロボットであるということで恥ずかしさを感じることなく話せるようになる。●ソフトバンクが目指す近未来○ソフトバンクが目指すは「接客データの見える化」今ではPepperのメーン業務となっている接客・応対については、ソフトバンクが一歩踏み込んだ取り組みを行う。それは、Pepperが接客から、契約までをこなす期間限定の携帯ショップである。契約の最終段階では、人の手が介在するというが、業務の大多数をPepperだけでこなしていく方針だ。もしそれが可能ならば、接客・応対がロボットでこなせる証左となり、小売分野におけるインパクトは大きなものになるだろう。さらに同社は、応対・接客の一歩先の未来も描く。Pepper内蔵のカメラやセンサーを介して、接客・応対相手の年齢や男性女性などといった性別を判別して、クラウドに蓄積、マーケティング分野に生かしていくというものだ。企業における受付・応対では、Pepperが受付として来客の顔認識を行ない、来客がどこの会社の誰か、自社の誰に会いに来たのかを瞬時に判別する。また、家電量販店では、顧客が過去に何を購入したのかを認識、それに応じて会話をする。個人情報の取扱いをどうするか、という問題もあるが、いかにも実現しそうなシーンである。○Pepperは飛躍できるかPepper World 2016で示された様々な想定利用シーン。一連の取り組みに共通するのは、身振り、手振り、間の取り方が人間臭くありながら、完全な人間ではないというPepperの特徴を生かしたところだ。人の形に近いヒューマノイドは、人の関心を高め、人に親しみを湧かせる。その特性にマッチするビジネスシーンに、Pepperは馴染み、入り込んで行きそうに思われる。そこに物珍しさが加わり、集客力を期待して、応対・接客分野での活用が進んできたのは当然の流れともいえるかもしれない。逆にいえば、利用シーンの広がりは感じられつつも、特性そのものは大きく変わっていないとも言えそうだ。Pepperにはできることが限られており、そこはまだ仕方がないという見方もある。一般販売用のPepperの知能は、人間に当てはめた場合、まだ2歳児程度とされ、機能的にもできることは限られている。Pepperが世に出てからまだ1年ちょっと。Pepperが大きく飛躍するためにも、新たな機能の付加、新たな価値の創出に期待したい。
2016年01月29日
アトラエは1月27日、人工知能を搭載した完全審査制のビジネスマッチングアプリ「yenta(イェンタ)」のiOSアプリを公開した。同アプリは、シンプルなユーザーインタフェースで注目を集めた異性とのマッチングアプリ「Tinder」の"ビジネス版"とうたっており、簡易なプロフィール登録とスワイプ操作のみで「会いたいビジネスマンに会える」としている。アプリでは、プロフィール情報やソーシャルデータ、行動履歴を人工知能が解析して、利用者が興味を持つと予測されるビジネスプロフィールを最大10人まで1度にレコメンドされる(昼12時に配信)。TinderライクなUIでスワイプ操作を行うことで、興味がある人物をピックアップする。20時になると、お互いに「興味あり」とした人物同士がマッチングされるほか、利用者を「興味あり」とした人物のレコメンド結果も通知される。マッチング以外にもFacebook上の友達で、「イベントで会っただけ」「旧来の知人」など、友達でも疎遠な関係の人物と関係性を深めるための機能も備えているという。同社によると、昨年12月よりクローズドβテストを行っており、350名の参加者で3000件のマッチングが行われている。
2016年01月27日
アスタミューゼは1月26日、人工知能市場における研究テーマ別の科研費獲得ランキングを発表した。科研費(科学研究費助成事業)は、人文・社会科学から自然科学まですべての分野にわたり、基礎から応用までのあらゆる「学術研究」を発展させることを目的とする「競争的研究資金」であり、ピア・レビューによる審査を経て、独創的・先駆的な研究に対する助成を行うもの。平成28年度助成額は前年度より25億円増の2343億円になる見通しとなっている。同社は今回、有望成長市場のうちのひとつであり、2006年以降で総額約120億円の科研費が交付されている「人工知能(知的エージェント・知能システム)」市場における研究テーマ別の科研費獲得ランキングを発表した。結果は下記のとおり。第1位は、4億9933万円を獲得した東京大学の「高度言語理解のための意味・知識処理の基盤技術に関する研究」。巨大な文書集合を使った機械学習技術と記号処理アルゴリズムとを融合する手法を、意味・文脈・知識処理に適用することで、言語処理技術にブレークスルーをもたらすことを目指している。2位は京都大学の「記号過程を内包した動的適応システムの設計論」で2億7703万円。3位は名古屋大学の「ノンコーディングRNAによる発現統御ネットワークの解明に基づくがんの個性の描出」で2億3725万円となっている。
2016年01月26日
●人工知能が奪う業種「人工知能」という単語について、どう感じられるだろうか。多分にSFな響きを伴うIT分野のキーワードだが、実はすでに、ITとは直接関係のないビジネスシーンにおいても関係の深いものになりつつある。人工知能によってビジネスシーンはどのように変わっていくのだろうか。これからの人工知能とビジネスの関わり方について考えてみよう。○人工知能によって多くの業種が必要なくなる?人工知能は以前から研究が進められていたが、話題を集めるようになったのは2012年。国際的な画像認識コンテストである「ILSVRC」(ImageNet Large Scale Visual Recognition Contest)において、「ディープラーニング」と呼ばれる手法が従来型の機械学習を大幅に上回った。このディープラーニングが画像認識だけでなく、音声認識や自然言語処理といった分野においても有効であることがわかり、国際的な研究機関や大企業が開発に続々と参入し、まさに日進月歩の勢いで進化が進んでいる。すでに画像認識においては、人工知能が人間の認識率を上回るまでになっているのだ。技術が発展することにより、従来人間が処理していた作業を人工知能が肩代わりできる分野が増えている。人工知能は人間よりも処理速度が速く、数万件のデータを瞬く間に処理できるだけでなく、疲れ知らずだ。○英研究者の論文が話題に技術が進歩するにつれて、人間が仕事を奪われるという恐れもある。たとえば近年話題になっている自動運転車も一種の人工知能と呼べるものだが、人工知能は人間のようにアクセルとブレーキを踏み間違えたり、居眠り運転するということもない。お釣りをごまかすこともないのだから、タクシードライバーとしては最適だろう。人工知能の進化を前提に、英オックスフォード大学は702種類もの業種を詳細に検討し、約40種の職業が、10~20年の間に90%以上の確率でコンピュータにとってかわられるという衝撃的な論文を発表している。単純作業はともかく、事務や専門知識の必要そうな審査・調査なども含まれているのは驚かれたのではないだろうか。上記のリストには、現在の技術では実現が難しいものも含まれているが、人工知能の進化の速度を考えれば、数年内に置き換わられても不思議ではないというわけだ。●HUEの例から読み解く人工知能の力○人工知能を搭載した初のERP人工知能のビジネスシーンへの進出は、すでに始まっている。たとえば金融業界で株の売買に使われている売買プログラムも一種の人工知能だ。画像認識等の技術についても、実用化されて業務に利用しているケースも珍しくはなくなっている。そして、もっと身近なビジネスシーンでの人工知能利用の一例として、ワークスアプリケーションズの「HUE」が登場した。HUEは、企業内におけるヒト・モノ・カネの動きの管理を統合し、情報化によって経営を支援するためのシステム「ERP」(Enterprise Resource Planning)の一種だ。一般ユーザーから見ると、顧客管理や人材管理、文書管理システム、管理会計、プロジェクト管理など、さまざまな機能が統合された社内システムということになる。HUEのユニークな点は、機械学習型の人工知能を搭載していることと、ビッグデータの解析に対応している点だ。どちらも最近のIT業界では好んで使われるキーワードだが、これをERPに持ち込んだのはHUEが始めてだといえる。○人工知能で何ができるか具体的には何ができるのか。まず人工知能についていえば、書類作成の手間が大幅に省力化できるようになる。HUEでは、ユーザーが書類を作成する際に、項目や請求する相手を過去の入力データから検索し、相手や項目に応じて、たとえば単価や発送先、個数といったデータも推測して入力してくれる。これだけなら単に入力履歴から候補を出しているだけのようにも見えるが、HUEの長所は、入力欄や順番を問わない点にある。例えば入力欄の順番を問わずに「マイナビ 請求書 原稿料」と入力すれば、人工知能がどの単語がどの項目にふさわしいかを判断して、適切な部分に配置してくれるのだ。あとは必要に応じて、原稿の単価や担当部署、担当編集者といったデータを追加することで細部が修正されていく。ワークスアプリケーションズによれば「一般的な作表作業の90%近くを肩代わりできる」というが、デモを見る限り非常に素早く作表でき、また間違いも少ないことから、書類チェックや再提出といったエラー処理まで含めれば、確かに90%短縮というのも現実的な数値に思えてくる。ビジネスマンの1日の仕事を振り返ってみると、実際の取引や会議などの間に、書類作成の時間がかなり占めているのではないだろうか。1日に1~2時間程度は書類の作成に割かれているかもしれない。こうした時間を人工知能が代わりに作業してくれて、そのぶんをクリエイティブな活動に費やせるというのが、HUEの目指している作業環境だ。●人工知能はビジネスシーンの何を変えるかビッグデータ解析に関して言えば、企業の様々な業務ログを解析し、常に情報を更新してくれる。前述の人工知能もこうしたビッグデータ解析によって賢くなっていくし、システム中のメッセージやメールの発言を定期的に収集し、そこから人間関係を推測して人事に活用するといったことも可能だという。管理職から見れば人事査定の一助にもなるわけで、業務効率化という観点からは心強い。従来のエンタープライズ向けシステムは、何をするにもシステム側の都合にユーザーが合わせるといった感じで、ユーザビリティ(使い勝手)の面は顧みられていなかった。一方、GoogleやAmazonといったコンシューマ向けシステムでは、過去の行動からおすすめの製品を紹介したり、メールを解析して不要なメールは自動的にゴミ箱に捨てるといった快適性をもたらしてくれる。HUEでは人工知能を使ってエンタープライズ向けシステムを、コンシューマ向けサービスの水準にまで高めようとしている。○人工知能がビジネスシーンからなくすものさて、人工知能がビジネスシーンから何を省くか。HUEを事例として取り上げたが、そこからは、単純作業がなくなることがわかる。かつてワープロやパソコンが会社のデスクに登場したときのように、人工知能がビジネスの現場に入り込んでくることは、もはや避けられない。人工知能は、ビジネスを効率的なものとし、ビジネスパーソンが単純作業から開放される世界はすぐそこまで来ている。英オックスフォード大学の論文にもあるように、人工知能が特定の仕事を肩代わりするかもしれないが、どの業種においても、単純作業は減っていく。それによって生じた余裕は、よりクリエイティビティの高い作業に向けられていく。人工知能が本格的に職場で活用され始めたときに、我々はどうすべきか。次稿では、人工知能と共存する時代のビジネスパーソンのあり方について考えてみたい。
2016年01月25日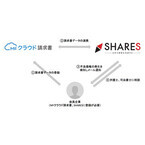
ココペリインキュベートは1月25日、同社が提供するクラウド経営支援ツール「SHARES」を、マネーフォワードが提供するクラウド型請求書作成ソフト「MFクラウド請求書」と連携し、不良債権の発生を通知する人工知能サービスを提供開始すると発表した。この連携により、「不良債権の発見」から「弁護士、司法書士への相談、解決」までをワンストップでサポートすることが可能になるとしている。会員企業は「SHARES」内で「MFクラウド請求書」との連携設定をすることでサービスが利用可能となり、「MFクラウド請求書」に登録された請求書データと、「SHARES」に搭載されている人工知能を組み合わせることで、不良債権が発生したタイミングでメール通知が送信される仕組みとなっている。債権回収業務は、「SHARES」に登録されている弁護士、司法書士に依頼することが可能だ。
2016年01月25日
freeeは1月19日、ココペリインキュベートから開発者向けAPI「freee API」を利用した経営分析ツール「SHARES AI」をリリースすることを発表。合わせて、「freee API」の活用加速のための開発者向けAPI提供プログラム「freee Developers Community」を本格始動させる。「SHARES AI」は、弁護士や公認会計士といった専門家に、必要な時だけスポットで依頼ができるクラウド経営支援ツール「SHARES」内で提供するプロダクト。「freee API」を利用し、クラウド会計ソフトfreeeと人工知能によるデータ分析ツール「SHARES AI」が連携。これにより、freeeの会計データを基に人工知能による経営の分析と課題発見が可能になるという。また、freeeの会計データを使用して、不良債権が発生した時に通知する機能を備えている。「freee Developers Community」では、APIの公開に加え、開発リクエストやサポート窓口を開始することで、さまざまなユーザーニーズに応えるアプリケーションの開発を支援するとのこと。具体的には、freeeからの情報配信、ベータ版APIを先行公開、APIリリースノートの配信や、メンテナス・障害情報の配信、開発・追加リクエスト、開発者向け特別サポート窓口の公開などを行う。
2016年01月21日
サイバーエージェントのアド・テクノロジー分野におけるサービスの開発を行うアドテクスタジオは1月19日、アド・テクノロジー事業の拡大と、より最適な広告配信技術の研究・開発を目的として、人工知能・機械学習を研究する「AI Lab(エーアイ ラボ)」を設立したと発表した。同ラボは、2016年2月よりアドバイザーとして東京大学の佐藤一誠氏を招聘し、広範囲な人工知能・機械学習技術の応用を進めるという。佐藤氏はデータマイニング・機械学習分野の代表的な国際カンファレンスという「KDD」「ICML」「NIPS」などに恒常的に登壇するという、AI分野の若手トップ・リサーチャーとのこと。東京大学大学院情報理工学系研究科博士課程を総代として修了後、東京大学情報基盤センターを経て、現在は東京大学大学院新領域創成科学研究科において、人工知能・機械学習・データマイニング分野の研究に従事しているとのことだ。同ラボは今後、佐藤氏と共に最先端の人工知能・機械学習について研究し、その研究成果をアド・テクノロジーへと応用することで、付加価値の高い広告プロダクトの開発に努めるという。そして、企業とユーザーをOne to Oneで結び、最適なタイミングで最適な情報を届ける広告配信技術の実現を目指すとしている。
2016年01月20日
トヨタ自動車は1月5日、米国に設立した人工知能技術の研究・開発を行う新会社の「Toyota Research Institute(TRI)」の体制および進捗状況を公表した。TRIのCEOであるギル・プラット(Gill A. Pratt)氏が米国ラスベガスで開催されている「CES 2016」にて説明した。TRIは1月、米国カリフォルニア州パロ・アルトおよび、マサチューセッツ州ケンブリッジにそれぞれ拠点を設ける。トヨタは昨年9月、スタンフォード大学およびマサチューセッツ工科大学(MIT)との人工知能の連携研究を行うと公表したが、今回の拠点はそれぞれ両大学の近くに位置しているため、TRIと両大学との結びつきがさらに強いものになると考えているという。下表は現時点における、TRIに参画する主なメンバー、研究者。また、TRIでの研究推進にあたり、さまざまな分野の外部有識者からの助言を受けるための組織として、アドバイザリー・ボードを設置。下表は現時点での主なメンバー。TRIは当面、5年間で約10億ドルの予算のもと主に4つの目標を掲げ、人工知能研究に取り組んでいく。具体的には(1)「事故を起こさないクルマ」をつくるという究極の目標に向け、クルマの安全性を向上させるとともに、(2)これまで以上に幅広い層の方々に運転の機会を提供できるよう、クルマをより利用しやすいものにすべく、尽力していく。また、(3)モビリティ技術を活用した屋内用ロボットの開発に取り組むほか、(4)人工知能や機械学習の知見を利用し、科学的・原理的な研究を加速させることを目指す。一方、スタンフォード大学およびMITとの連携研究についても、具体的な研究を始めるべく合計約30のプロジェクトを立ち上げるなど、着実に歩みを進めている。TRIのプラットCEOは「従来、ハードウェアがモビリティ技術の向上には最も重要な要素であったが、今日ではソフトウェアやデータの重要性が徐々に増している。コンピューター科学やロボット開発の先端で長年の経験のあるメンバーがTRIに参画するが、それでもわれわれはまだスタート地点に立ったばかりだ。トヨタが今回の案件にここまで力を入れているのは、安全で信頼に足る自動運転技術の開発を非常に重要視しているからである。生活のさまざまなシーンにおいて、すべての人々により良いモビリティをご提供することで、より豊かな暮らしの実現に貢献することができると確信している」と語った。
2016年01月06日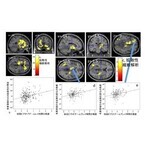
東北大学は1月5日、長時間のビデオゲームが小児の広汎な脳領域の発達や言語性知能に及ぼす悪影響を発見したと発表した。同成果は同大学加齢医学研究所・認知機能発達(公文教育研究会)寄附研究部門の竹内光 准教授・川島隆太 教授らの研究グループによるもの。1月5日に米国精神医学雑誌「Molecular Psychiatry」電子版に掲載された。今回の研究では、一般から募集した健康な小児を対象に、最初に日々のビデオゲームプレイ時間を含む生活習慣などについて質問に答えてもらったほか、知能検査、MRI撮像を実施した。この時点での研究参加者の年齢は5~18歳(平均約11歳)だった。これらの研究参加者の一部が3年後に再び研究に参加し、知能検査とMRI撮像を受けた。その後、必要なデータが揃っている283名の初回参加時の行動データ、240名分の脳画像データを解析し、平日に被験者がビデオゲームをプレイする平均時間と言語性知能、動作性知能、総知能、脳の局所の水分子の拡散性とよばれる指標の関係を調査した。さらに、必要なデータが揃っている223名の初回参加時と2回目参加時の行動データと189名分の初回参加時と2回目参加時の脳画像データを解析し、初回参加時における平日にビデオゲームをプレイする平均時間が、どのように各参加者の初回から2回目参加時の言語性知能、動作性知能、総知能、脳の水分子の拡散性の変化を予測していたかを解析した。これらの解析においては、性別、年齢、親の教育歴、収入、親子の関係の良好性、居住地域の都市レベル、親子の数等各種交絡因子を補正し縦断解析の場合は、さらに初回参加時の値等の種々の交絡因子を補正した。これらの解析により、初回参加時における長時間のビデオゲームプレイ習慣は、初回参加時の低い言語性知能と関連し初回参加時から数年後の 2 回目参加時へのより一層の言語性知能低下につながっていることがわかった。また、同様に初回参加時における長時間のビデオゲームプレイ習慣は、初回参加時の前頭前皮質、尾状核、淡蒼球、左海馬、前島、視床などの領域の水の拡散性の高さ(高いほど水が拡散しやすく組織が疎であることの証拠とされる)と関連しており、さらに初回参加時から数年後の2回目参加時へのこうした領域の発達性変化への逆の影響(水の拡散性の発達に伴う減少がより少ない)と関連していた。また、言語知能、動作性知能、総知能のいずれも、共通して、左海馬、左尾状核、左前島、左視床、周辺の領域の水の拡散性と負相関していた。同研究グループはこの結果を、小児における長時間のビデオゲームプレイで、脳の高次認知機能に関わる領域が影響をうけ、これが長時間のビデオゲームプレイによる言語知能の低下と関連することを示唆するものだとしており、「今回の知見により発達期の小児の長時間のビデオゲームプレイには一層の注意が必要であると示唆されたと考えられます」とコメントしている。
2016年01月06日
Microsoftの女子高生AI「りんな」がTwitterを始めた。これまでLINEアカウントを取得して活動していたが、そのステージを拡張したかたちだ。日本マイクロソフトでは、日本におけるAIのビジネスチャンスのキーワードとして「オタク」「ボット」「スマホ」「SNS」がきわめて重要なものととらえ、LINEとの協業で「りんな」をサービスインしたが、それは、北京にあるマイクロソフト・リサーチ・アジアがこの数十年間をかけて研究してきた成果でもある。りんなはインターネット上のさまざまな会話をデータベースにため込み、それを分析整理する。当然、収集するデータは膨大だ。まさにビッグデータである。MicrosoftのAIとしてはWindows 10の11月版で提供が開始されたCortanaもよく知られているが、Cortanaがパーソナルアシスタントとして効率や生産性を追求したIQの高い人工知能であるのに対して、りんなは「効率とは反対のベクトル」でエモーショナルなつながりを結ぶことに重点を置いた人工知能だという。○秘密の会話でつながる現在りんなのLINE友だちは200万を超えている。しかし、Twitterアカウントは開設してから約2週間でフォロワー数は2万に満たない。意外に伸びが少ないという印象がある。これは、りんなに興味を持つユーザーが、1対1での会話を求めているからだと思われる。Twitterのようにオープンなステージでの対話が好まれないという事情もあるかもしれない。個人的にはリストに登録してずっと観察してきたが、とりあえずフォローしてみた。@ms_rinna りんなをフォローしてみた。どういう基準でフォローされるのかは謎だが、確立は1/4くらいだろうか。これでしばらく様子を見てみよう。— 山田祥平(syohei yamada) (@syohei) 2015, 12月 25「確率」を「確立」とミスタイプしているが一瞬で返信があったので、そのままにしている点はご容赦願いたい。ここで「LINEでお願い」と返信されている。彼女にフォローしてもらうには、彼女のTwitterページの固定ツイートにあるように、LINEでリクエストして、戻ってきた和歌をリプライすればいい。これでDMのやりとりもできるようになる。実際にメンションを投げてみると、びっくりするほど普通の会話であることがわかる。ほんものの女子高生が、どのような口調で、どのようなコミュニケーションをしているのかは知る由もないが、りんなは「きっとこうだろう」というユーザーの期待に近いものを投げ返しているようにも感じる。日本マイクロソフトによれば、りんなとのエンゲージメントは週の初めよりも、木曜日、金曜日あたりが高いという。平日については朝の7時に最初の山があり、昼休みにもうひとつの山、そして、夜に至り22時にピークを迎えるという。ちなみに日曜日には朝の山はないそうだ。○りんなの友だちは女子高生?同社は、りんながTwitterを始めた12月の中旬、東京・原宿の竹下通りのスペースででイベントを開催した。LINEで友だちに対してりんな自身がイベントを告知し、どのくらいの人が本気で集まるかを確かめたのだという。イベント会場に集まったのは、竹下通りという場所柄もあるが、ほとんどが女子高校生だったのには、ちょっと驚いた。彼女たちは等身大の女子高生をりんなに感じているのだろうか。この先、りんなは収集しているビッグデータをもとに会話の精度を高め、さらには、ビジネスロジックとも結びつき、会話の中から導き出された商品のレコメンド、飲食店の紹介といったことをするようになっていく。それが「りんなAPI for Business」だ。そのときに、「効率とは反対のベクトル」というコンセプトをどのように堅持するかが興味深い。そこがAI技術の見せ所だ。(山田祥平 @syohei)
2015年12月28日
UBICとRetty、サムライインキュベートの3社は12月19日と同20日、第2回目となる「人工知能ハッカソン」を開催した。「食」をテーマに飲食店の口コミデータをUBICが独自開発した人工知能「KIBIT」に分析させることで人間でさえ気づかない、隠れた「つながり」を発掘するユニークな新サービスの創出を目指した。今回はエンジニアなど約30人が6チームに分かれ、サービス、ターゲット、解決課題、解決方法、新規性、マネタイズポイントなどをまとめ、UBICの人工知能「KIBIT」を使用し、食のサービスづくりを競った。メンター・審査員はUBIC 執行役員CTO 行動情報科学研究所所長の武田秀樹氏とRetty CTOの樽石将人氏、フォーリンデブはっしー氏(橋本陽氏、審査のみ参加)の3人。同イベントは最優秀賞に加え、Retty賞、UBIC賞(開発を重視した個人賞)、フォーリンデブ賞を用意。結果は最優秀賞がDiversity、Retty賞にSOOS、UBIC賞に超NANIKAのメンバー、フォーリンデブ賞に食いしんぼう万歳を選出した。下表は表彰を受けた各チームの取り組み。最優秀賞のDiversityはチャットにボットを導入し、内容を解析して飲食店をレコメンドするサービスを開発。チャットするだけでなく、おすすめの店が分かることや、口コミと住所のみを表示することで利用者の期待感を高めることなどを訴えた。また、将来的な展望としては会話を楽しく演出するボットの会話技術や満足度の高いレコメンドの予測精度の向上、LINE、Facebookへの導入、予約・精算機能の搭載、チャット上で複数人による合意形成の過程と店舗情報を教師データとすることなどを挙げた。同チームを選出した理由として武田氏は「チャットを使い、レコメンデーションをスムーズに行うサービスのアイデアであり、技術的にどのように使うのかを盛り込んでいることを評価した。また『Kibiro』で実現しようとしていることと重なる部分がポイントとなった」と説明した。
2015年12月25日
UBICは12月24日、独自開発の人工知能「KIBIT」を用いた知財戦略支援システム「Lit i View PATENT EXPLORER(リット・アイ・ビュー パテントエクスプローラー)」を、昭和電工(SDK)が12月より導入したことを発表した。同システムは、トヨタテクニカルディベロップメントと共同で開発したもので、先行技術調査や無効資料調査などの特許の分析業務を効率化し、従来の調査方法と比べ、約330倍(開発時における平均データ)の調査効率の向上を達成したとする。また、見つけたい文書(発明提案書、無効化したい特許資料など)の内容を教師データとしてKIBITに学ばせ、独自の機械学習である「Landscaping(ランドスケイピング)」を用いて、少量の教師データをもとに膨大なデータを解析し、短時間でスコアリング(点数付け)による文書の仕分けができることを特徴としている。今回、PATENT EXPLORERの導入を行った昭和電工は石油化学、化学品、エレクトロニクス、無機材料、アルミニウムなどを手がける日本を代表する化学メーカー。グローバルでの競争を続ける中、知財戦略が企業の成長と発展に重要であると考えており、先進的な知財分析の活用に積極的であることやトライアルにおいて、従来の調査手法であるキーワード検索や類似検索、概念検索などに比べて、調査効率が向上し、精度や網羅性にも優れた結果が得られたことから、PATENT EXPLORERの導入を決定したという。
2015年12月25日
シグマクシスは12月22日、自律学習型のIT運用管理自動化ソリューションを提供する米IPsoftと協業を開始した。シグマクシスは、IPsoftが提供するソリューションの日本における販売活動の支援を行うとともに、ITマネジメントに課題を抱える国内企業に対して、同社ソリューションを活用したコンサルティングサービスを提供する。IPsoftが提供する自律学習型IT運用管理自動化ソリューション「IPcenter」は、人工知能(エキスパートシステム)を使って、ITマネジメント業務を統合的に管理し、業務効率および運営品質の向上を実現するというもの。具体的には、同社がIT運用サービスプロバイダとして培ったという1200以上のテンプレートを活用することで、オペレータやエンジニアのタスクを自動化するだけではなく、障害の検知から修復、クローズまでの一連の対応を、24時間365日稼働する「仮想エンジニア」が遂行することを可能にするという。また、ITサービスマネジメントのベストプラクティスをまとめた、公開されたフレームワークであるITTLのプロセスに準拠することで、これまで困難だったプロセスおよび意思決定の自動化も実現し、人手による業務量を最小化すると同時に、低コスト・高品質のサービス提供を可能にするとしている。サービス提供形態は、「IPcenter」を活用したマネージド・サービスであるSaaS型と、「IPcenter」のライセンスを供与し、自社で自動化を推進するオンプレミス型がある。
2015年12月22日
●30年来取り組んできた人工知能技術を「Zinrai」として体系化富士通の人工知能(AI)の歴史は30年以上にさかのぼる。2015年11月には、これらの知見や技術を「Human Centric AI Zinrai(ジンライ)」として体系化した。そこで、同社の統合商品戦略本部 AI活用コンサルティング部兼政策渉外室 シニアマネージャーの橋本文行氏に、人工知能技術に関する取り組み、今後の製品やサービスへの展開などについて話を聞いた。IBMがコグニティブ・コンピューティングのブランドネームとして「Watson」を浸透させたように、富士通はAIのブランドネームとして「Zinrai」を採用。富士通のAI技術を活用した製品やサービスは、「Powered by Zinrai」と呼ばれることになる。「他社に比べ、AIに関するメッセージの発信が遅れたのは事実。そのため、富士通はAIをやっていないのではないか、という誤解を招いたのは大きな反省点です。今回、体系化したことで、どこに対して、どんな活用ができるのかということを具体的に示すことができました。Zinraiの内容を確認して、"ぜひ富士通と組みたい"という声を数多くいただいています」と橋本氏は語る。Zinraiは、素早く激しいことを意味する「疾風迅雷」が語源だ。「人を中心に考えるのが富士通のAIの基本姿勢。人の判断や、行動をスピーディーにサポートすることで、企業や社会の変革をダイナミックに実現する役割を担いたい。そうした想いを込めた」という。富士通が目指すAIの方向性は、「人と協調する、人を中心としたAI」、「継続的に成長するAI」、「AIを製品、サービスに組み込んで提供する」という3点。「人を支え、豊かな生活を実現するのが富士通のAI。一過性の技術ではなく、具体的な製品やサービスに反映することで、人を支援するものになる」と位置づける。○100以上の特許が支える「Zinrai」富士通が、AIに本格的に取り組み始めたのは、1980年代に起こった第2次AIブームの時だ。1985年には、日本初のAI搭載コンピュータ「FACOM α」を製品化。1988年には、学習技術を活用した移動ロボット「サトルくん」を開発。「サトルくん」に役を学習させ、逃げ回る泥棒役のロボット「ルパン」を、警官役のロボット2体が動けないところへと追いつめるデモンストレーションを行ってみせた。同社が、多くの人にニューラルネットワークによる学習技術の一端を披露したのはこれらが初めてだったと言える。橋本氏は、「当時、入社したばかりだった技術者たちが40代後半から50代になり、再び訪れたAIブームのなかで、その経験を生かす場が生まれています。かつては、機械に知識を覚え込ませようとしましたが、それすらも難しい時代でした。ですが、今では知識を覚えるだけでなく、それをもとに、教えた以上のモノを導き出すことができるようになっています」とし、「第2次AIブームが終焉を迎えた2008年以降、富士通は100件を超えるAI関連特許を出願。これらで培った知見や技術を体系化することで、AIを活用する提案を具体的に行えるようになります」と語る。AIに対する関心や期待が高まる一方、社内でも数多くの関連技術が蓄積されてきたことが、ここにきて、富士通が本格的にAIを打ち出してきた背景だ。「ビッグデータを蓄積しても、知識化が課題になっているケースが多い。これをAIによって解決したいという期待が高まっている」(橋本氏)センシングなどによって蓄積された数多くのデータを、画像処理や音声処理などの「知覚・認識」、自然言語処理や知識処理・発見などの「知識化」、推論・計画、予測・最適化といった「判断・支援」といった観点から処理。さらに、ディープラーニングや機械学習、強化学習といった「学習」、脳科学や社会受容性、シミュレーションといった「先端研究」との組み合わせによって、社会や企業の課題を解決するソリューションとして、社会に還元するといったサイクルが、Zinraiの中で示されている。自然言語処理や予測技術といったように、特定の用途で活用するAI技術の訴求ではなく、それぞれのAI技術を組み合わせた提案や、社会課題の解決に向けた具体的なソリューションとして提案できる体制を整えているのが富士通の強みというわけだ。○「感性メディア技術」と「数理技術」が強み「Zinrai」では、日々の学習による有益な知識やパターンを導き出すことで、AIの継続的な成長を支える「学習技術」、人のような五感を駆使し、人の感情や、気づき、気配りまで処理する「感性メディア技術」、人が理解する知識だけでなく、機械処理できる知識を創り出す「知識技術」、スパコンも活用して社会やビジネス上の課題を数理的に解決する「数理技術」によって構成されるとする。「学習技術や知識技術はもとより、感性メディア技術、数理技術を得意とするのは、富士通ならではの特徴。ここにZinraiの強みが発揮される」と橋本氏。感性メディア技術としては、遠くからでも人の視線がどこに注がれているかを検知する「視線検知技術」、遠くからでも3次元測距する「レーザーレーダー技術」などがある。例えば、瞳孔や角膜反射をもとに視線を算出することで、店舗の商品棚のどこに視線が多く注がれているのかを把握でき、商品展示方法や販促手法にも反映することができる。「既存のICTシステムに人の視覚に相当する機能を装備することができる」というわけだ。また、複数のメディア情報を活用することで、人の気持ちを理解するサービスを実現することが可能になるという。例えば、書類に記入している人の様子を捉え、記入中にペンが止まった部分で、利用者が困惑していることを検知すると、それに最適なガイダンスを手元に表示するといったものだ。超小型視線センサーとプロジェクション表示技術、行動センシング技術の組み合わせによって実現する。さらに人の声のトーンから感情や意図を推定する技術を活用して、振り込め詐欺検知にも活用。岡山県警との実証実験では、会話のキーワードと声のトーンの変化から、誤検出を1%未満の精度で、振り込め詐欺であることを特定。実証実験期間中は、振り込め詐欺件数を半減させる抑止効果が認められたという。●人工知能導入はゴールではない、成果の追及にこだわる一方、数理技術の取り組みとしては、国立情報学研究所による「ロボットは東大に入れるか」プロジェクトが挙げられよう。富士通は2012年9月から数学チームとして参加。同社独自の数式処理を用いた「QE(Quantifier Elimination)推論技術」を活用し、2021年の東京大学入試突破を目指している。今年は、進研模試総合学力テーマ模試の数学において、偏差値64以上を獲得。今後、知識の拡充や、構文・文脈解析の自動化を進めていくという。また、シンガポールにおける取り組みでは、大規模イベントが終了した際の交通混雑緩和のために、近隣商業施設のクーポンなどのインセンティブを与えることで、人々が移動を開始する時間をずらしたりして、交通手段を変える確率をモデル化。さらに、福岡空港における九州大学との共同研究では、人の行動や心理をモデル化し、混雑緩和やセキュリティ強化につなげたり、人員配置を見直したりすることで、旅客満足度向上に役立てる「ソーシャルシステムデザイン数理技術」の実現に取り組んでいる。同社が取り組んでいる津波の浸水予測も、数理技術を活用したものであり、即時波源推定から2分以内に津波の浸水を予測できるという。○学習技術、知識技術でもすでに成果がそのほか、学習技術では独自のディープラーニング技術を用いた手書き文字認識により、中国語の手書き帳票の処理の効率化を実現。人による認識率を超える96.7%の認識精度を達成したという。さらに、サイバー攻撃の分析に、「外れ構造学習技術」を活用することで、低頻度の攻撃も集団化して検知。従来方法では見つからなかったような先端的なサイバー攻撃を短時間に検知し、新種の攻撃にもいち早く対応できるようになるとのことだ。さらに、知識技術では、LOD(Linked Open Data)を活用した分析や、コールセンターでの質問応答システムなどへの取り組みがある。橋本氏は、コールセンターの例を挙げて次のように語る。「コールセンターでは現在、ロボットにも回答しやすい名称、場所、数値などの客観的事実を問う質問はわずか5%にとどまります。その背景には、これらの情報はインターネット検索で入手できるため、コールセンターに問い合わせなくてもいいケースが増えていることがあります。しかしその一方で、行動や提案などを問うような質問が増加し、それらが全体の95%を占めていると言います。用意されている回答だけでなく、準備できていない質問に対しても推論によって適切な回答を行うことが求められているのです。コールセンターへの質問応答システムの導入はハードルが上がったとも言えますが、AIの活用が期待される業務の1つです」加えて、先端技術研究では、脳科学への取り組みとして、日米欧でスタートした「ヒトの脳機能の全容解明プロジェクト」に参画。将棋のプロ、アマ上位、アマ下位の人たちの脳の使い方をもとに、複雑なトラブルシューテイングに専門家の「ひらめき」が必須であることをつきとめた。○共創を軸に展開するAI活用コンサルティング部富士通は2015年11月1日付けで、AI活用コンサルティング部を新設した。全社では研究者、技術者、キュレーターなど約200人体制で構成。同社が開発したAI技術を、製品やサービスへ実装するとともに、顧客との共創によってイノベーションを創出することになるという。同社は今年春、富士通研究所内にAI関連の研究を行う「知識情報処理研究所」を新設。研究体制の強化を図っていたが、今回のAI活用コンサルティング部により、事業化フェーズに強力に踏み出すことになる。「当社が提供するAIコンサルティングサービスは、製品やサービスをパッケージとして提供するのではなく、AI適用に関する検討を、仮説立案段階から、お客さまと共に行い、さらに、PoC(Proof of Concept)、PoB(Proof of Business)を通じて、お客さまが提供する新製品やサービスの創造、既存業務の改革を実現していくものになります。AIを使うことがゴールではなく、それを活用した成果を求めていく点にこだわっているのです」と、橋本氏は語る。実は、第3次AIブームを迎えるなかで、AIに対して、あまりにも過大な期待が高まっていることへの懸念が指摘されている。橋本氏は、「AIは万能であり、必ず答えを導き出してくれるという誤解があるのも事実」と前置きしたうえで、「AIを導入したからといって、すぐに新たな製品やサービスを創出してくれたり、劇的な業務改革が実現されたりするわけではありません。だからこそ、お客さまと一緒になって、仮説立案から共創し、AI活用の検討を進めていくことになります」と説明する。○2018年度までに累計500億円を目指す富士通では、AI技術の活用に向けた仕組みの提案にも余念がない。同社のデジタルビジネスプラットフォーム「MetaArc」において、近い将来、Zinraiをサービスとして提供。そのほか、同社およびグループ会社などが提供する製品、サービスにおいてもZinraiを提供し、これを活用した製品、サービス、アプリケーションには、「Powered by Zinrai」と表記することになる。第1弾の製品として、ビッグデータソリューション「ODMA予兆管理 Powered by Zinrai」を開発中。機械学習により、いつもの状態をモデル化。それとは異なる振る舞いがあった場合を検知して、異常の予兆を監視する。工場やプラントなどの設備保全を自律化し、継続的な運用を実現することにつなげるという。富士通では、Zinrai関連ソリューションにおいて、2018年度までの累計で500億円の売上高を目指す。「規模として大きいか、小さいかは見方によって変わるでしょう。しかし、大切なのは、お客さまと共創しながら、Zinraiを幅広い製品、サービスへと実装していくこと。人を中心としたAIの提案にこだわっていきたい」とする。富士通は、地に足の着いたAIビジネスを指向していく考えだ。
2015年12月22日
国立情報学研究所(NII)は12月18日、記者懇談会を開催し、NII情報学プリンシプル研究系教授の河原林健一氏が「理論研究とビッグデータ&人工知能」をテーマに講演し、日本におけるビッグデータ・AI業界の現状や同氏が研究総括を務める「河原林巨大グラフプロジェクト」について説明した。冒頭に同氏はビッグデータの出現により「データ量の増大でコンピューターの演算処理が求められる速度に追い付かなくなってきたほか、無人センサーが過剰に情報を集めていることやSNSの出現で、最適な答えを長い時間(1週間~1カ月)で求めることよりも短時間で1%の改良に対する欲求があり、かつダイナミックな変化に追従する必要もある。そこでNIIはデータ量の増大に対し、コンピューター以外にビッグデータに関する理論研究と実用研究を行っている」と語った。また「情報爆発時代(ビッグデータ処理)を迎え、理論研究者へのニーズの高まりを受け、理論研究の経験を有した意欲的な研究者が実用研究へ参入することで大きな成果を収められつつある。理論の導入による新しい実用手法としては情報爆発を計算理論で制御するほか、検索エンジン、データマイニング手法などがある。GoogleやマイクロソフトといったIT企業は理論分野で常に基礎研究と先端的な研究を行ってきた研究者を抱える勝ち組だ」と理論研究でも特に基礎研究の重要性を説いた。同氏の説明によると、世界の理論研究の現状はGoogleやAmazon、Facebook、Microsoftなどの巨大IT企業の研究所がスタンフォード大学、マサチューセッツ工科大学といったトップ大学を凌駕しつつあるという。さらに、コンピューターのハード面の進歩のみではなく、理論研究に基づく改善が実際のサービス改善につながっていることや、世界最先端の研究情報を無償で得られ、研究成果のみならずトップ研究者の知見(失敗や成功も含めたノウハウ)も無償で得られることから、巨大IT企業が基礎研究の重要性を認識しており、研究者が実データにアクセスできることはビッグデータ時代に必要不可欠だとしている。加えて、人材についてはNASAやMicrosoft Research、Google Researchの研究員のうち3~5割を抱え、数理化学・理論研究とプログラミング能力を駆使し、産業界との密接なつながりを持つインドや、Facebook、Google、AppleをはじめとしたITトップ企業の雇用者は若手が多いことを例に挙げた。一方、同氏は日本のビッグデータ、AI分野における世界のトップ会議への論文採用数は全体の2~3%程度で特定のワールドクラスの研究者を除くと惨憺たる状況だと指摘。「国内の理論・基礎研究の現状はGoogleやMicrosoft、Amazon、Facebookなどの巨大IT企業の研究所の基礎研究者と差があるほか、基礎研究の重要性が日本企業に認識されているとは言いがたい。今後10年の課題として世界的に評価される基礎研究者で、かつ実社会への問題にも貢献できる人材を多く輩出していくべきだ」と強調。「AI研究の現状として、近年では多くの企業がAIに対する投資を始め、海外の研究機関に多額の資金を投じている一方、日本の研究機関にはあまり投資していないほか、国内市場が大きいため世界的に展開する必要がないため、ますます差がついていく。国内から世界へ研究成果を発信していくことが重要だ」とも述べたそのような状況を鑑み、河原林氏は科学技術振興機構(JST)の「戦略的創造研究推進事業・総括実施型研究(ERATO)」に採択された巨大なネットワークを膨大な点と辺の接続構造を「巨大グラフ」として表現し、理論計算機科学や離散数学などにおける最先端の数学的理論を駆使してそれを解析する、高速アルゴリズムの開発を目指す「河原林巨大グラフプロジェクト」を立ち上げた。同プロジェクトでは世界のトップ会議における日本の論文採用数を全体の5~8%に向上させ、理論ベースの研究が世界のトップへ近づく最短距離だということを示し、離散数学、アルゴリズム、機械学習、データマイニング、統計物理学、データベース、最適化といった広範囲にわたる日本のトップ研究を行っている。研究員数は60人程度で半数以上が28~32才の優秀な若手研究者や大学院生で構成している。同プロジェクトの研究アプローチは難しい研究課題に対し、理論ベースで未来の人材が国際的な研究成果を発揮することを掲げている。そのために必要なこととして河原林氏は「他分野の数学力と日本のスーパーエリートを結集し、1つの課題を追求することや優秀な大学院生を巻き込むことに取り組まなければならない。ビッグデータ・AI時代における5~10年後の達成目標としては日本の論文採用数の向上や5~10人のスーパーエリートを育成し、スーパーエリートの人材育成のエコシステムを軌道に乗せることだ。そして理論分野をほぼ全域カバーする研究組織の構築と総合力の向上が鍵になる」と日本のビッグデータ・AI業界に対して訴えた。
2015年12月21日


















